Home Credit Default Risk
结论
数据由Home Credit(中文名:捷信)提供,Home Credit致力于向无银行账户的人群提供信贷。任务要求预测客户是否偿还贷款或遇到困难。使用AUC(ROC)作为模型的评估标准。
本篇博客只对 application_train/application_test的数据进行分析,使用Logistic Regression进行分类预测。通过grid search调节超参数能够得到 public board 0.749,private board 0.748的成绩。而Baseline是0.68810,最好成绩能到0.79857,剩余部分在进阶篇。
背景知识
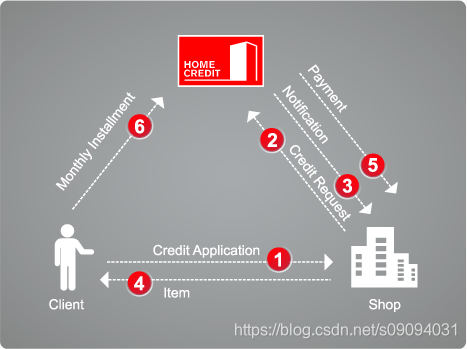
Home Credit (捷信)是中东欧以及亚洲领先的消费金融提供商之一。在中东欧(CEE),俄罗斯,独联体国家(CIS)和亚洲各地服务于消费者。
查询用户在征信机构的历史征信记录可以用来作为风险评估的参考,但是征信数据往往不全,因为这些人本身就很少有银行记录。数据集中bureau.csv和 bureau_balance.csv 对应这部分数据。
Home Credit有三类产品,信用卡,POS(消费贷),现金贷。信用卡在欧洲和美国很流行,但在以上这些国家并非如此。所以数据集中信用卡数据偏少。POS只能买东西,现金贷可以得到现金。三类产品都有申请和还款记录。数据集中previous_application.csv, POS_CASH_BALANCE.csv,credit_card_balance.csv,installments_payment.csv对应这部分数据。
三类产品的英文分别是:Revolving loan (credit card),Consumer installment loan (Point of sales loan – POS loan),Installment cash loan。
数据集
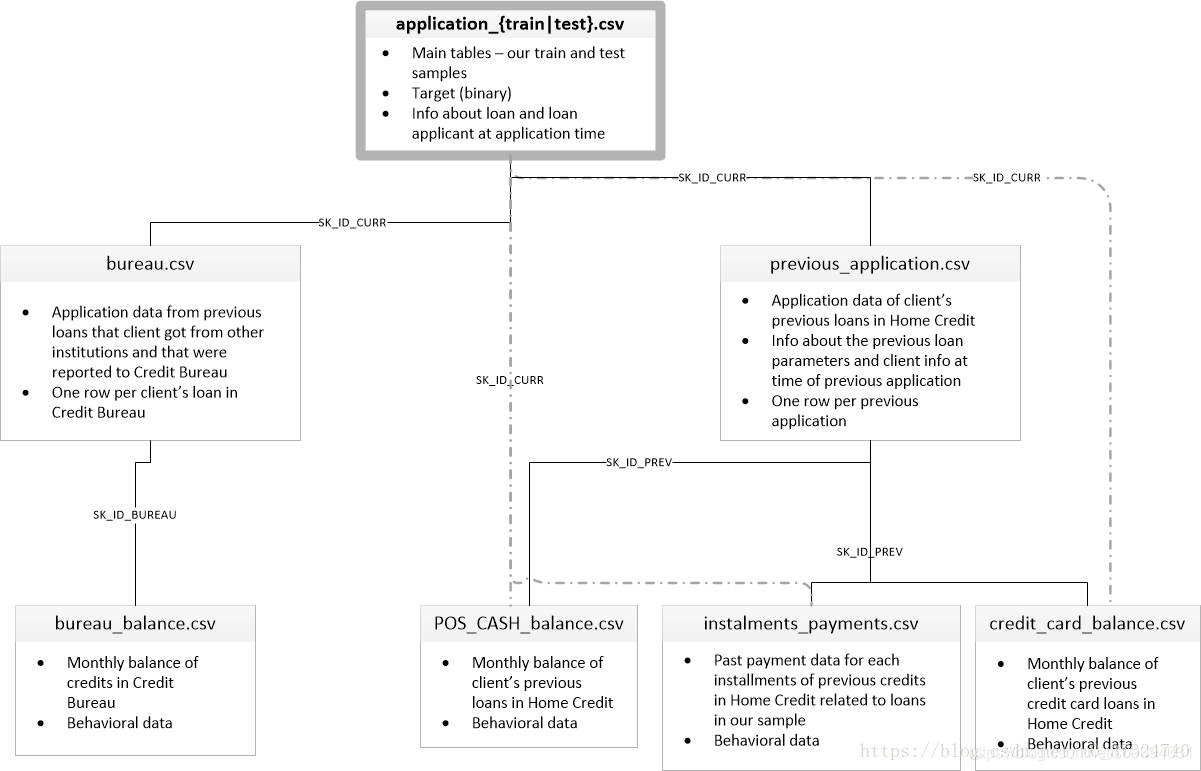
根据上面的介绍,数据集包括了8个不同的数据文件,就可以分为三大类。
-
application_train, application_test:
训练集包括Home Credit每个贷款申请的信息。每笔贷款都有自己的行,并由SK_ID_CURR标识。训练集的TARGET 0:贷款已还清,1:贷款未还清。
通过这两个文件,就能对这个任务做基本的数据分析和建模,也是本篇博客的内容。 -
bureau, bureau_balance:
这两个文件是征信机构提供的,用户在其他金融机构的贷款申请数据,以及每个月的还款欠款记录。一个用户(SK_ID_CURR)可以有多笔贷款申请数据(SK_ID_BUREAU)。 -
previous_application, POS_CASH_BALANCE,credit_card_balance,installments_payment
这四个文件来自Home Credit。用户可能已经在Home Credit 使用过POS服务,信用卡,和申请贷款。这些文件就是相关申请数据和还款记录。一个用户(SK_ID_CURR)可以有多笔历史数据(SK_ID_PREV)。
下图显示了所有数据是如何相关的,通过三个ID将三部分数据联系起来,SK_ID_CURR,SK_ID_BUREAU和SK_ID_PREV。
数据分析
平衡度
从application_train和application_test中读取数据。训练集中一共307511条数据,122个特征。其中违约(Target = 1)的数量为24825,没有违约(Target = 0)的数量282686,imbalance不算严重。
# -*- coding: utf-8 -*-
##307511, 122, 30万数据,28万0, 2万1,这个imbalance不算严重
app_train = pd.read_csv('input/application_train.csv')
app_test = pd.read_csv('input/application_test.csv')
print('training data shape is', app_train.shape)
print(app_train['TARGET'].value_counts())
training data shape is (307511, 122)
0 282686
1 24825
