本文同步于微信公众号:3D视觉前沿,欢迎大家关注。
本期带来上周在arXiv公开的相关论文共5篇,其中涉及6D物体位姿估计等,这里只是给出大致简介,详细了解可阅读原文。
一、6D物体位姿估计:
1. [IROS] Deep Keypoint-Based Camera Pose Estimation with Geometric Constraints
- 作者机构:You-Yi Jau, et al. University of California, San Diego
- 论文地址:https://arxiv.org/pdf/2007.15122.pdf
- 论文代码:https://github.com/eric-yyjau/pytorch-deepFEPE
- 简介:从连续帧估计相机的相对位姿是视觉里程计(VO)和实时定位与建图(SLAM)的基本问题。过去十年中的主流方法,仍然是传统的使用手工特征和基于采样的异常值剔除方法。尽管有许多工作提出用基于学习的方法代替这些模块,但大多数方法不如传统方法那样准确、鲁棒且泛化性强。在本文中,作者设计了一个端到端的可训练框架,该框架由特征点检测、特征提取、匹配和离群值剔除的可学习模块组成,能够直接针对几何姿态目标进行优化。作者在定量和定性上都展示了,姿态估计的性能可以与经典框架相提并论。此外,作者展示了通过端到端的训练,框架的关键模块可以得到显着改善,与现有的基于学习的方法相比,它可以更好地扩展到未见过的数据集。

2. [ECCV] GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
- 作者机构:Lei Ke, et al. HKUST & Kwai Inc
- 论文地址:https://arxiv.org/pdf/2007.13124.pdf
- 论文代码:http://www.kelei.site/gsnet/
- 简介:作者提出了一个名为GSNet(几何和场景感知网络)的端到端框架,该框架能够从单幅城市街道图像中,同时估计车辆的6DoF位姿以及精细的3D形状。GSNet采用了一种独特的四通道特征提取和融合方案,并在一次前馈过程中直接回归6DoF姿态和形状。大量实验表明,提出的多样化的特征提取和融合方案可以大大提高模型性能。基于分而治之的3D形状表示策略,GSNet可以非常详细地重建车辆的3D形状(1352个顶点和2700个面)。这种稠密的网格表示进一步使我们考虑了几何一致性和场景上下文,并激发了新的多目标损失函数来规范化网络训练,从而提高了6D位姿估计的准确性,并验证了联合执行这两项任务的优点。作者在最大的多任务数据集ApolloCar3D上评估了GSNet,实验表明定性和定量结果都达到了当前最优。

