范涛
发表于2017-03-31
第四章:Scorecard Development Process, Stage 2: Data Review and Project Parameters
一: data avaliablity and quality
数据获取,数量和质量,可靠和干净的数据是需要的。数据数量需要满足多样性,统计显著和随机。具体数量大小,目前不是关键,依赖坏样本定义。对于申请评分卡(application scorecard),俗称A卡,需要包含拒绝的样本。通过拒绝推断(reject inference)技术去推断拒绝样本中好样本和坏样本。数据源的获取:内部数据和外部数据, 高质量内部数据需要处理,外部数据需要评估,量化和定义。重要一点是,个人建议: 数据源稳定性要监控,模型开发要考虑到源数据延时和缺失的情况。
二: Data Gathering for Definition of Project Parameters
对于申请评分卡来说,需要收集之前2到5年的样本数据,或者大量足够的样本。相关字段(包括但不局限):(1)身份id; (2)申请日期; (3)账号拖欠和索赔历史数据; (4)接受/拒绝 标记; (5)产品/通道,或者其他标识符; (6)当前账号状态(e.g., 不活跃,关闭,丢失,被盗,欺诈等)
对于行为评分卡(behavior scorecard)来说,俗称B卡,账户选择是在一个时间点上,对他们的行为分析,通常以6到12个月为周期。
3.1 Exclusions评分卡模型有时候需要过滤掉一些特定账号样本。开发涉及的账号样本是应该是应用到潜在用户,日常贷款针对的人群。对一些异常表现群体,如欺诈群体。还有员工,vip,国外,盗卡,未成年这些群体,是不能加入开发模型,需要采用一些特殊规则进行处理。对于一些金融公司如果之前客户涉及比较多,比如一家汽车贷款公司,之前贷款业务包括个人汽车业务,驾驶技术业务等,如果现在业务聚焦到个人汽车贷款业务,那他评分卡开发涉及的样本则需要改变,只能包含个人汽车贷款用户样本。对于exclusion的另外一个理解,这些exclusions可以看成一种sample bias 案例。比如你开发评分卡模型只针对城市人口,那你开发样本中则不能包含任何非城市人口。总体来说,如果一个群体或者申请类型,在未来应用上是不会被评分的,那这些样本是不应该加入模型开发中的。
3.2 Performance and Sample Windows and “Bad” Definition ( 表现窗口,样本窗口,以及坏样本定义)评分卡模型是基于这样一个假设“未来的表现将反映过去的表现" 。所以,我们在收集样本时候,需要考虑一个具体时间点开户的账户,同时监控他们另外一个具体时间段表现,来确定这些样本是好的还是坏的。开发样本数据包含了样本变量和样本目标标签。“perfomance window”(表现窗口)定义:为了确定 账户分类(好的还是坏的)而监控账户行为的时间窗口。“sample window”(样本窗口)定义:选取已经确定好坏分类标签的开发样本的时间点。表现窗口在样本窗口之后。