Name: TARGET, dtype: int64
数据缺失
122个特征中,67个特征有缺失,其中49个数据缺失超过47%。
## 67个特征有缺失,49个数据缺失超过47%, 其中47个与住房特征有关,是否可以将这个住房特征用PCA降阶。看其他人如何处理。
## 剩下ext_source 和 own_car_age。或者这49个特征可以尝试删除。
mv = app_train.isnull().sum().sort_values()
mv = mv[mv>0]
mv_rate = mv/len(app_train)
mv_df = pd.DataFrame({'mv':mv, 'mv_rate':mv_rate})
print('number of features with more than 47% missing', len(mv_rate[mv_rate>0.47]))
mv_rate[mv_rate> 0.47]
number of features with more than 47% missing 49
EMERGENCYSTATE_MODE 0.473983
TOTALAREA_MODE 0.482685
YEARS_BEGINEXPLUATATION_MODE 0.487810
YEARS_BEGINEXPLUATATION_AVG 0.487810
YEARS_BEGINEXPLUATATION_MEDI 0.487810
FLOORSMAX_AVG 0.497608
FLOORSMAX_MEDI 0.497608
FLOORSMAX_MODE 0.497608
HOUSETYPE_MODE 0.501761
LIVINGAREA_AVG 0.501933
LIVINGAREA_MODE 0.501933
LIVINGAREA_MEDI 0.501933
ENTRANCES_AVG 0.503488
ENTRANCES_MODE 0.503488
ENTRANCES_MEDI 0.503488
APARTMENTS_MEDI 0.507497
APARTMENTS_AVG 0.507497
APARTMENTS_MODE 0.507497
WALLSMATERIAL_MODE 0.508408
ELEVATORS_MEDI 0.532960
ELEVATORS_AVG 0.532960
ELEVATORS_MODE 0.532960
NONLIVINGAREA_MODE 0.551792
NONLIVINGAREA_AVG 0.551792
NONLIVINGAREA_MEDI 0.551792
EXT_SOURCE_1 0.563811
BASEMENTAREA_MODE 0.585160
BASEMENTAREA_AVG 0.585160
BASEMENTAREA_MEDI 0.585160
LANDAREA_MEDI 0.593767
LANDAREA_AVG 0.593767
LANDAREA_MODE 0.593767
OWN_CAR_AGE 0.659908
YEARS_BUILD_MODE 0.664978
YEARS_BUILD_AVG 0.664978
YEARS_BUILD_MEDI 0.664978
FLOORSMIN_AVG 0.678486
FLOORSMIN_MODE 0.678486
FLOORSMIN_MEDI 0.678486
LIVINGAPARTMENTS_AVG 0.683550
LIVINGAPARTMENTS_MODE 0.683550
LIVINGAPARTMENTS_MEDI 0.683550
FONDKAPREMONT_MODE 0.683862
NONLIVINGAPARTMENTS_AVG 0.694330
NONLIVINGAPARTMENTS_MEDI 0.694330
NONLIVINGAPARTMENTS_MODE 0.694330
COMMONAREA_MODE 0.698723
COMMONAREA_AVG 0.698723
COMMONAREA_MEDI 0.698723
dtype: float64
数据类型
122个特征中,65个 浮点类型,41 整型类型,16个非数据特征。对非数据类型特征画图分析其与Target的关系。OCCUPATION_TYPE 和 ORGANIZATION_TYPE可以手动进行数值编码,其余的直接用Onehot encoding。