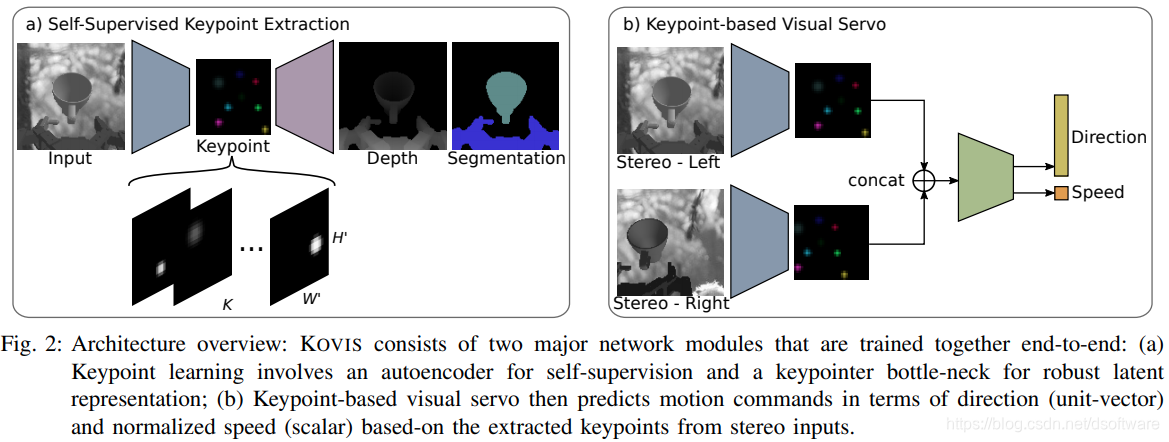
3. [IROS] KOVIS: Keypoint-based Visual Servoing with Zero-Shot Sim-to-Real Transfer for Robotics Manipulation
- 作者机构:En Yen Puang, et al. A*STAR, Singapore
- 论文地址:https://arxiv.org/pdf/2007.13960.pdf
- 简介:作者提出了一种基于学习的、无需校准的视觉伺服方法-KOVIS,它适用于基于眼在手上立体相机系统的精细机器人操纵任务。作者仅在仿真环境中训练深度神经网络,而训练后的模型可以直接用于现实世界中的视觉伺服任务。KOVIS由两个网络组成:第一个关键点网络使用自动编码器从图像中学习关键点表示;第二个视觉伺服网络基于从相机图像中提取的关键点学习抓手的运动。这两个网络通过自我监督学习在模拟环境中进行端到端训练,而无需人工标注数据。使用数据增强、领域随机化和对抗性示例进行训练后,作者能够实现零样本从模拟到真实世界的转移,完成现实世界中的机器人操纵任务。作者在模拟环境和真实世界中的不同机器人操纵任务上验证了方法的有效性,这些任务包括抓取、将M13螺钉插入间隙为4mm的孔中。
4. [IROS] se(3)-TrackNet: Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
- 作者机构:Bowen Wen, et al. Rutgers University in Piscataway
- 论文地址:https://arxiv.org/pdf/2007.13866.pdf
- 论文代码:https://github.com/wenbowen123/iros20-6d-pose-tracking
- 简介:跟踪视频序列中物体的6D位姿对于机器人操纵非常重要。然而,该任务具有多个挑战:(i)机器人操纵场景涉及大量的遮挡;(ii)6D位姿数据集的构建和标注很困难;(iii)长时间跟踪带来的累积误差漂移,要求必须重新初始化物体的位姿。这篇论文针对长时间物体的6D位姿跟踪,提出了一种数据驱动的优化方法。它旨在根据当前的RGB-D观测数据以及由上一帧最佳预测位姿得到的合成图像,确定最佳的相对位姿变换。该论文的关键贡献是一种解耦的特征编码方式以减少域偏移,以及一种基于李代数的3D朝向表示。即使仅使用合成数据训练网络,也可以在真实图像上有效地工作。全面的实验在多个基准数据集上进行,包括已有的数据集以及与物体操纵相关的带有显著遮挡的新数据集,结果表明,即使其他方法采用了真实图像进行训练,所提出的方法仍可实现连续的鲁棒估计并优于其他方法。该方法在对比方法中也是计算效率最高的,实现了90.9Hz的跟踪频率。

5. [ECCV] Solving the Blind Perspective-n-Point Problem End-To-End With Robust Differentiable Geometric Optimization
- 作者机构:Dylan Campbell, et al. Australian National University
- 论文地址:https://arxiv.org/pdf/2007.14628.pdf
- 代码地址:https://github.com/Liumouliu/Deep_blind_PnP
- 简介:Blind PnP问题是指,给定2D图像和3D场景点云,在不知道2D-3D对应的情况下,估计摄像机相对于场景的位置和方向。由于搜索空间很大,同时估计相机位姿与对应关系非常困难。幸运的是,这是一个耦合的问题:通过对应关系可以轻松得到相机位姿,反之亦然。现有方法假定提供了带噪声的对应关系,可以用来获得一个不错的先验位姿,或者问题的规模很小。相反,作者提出了第一个完全端到端的可训练网络,可以在无需先验位姿的情况下,高效、全局地解决blind PnP问题。作者使用了一些用以区分优化问题的结果,用以将几何模型拟合,纳入端到端的学习框架,包括Sinkhorn、RANSAC和PnP算法。提出方法在合成数据和真实数据上的实验结果明显优于其他方法。