如何确定样本窗口和表现窗口,常见的方法是vintage analysis。通过观察不同表现窗口,观察不良率曲线是否达到稳定。一般选取达到稳定期的时间窗。
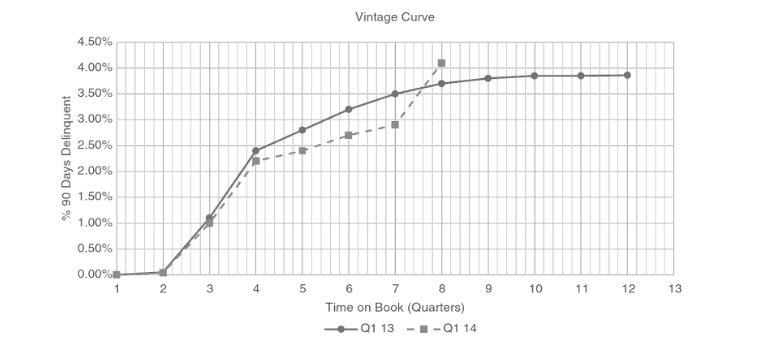
“ever bad”define:对于表现窗口期内任何时间点达到预先定义好的不良状态,则账户分类为坏样本。
“current”define:只考虑最近最后一个月的不良状态。
下面是一个账号24个月的不良历史行为记录,delq行代表逾期月数。如果采用“ever bad”define方法,这个账户分类为3个月不良状态,如果采用“current”define方法,这个账号被分类为无不良状态。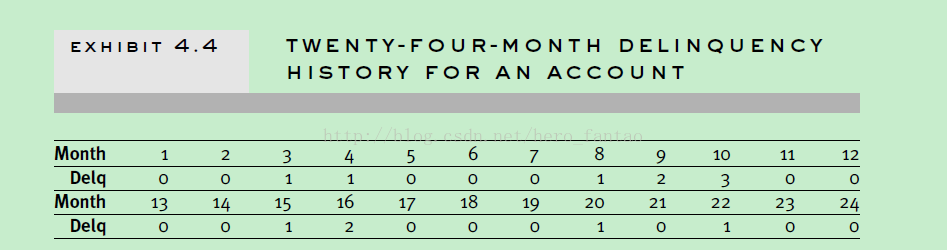
3.3 Effects of Seasonality
样本选择时候需要考虑季节性影响。我们的开发样本不应该包含异常时间段样本, 我们开发样本应该和正常商业时间段保持一致。这样能保证之前的假设“未来和过去是相似的”,也能确保模型的预测准确性和鲁棒性。如何过滤异常时间段样本? 一种常见的方法,通过比较用户特征平均属性和样本窗口开发样本特征属性。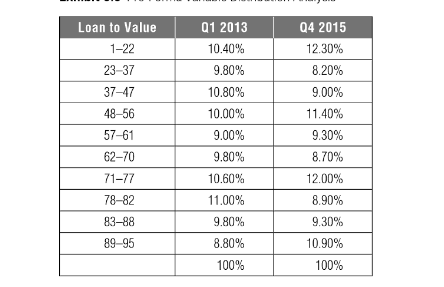
举个例子: 一个公司期望他们的信用卡申请者主要是成年的男士和女士,但是他们发现样本窗口中有一个月样本主要年轻人。这种情况是那个月有一个汽车展。针对这种情况,需要扩大样本窗口,来平滑特征时间段的影响。还有一种处理方式,就是过滤异常时间段样本。比如一个公司确定他未来针对的客户不会包括年轻女性,那么开发样本中就可以过滤掉年轻女性样本。季节性影响,也可以通过采取多样本窗口,固定表现窗口的的方法来处理。
3.4 Definition of “Bad”
如何定义账户表现是否是坏样本? 破产,欺诈行为是一种相对直接的坏账户 定义 方式,但不是唯一方式。如果按照不良率方式定义的话,这里会涉及到根据不同不良等级的多种选择。
对于坏账户的定义,会有如下的考虑:
(1)需要和公司目标保持一致;
(2)需要和产品或者评分卡针对的目标保持一致;
(3)如果是设置相对严谨的定义,比如120+天不良率,准确率会相对较高,但是样本量会减少;
(4)如果设置相对宽松的定义,比如30天不良率,样本会很多,但是准确率会降低,好坏样本的区分度不够强,评分卡模型会变弱;
(5)定义必须好解释和追踪;
(6) 针对同一公司,不同场景的评分卡,使用相对统一定义,是相对有益,这样方便管理。
(7) 有时需要遵守一些国家规定或者官方组织约定的定义方式;