## 65 浮点,41 整型,16个非数据特征,除了OCCUPATION_TYPE 和 ORGANIZATION_TYPE 其余应该都可以手动编码
categorical = [col for col in app_train.columns if app_train[col].dtypes == 'object']
ct = app_train[categorical].nunique().sort_values()
for col in categorical:
if (col!='OCCUPATION_TYPE') & (col!='ORGANIZATION_TYPE'):
plt.figure(figsize = [10,10])
sns.barplot(y = app_train[col], x = app_train['TARGET'])
# 对特征数为2的特征编码, nunique 和 len(unique)是不一样的,前者不计算null,后者会计算null
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
count = 0
for col in categorical:
if len(app_train[col].unique()) == 2:
count = count + 1
lb.fit(app_train[col])
app_train['o' + col] = lb.transform(app_train[col])
app_test['o' + col] = lb.transform(app_test[col])
# housing type mode, family status的逾期率和分类有一定关系。
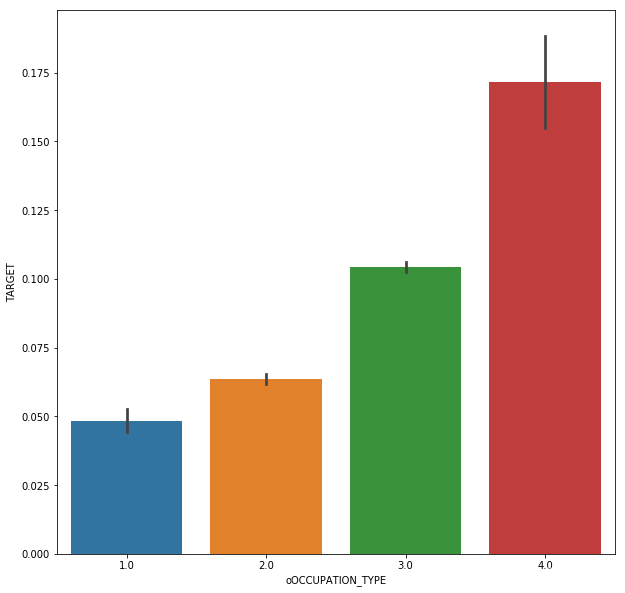
# OCCUPATION可以按以下编码
col = 'OCCUPATION_TYPE'
#occ_sort = app_train.groupby(['OCCUPATION_TYPE'])['TARGET'].agg(['mean','count']).sort_values(by = 'mean')
#order1 = list(occ_sort.index)
#plt.figure(figsize = [10,10])
#sns.barplot(y = app_train[col], x = app_train['TARGET'], order = order1)
dict1 = {'Accountants' : 1,
'High skill tech staff':2, 'Managers':2, 'Core staff':2,
'HR staff' : 2,'IT staff': 2, 'Private service staff': 2, 'Medicine staff': 2,
'Secretaries': 2,'Realty agents': 2,
'Cleaning staff': 3, 'Sales staff': 3, 'Cooking staff': 3,'Laborers': 3,
'Security staff': 3, 'Waiters/barmen staff': 3,'Drivers': 3,
'Low-skill Laborers': 4}
app_train['oOCCUPATION_TYPE'] = app_train['OCCUPATION_TYPE'].map(dict1)
app_test['oOCCUPATION_TYPE'] = app_test['OCCUPATION_TYPE'].map(dict1)
plt.figure(figsize = [10,10])
sns.barplot(x = app_train['oOCCUPATION_TYPE'], y = app_train['TARGET'])
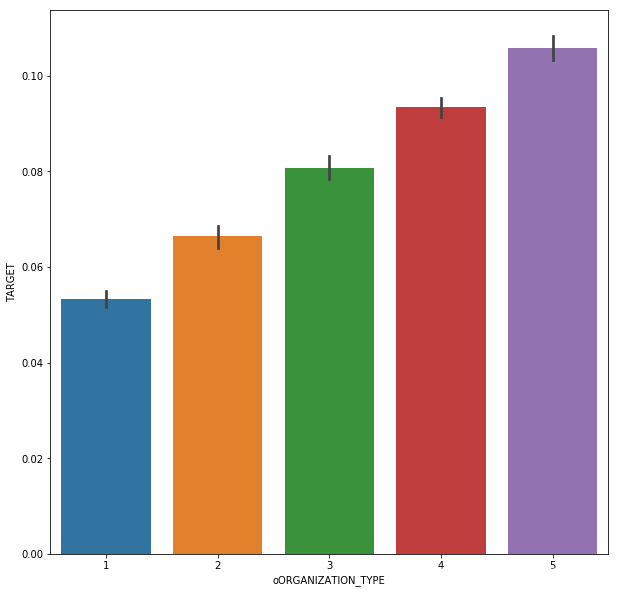
##
col = 'ORGANIZATION_TYPE'
#organ_sort = app_train.groupby(['ORGANIZATION_TYPE'])['TARGET'].agg(['mean','count']).sort_values(by = 'mean')
#order1 = list(organ_sort.index)
#plt.figure(figsize = [20,20])
#sns.barplot(y = app_train[col], x = app_train['TARGET'], order = order1)
