定序回归
什么是定序回归?
定序回归的因变量是定序变量,数据类型是顺序数据。比如不满意,一般,满意;不合格,合格,优秀等。
假设因变量是评分,先由单变量回归说起,则普通的线性回归模型为
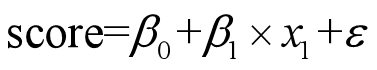
由于方程右边的普通线性回归,是连续性变量,方程左边是因变量分数,取值为1,2,3,4,5。左右两边数据类型不同,不能进行回归。我们考虑引入连续变量Z。先让Z进行普通线性回归。
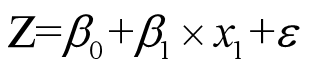
则Z和评分之间的关系如下:

综上可得:
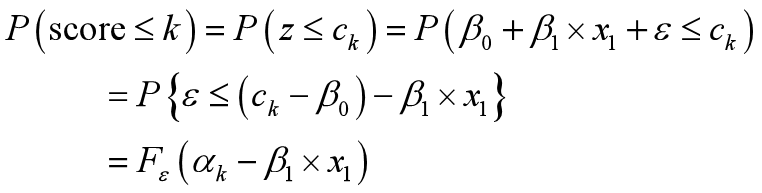
所以得到:
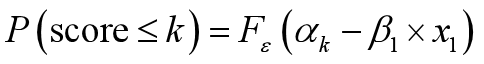
对于不同的k有不同的截距
Probit模型和Logit模型


用极大似然法进行参数估计
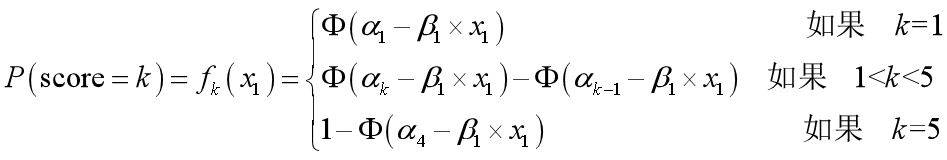
苹果实体店客户满意度案例分析
描述分析
先浏览下数据第一条数据为因变量满意度,因变量包含产品等产品的一些数据。

再看一下数据描述:

可视化
先看一下满意度和产品product的关系

可以看出,分数为10分的占比最多,其中Accessary和ipod占比最多。其余看不出明显的差别。各产品类别的评分还是有较大差别。
下面看一下Knowledgeable与满意度之间的关系

模型建立
用plor函数建模

还可以将Hess设置为T
直接附上R语言代码啦~需要数据可以找我私聊。
library(pROC)
library(MASS)
data = read.csv("F:\\learning_kecheng\\huigui\\10广义线性回归\\Apple.csv",header = TRUE)
head(data)
summary(data)
attach(data)
countproduct<- table(满意度,product)
spineplot(countproduct, main="product满意度")
plot(c(0,10),c(0,10),type="n",xlab="score",ylab="Percentage",main="Digital Camera")
points(c(0:10),tapply(Knowledgeable ,满意度,mean),type="b")
pos=polr(factor(满意度)~product+Timely.Assistance+Personal.Attention+Knowledgeable+Clear.Purchase.Process
+Efficient.Checkout+Friendly...Welcoming,method="probit")
summary(pos)
pos=polr(as.factor(满意度)~product+Timely.Assistance+Personal.Attention+Knowledgeable+Clear.Purchase.Process
+Efficient.Checkout+Friendly...Welcoming,method="probit",Hess = T)
summary(pos)
POS1 = step(pos,trace = F)
Summary(POS1)