朴素贝叶斯毫无疑问是对贝叶斯统计方法的朴素解释为基础。尽管存在朴素的一面,但是,这种方法应用的很广泛且都取得了不错的效果。特征类型和形式多种多样的数据集也是用这种方法进行分类。
- 贝叶斯定理
- 朴素贝叶斯算法
- 算法应用示例
贝叶斯定理
首先,要明白贝叶斯统计方式与统计学中的频率概念是不同,从频率的角度出发,即假定数据遵循某种分布,我们的目标是确定该分布的几个参数,在某个固定的环境一下做模型。而贝叶斯则是根据实际的推理方式来建模。我们拿到的数据,来更新模型对某事件即将发生的可能性的预测结果。在贝叶斯统计学中,我们使用数据来描述模型,而不是使用模型来描述数据。
贝叶斯定理旨在计算P(A|B)的值,也就是在已知B发生的条件下,A发生的概率是多少。大多数情况下,B是被观察事件,比如“昨天下雨了”,A为预测结果“今天会下雨”。对数据挖掘来说,B通常是观察样本个体,A为被预测个体所属类别。所以,说简单一点,贝叶斯就是计算的是:B是A类别的概率。
贝叶斯公式:
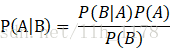
举例说明,我们想计算含有单词drugs的邮件为垃圾邮件的概率。
在这里,A为“这是封垃圾邮件”。我们先来计算P(A),它也被称为先验概率,计算方法是,统计训练中的垃圾邮件的比例,如果我们的数据集每100封邮件有30封垃圾邮件,P(A)为30/100=0.3。
B表示“该封邮件含有单词drugs”。类似地,我们可以通过计算数据集中含有单词drugs的邮件数P(B)。如果每100封邮件有10封包含有drugs,那么P(B)就为10/100=0.1。
P(B|A)指的是垃圾邮件中含有的单词drugs的概率,计算起来也很容易,如果30封邮件中有6封含有drugs,那么P(B|A)的概率为6/30=0.2。
现在,就可以根据贝叶斯定理计算出P(A|B),得到含有drugs的邮件为垃圾邮件的概率。把上面的每一项带入前面的贝叶斯公式,得到结果为0.6。这表明如果邮件中含有drugs这个词,那么该邮件为垃圾邮件的概率为60%。
朴素贝叶斯
其实,通过上面的例子我们可以知道它能计算个体从属于给定类别的概率。因此,他能用来分类。
我们用C表示某种类别,用D代表数据集中的一篇文档,来计算贝叶斯公式所要用到的各种统计量,对于不好计算的,做出朴素假设,简化计算。
P(C)为某一类别的概率,可以从训练集中计算得到。
P(D)为某一文档的概率,它牵扯到很多特征,计算很难,但是,可以这样理解,当在计算文档属于哪一类别时,对于所有类别来说,每一篇文档都是独立重复事件,P(D)相同,因此根本不用计算它。稍后看怎样处理它。
P(D|C)为文档D属于C类的概率,由于D包含很多特征,计算起来很难,这时朴素贝叶斯就派上用场了,我们朴素地假定各个特征是互相独立的,分别计算每个特征(D1、D2、D3等)在给定类别的概率,再求他们的积。
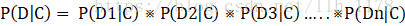
上式右侧对于二值特征相对比较容易计算。直接在数据集中进行统计,就能得到所有特征的概率值。
相反,如果我们不做朴素的假设,就要计算每个类别不同特征之间的相关性。这些计算很难完成,如果没有大量的数据或足够的语言分析模型是不可能完成的。
到这里,算法就很明确了。对于每个类别,我们都要计算P(C|D),忽略P(D)项。概率较高的那个类别即为分类结果。
算法应用示例
下面举例说明下计算过程,假如数据集中有以下一条用二值特征表示的数据:[1,0,0,1]。
训练集中有75%的数据集属于类别0,25%属于类别1,且每一个特征属于每个类别的概率为:
类别0:[0.3, 0.4, 0.4, 0.7]
类别1:[0.7, 0.3, 0.4, 0.9]
注:上述类别中的小数表示有多少概率该特征为1,例如0.3表示有30%的数据,特征1的值为1。
我们来计算一下这条数据属于类别0的概率。类别为0时,P(C=0) = 0.75。
朴素贝叶斯算法不用P(D),因此我们不用计算它。
P(D|C=0) = P(D1|C=0) * P(D2|C=0) * P(D3|C=0) * P(D4|C=0)
= 0.3 * 0.6 * 0.6 * 0.7
= 0.0756
现在我们就可以计算该条数据从属于每个类别的概率。
P(C=0|D) = P(C=0) * P(D|C=0)
= 0.75 * 0.0756
= 0.0567
接着计算类别1的概率,方法同上。可以得到
P(C=1|D) = 0.06615
由此可以推断这条数据应该分到类别1中。以上就是朴素贝叶斯的全部计算过程。还有一点应该注意,通常, P(C=0|D) + P(C=1|D) 应该等于1。然而在上述中并不是等于1,这是因为我们在计算中省去了公式中的P(D)项。
补充:
上述只考虑了二值特征属性(离散属性)的情况,但是,在实际情况中也会遇上非离散属性而是连续属性的情况,这时就该用概率密度函数来计算条件概率P(x|c)。μ(c,i)和 σ(c,i)^2分别是第c类样本在第i个属性上取值的均值和方差。则有:

同时,对于朴素贝叶斯还需要说明的一点是:若某种属性值在训练集中没有与某个类同时出现过,则直接基于概率估计公式得出来概率为0,再通过各个属性概率连乘式计算出的概率也为0,这就导致没有办法进行分类了,所以,为了避免属性携带的信息被训练集未出现的属性值“抹去”,在估计概率值时通常要进行“平滑”,常用“拉普拉斯修正”,具体来讲,令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数。
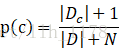
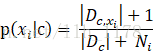
拉普拉斯修正避免了样本不充分而导致概率估计为零的问题,并且在训练集样本变大的时候,修正过程所引入的先验的影响也会逐渐变得可忽视,使得估计值越来越接近实际概率值。
参考:《python数据挖掘入门与实践》