dict1 = {'Trade: type 4' :1, 'Industry: type 12' :1, 'Transport: type 1' :1, 'Trade: type 6' :1,
'Security Ministries' :1, 'University' :1, 'Police' :1, 'Military' :1, 'Bank' :1, 'XNA' :1,
'Culture' :2, 'Insurance' :2, 'Religion' :2, 'School' :2, 'Trade: type 5' :2, 'Hotel' :2, 'Industry: type 10' :2,
'Medicine' :2, 'Services' :2, 'Electricity' :2, 'Industry: type 9' :2, 'Industry: type 5' :2, 'Government' :2,
'Trade: type 2' :2, 'Kindergarten' :2, 'Emergency' :2, 'Industry: type 6' :2, 'Industry: type 2' :2, 'Telecom' :2,
'Other' :3, 'Transport: type 2' :3, 'Legal Services' :3, 'Housing' :3, 'Industry: type 7' :3, 'Business Entity Type 1' :3,
'Advertising' :3, 'Postal':3, 'Business Entity Type 2' :3, 'Industry: type 11' :3, 'Trade: type 1' :3, 'Mobile' :3,
'Transport: type 4' :4, 'Business Entity Type 3' :4, 'Trade: type 7' :4, 'Security' :4, 'Industry: type 4' :4,
'Self-employed' :5, 'Trade: type 3' :5, 'Agriculture' :5, 'Realtor' :5, 'Industry: type 3' :5, 'Industry: type 1' :5,
'Cleaning' :5, 'Construction' :5, 'Restaurant' :5, 'Industry: type 8' :5, 'Industry: type 13' :5, 'Transport: type 3' :5}
app_train['oORGANIZATION_TYPE'] = app_train['ORGANIZATION_TYPE'].map(dict1)
app_test['oORGANIZATION_TYPE'] = app_test['ORGANIZATION_TYPE'].map(dict1)
plt.figure(figsize = [10,10])
sns.barplot(x = app_train['oORGANIZATION_TYPE'], y = app_train['TARGET'])
## 只对这几种进行ordinary编码吧,剩下的用ohe(307511, 127),(48744, 126) drop之后,feature分别为 122,121
discard_features = ['ORGANIZATION_TYPE', 'OCCUPATION_TYPE','FLAG_OWN_CAR','FLAG_OWN_REALTY','NAME_CONTRACT_TYPE']
app_train.drop(discard_features,axis = 1, inplace = True)
app_test.drop(discard_features,axis = 1, inplace = True)
# 然后使用 get_dummies(307511, 169) (48744, 165)
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)
# 有些特征 test里面没有,需要对齐 (307511, 166)(48744, 165)
train_labels = app_train['TARGET']
app_train, app_test = app_train.align(app_test, join = 'inner', axis = 1)
app_train['TARGET'] = train_labels
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 169)
Testing Features shape: (48744, 165)
Training Features shape: (307511, 166)
Testing Features shape: (48744, 165)
离群值
在特征DAYS_EMPLOYED 里面发现有不正常数据,而这个特征与Target的相关性很强,需要特殊处理。另外增加一个特征,DAYS_EMPLOYED_ANOM,来表征这个特征是否不正常。这种处理应该是对线性方法比较有效,而基于树的方法应该可以自动识别。
## 继续EDA, 在DAYS_EMPLOYED 里面发现有问题数据,这种处理应该是对线性方法有效,boost方法应该可以自动识别。
app_train['DAYS_EMPLOYED'].plot.hist(title = 'DAYS_EMPLOYMENT HISTOGRAM')
app_test['DAYS_EMPLOYED'].plot.hist(title = 'DAYS_EMPLOYMENT HISTOGRAM')
app_train['DAYS_EMPLOYED_ANOM'] = app_train['DAYS_EMPLOYED'] == 365243
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
app_test['DAYS_EMPLOYED_ANOM'] = app_test["DAYS_EMPLOYED"] == 365243
app_test["DAYS_EMPLOYED"].replace({365243: np.nan}, inplace = True)
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment')
## 提取相关性
correlations = app_train.corr()['TARGET'].sort_values()
print('Most Positive Correlations:\n', correlations.tail(15))
print('\nMost Negative Correlations:\n', correlations.head(15))
Most Positive Correlations:
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
oORGANIZATION_TYPE 0.070121
DAYS_EMPLOYED 0.074958
oOCCUPATION_TYPE 0.077514
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
Most Negative Correlations:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
DAYS_EMPLOYED_ANOM -0.045987
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
ELEVATORS_AVG -0.034199
Name: TARGET, dtype: float64
填充缺失值
## 特征工程
## 填充缺失值
from sklearn.preprocessing import Imputer, MinMaxScaler
imputer = Imputer(strategy = 'median')
scaler = MinMaxScaler(feature_range = [0,1])
train = app_train.drop(columns = ['TARGET'])
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(app_test)
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
D:\Anaconda3\lib\site-packages\sklearn\utils\deprecation.py:66: DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead.
warnings.warn(msg, category=DeprecationWarning)
Training data shape: (307511, 166)
Testing data shape: (48744, 166)
建模
Logistic Regression
使用逻辑回归来建模,使用grid search搜索最佳参数,结果显示 ‘C’ = 1, ‘Penalty’ = 'l1’的时候,性能最好。
##
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
param_grid = {'C' : [0.01,0.1,1,10,100],
'penalty' : ['l1','l2']}
log_reg = LogisticRegression()
grid_search = GridSearchCV(log_reg, param_grid, scoring = 'roc_auc', cv = 5)
grid_search.fit(train, train_labels)
# Train on the training data
log_reg_best = grid_search.best_estimator_
log_reg_pred = log_reg_best.predict_proba(test)[:, 1]
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
submit.head()
submit.to_csv('log_reg_baseline_gridsearch2.csv', index = False)
最后的结果
public board 0.73889
private board 0.73469
LightGBM
folds = KFold(n_splits= num_folds, shuffle=True, random_state=1001)
# Create arrays and dataframes to store results
oof_preds = np.zeros(train_df.shape[0])
sub_preds = np.zeros(test_df.shape[0])
feature_importance_df = pd.DataFrame()
feats = [f for f in train_df.columns if f not in ['TARGET','SK_ID_CURR','SK_ID_BUREAU','SK_ID_PREV','index']]
for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_df[feats], train_df['TARGET'])):
train_x, train_y = train_df[feats].iloc[train_idx], train_df['TARGET'].iloc[train_idx]
valid_x, valid_y = train_df[feats].iloc[valid_idx], train_df['TARGET'].iloc[valid_idx]
# LightGBM parameters found by Bayesian optimization
clf = LGBMClassifier(
nthread=4,
n_estimators=10000,
learning_rate=0.02,
num_leaves=34,
colsample_bytree=0.9497036,
subsample=0.8715623,
max_depth=8,
reg_alpha=0.041545473,
reg_lambda=0.0735294,
min_split_gain=0.0222415,
min_child_weight=39.3259775,
silent=-1,
verbose=-1, )
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)],
eval_metric= 'auc', verbose= 200, early_stopping_rounds= 200)
oof_preds[valid_idx] = clf.predict_proba(valid_x, num_iteration=clf.best_iteration_)[:, 1]
sub_preds += clf.predict_proba(test_df[feats], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = feats
fold_importance_df["importance"] = clf.feature_importances_
fold_importance_df["fold"] = n_fold + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(valid_y, oof_preds[valid_idx])))
del clf, train_x, train_y, valid_x, valid_y
gc.collect()
print('Full AUC score %.6f' % roc_auc_score(train_df['TARGET'], oof_preds))
private board 0.74847
public board0.74981
Feature importance

附录:各字段的意义
| 字段 | 含义 |
|---|---|
| SK_ID_CURR | 此次申请的ID |
| TARGET | 申请人本次申请的还款风险:1-风险较高;0-风险较低 |
| NAME_CONTRACT_TYPE | 贷款类型:cash(现金)还是revolving(周转金,一次申请,多次循环提取) |
| CODE_GENDER | 申请人性别 |
| FLAG_OWN_CAR | 申请人是否有车 |
| FLAG_OWN_REALTY | 申请人是否有房 |
| CNT_CHILDREN | 申请人子女个数 |
| AMT_INCOME_TOTAL | 申请人收入状况 |
| AMT_CREDIT | 此次申请的贷款金额 |
| AMT_ANNUITY | 贷款年金 |
| AMT_GOODS_PRICE | 如果是消费贷款,改字段表示商品的实际价格 |
| NAME_TYPE_SUITE | 申请人此次申请的陪同人员 |
| NAME_INCOME_TYPE | 申请人收入类型 |
| NAME_EDUCATION_TYPE | 申请人受教育程度 |
| NAME_FAMILY_STATUS | 申请人婚姻状况 |
| NAME_HOUSING_TYPE | 申请人居住状况(租房,已购房,和父母一起住等) |
| REGION_POPULATION_RELATIVE | 申请人居住地人口密度,已标准化 |
| DAYS_BIRTH | 申请人出生日(距离申请当日的天数,负值) |
| DAYS_EMPLOYED | 申请人当前工作的工作年限(距离申请当日的天数,负值) |
| DAYS_REGISTRATION | 申请人最近一次修改注册信息的时间(距离申请当日的天数,负值) |
| DAYS_ID_PUBLISH | 申请人最近一次修改申请贷款的身份证明文件的时间(距离申请当日的天数,负值) |
| FLAG_MOBIL | 申请人是否提供个人电话(1-yes,0-no) |
| FLAG_EMP_PHONE | 申请人是否提供家庭电话(1-yes,0-no) |
| FLAG_WORK_PHONE | 申请人是否提供工作电话(1-yes,0-no) |
| FLAG_CONT_MOBILE | 申请人个人电话是否能拨通(1-yes,0-no) |
| FLAG_EMAIL | 申请人是否提供电子邮箱(1-yes,0-no) |
| OCCUPATION_TYPE | 申请人职务 |
| REGION_RATING_CLIENT | 本公司对申请人居住区域的评分等级(1,2,3) |
| REGION_RATING_CLIENT_W_CITY | 在考虑所在城市的情况下,本公司对申请人居住区域的评分等级(1,2,3) |
| WEEKDAY_APPR_PROCESS_START | 申请人发起申请日是星期几 |
| HOUR_APPR_PROCESS_START | 申请人发起申请的hour |
| REG_REGION_NOT_LIVE_REGION | 申请人提供的的永久地址和联系地址是否匹配(1-不匹配,2-匹配,区域级别的) |
| REG_REGION_NOT_WORK_REGION | 申请人提供的的永久地址和工作地址是否匹配(1-不匹配,2-匹配,区域级别的) |
| LIVE_REGION_NOT_WORK_REGION | 申请人提供的的联系地址和工作地址是否匹配(1-不匹配,2-匹配,区域级别的) |
| REG_CITY_NOT_LIVE_CITY | 申请人提供的的永久地址和联系地址是否匹配(1-不匹配,2-匹配,城市级别的) |
| REG_CITY_NOT_WORK_CITY | 申请人提供的的永久地址和工作地址是否匹配(1-不匹配,2-匹配,城市级别的) |
| LIVE_CITY_NOT_WORK_CITY | 申请人提供的的联系地址和工作地址是否匹配(1-不匹配,2-匹配,城市级别的) |
| ORGANIZATION_TYPE | 申请人工作所属组织类型 |
| EXT_SOURCE_1 | 外部数据源1的标准化评分 |
| EXT_SOURCE_2 | 外部数据源2的标准化评分 |
| EXT_SOURCE_3 | 外部数据源3的标准化评分 |
| APARTMENTS_AVG <----> EMERGENCYSTATE_MODE | 申请人居住环境各项指标的标准化评分 |
| OBS_30_CNT_SOCIAL_CIRC LE <----> DEF_60_CNT_SOCIAL_CIRCLE | 这部分字段含义没看懂 |
| DAYS_LAST_PHONE_CHANGE | 申请人最近一次修改手机号码的时间(距离申请当日的天数,负值) |
| FLAG_DOCUMENT_2 <----> FLAG_DOCUMENT_21 | 申请人是否额外提供了文件2,3,4. . .21 |
| AMT_REQ_CREDIT_BUREAU_HOUR | 申请人发起申请前1个小时以内,被查询征信的次数 |
| AMT_REQ_CREDIT_BUREAU_DAY | 申请人发起申请前一天以内,被查询征信的次数 |
| AMT_REQ_CREDIT_BUREAU_WEEK | 申请人发起申请前一周以内,被查询征信的次数 |
| AMT_REQ_CREDIT_BUREAU_MONTH | 申请人发起申请前一个月以内,被查询征信的次数 |
| AMT_REQ_CREDIT_BUREAU_QRT | 申请人发起申请前一个季度以内,被查询征信的次数 |
| AMT_REQ_CREDIT_BUREAU_YEAR | 申请人发起申请前一年以内,被查询征信的次数 |
从表中就可以大致猜测出一些信息,例如:OCCUPATION_TYPE,NAME_INCOME_TYPE以及ORGANIZATION_TYPE应该有很强的线性相关性;DAYS_LAST_PHONE_CHANGE,HOUR_APPR_PROCESS_START等信息可能不是重要的特征;可以在后面的特征分析时加以验证并采取特定的降维手段