常见的确定定义,采用滚动率分析( Roll Rate Analysis )和 当前和历史最坏比较分析(Current versus Worst Delinquency Comparison)
"Roll Rate Analysis" : 滚动率分析主要分析比如30天不良行为账户中有多少比率转化成60天不良 行为 账户,60天不良 行为 账户多少比率转化为90天不良 行为 账户等等。比如下面中可以发现,对于30天不良 行为 账户有13%率转化成更长时间不良 行为 账户。通过滚动率分析,主要确定多长时间不良行为的账户大多数会成为最终的坏账户。通过最短的表现窗口来捕获绝大多数坏账户样本。

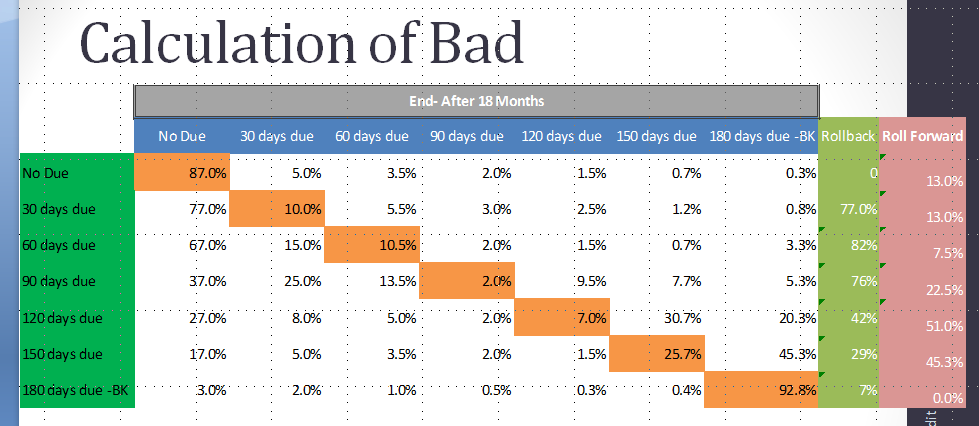
Current versus Worst Delinquency Comparison: 其实和滚动率分析很相似,但是相对容易执行。分析账户历史最坏不良状态和最近不良状态,进行比较。从下面图可以,看到历史30天不良行为账户,84%最近都没有不良行为,相反90天历史不良账户60%最近都保持90天不良行为或者更长时间不良行为。和滚动分析类似,这种方法,也是为了确定多长时间不良行为的账户大多数会成为最终的坏账户。

3.5 “Good” and “Indeterminate”
好样本定义和中间不确定样本定义。
Good 好样本特性可能:(1)无不良行为或者不良行为前向滚动率低于10%(前向滚动率: 比如30天不良行为向60天不良行为转化率)。(2)盈利的,正向NPV;(3)无索赔; (4)无破产;(5)无欺诈;Indeterminate: 指那些没有落入bad和good类目中的账户样本。这样账户没有足够多的表现历史或者有不良行为但是滚动率比较低(比如有30天不良行为,但是没有进一步向更高风险转化)。常见特性可能如下:(1)命中30天或者60天不良行为,但是没有进一步前向滚动; (2)不活跃用户或者自动取消用户; (3)不经常使用账户;(4)索赔金额低于某个阈值的保险账户; (5)NPV=0的账户;一般 Indeterminate账户不超过10%-15%比率,如果过高,是需要核查相关原因。真实评分卡开发时候,只会包含好坏样本。
相对采用统一的评分卡,分场景切割样本,按不同场景构建不同评分卡模型可能更有效。常见的场景划分方法:(1)专家经验和领域知识,再加以统计分析;(2)统计方法,如聚类和决策树等;4.1 专家经验划分的方式:(1)人口统计学规则:根据地理位置,年龄等。(2)产品类型:金卡或者普通卡,保险类型等 (3)获客来源:客户来源来源于店面, 互联网,经销商,电话等 (4) 数据来源;(5)申请类型: 新用户还是老用户;
4.2 统计方法(略)
4.3 comparing the improvement什么样的划分是合理的?相对不划分是否有提升? 这里主要参考c-stat,ks统计或者商业上的提升。具体可以参考下面两幅图。
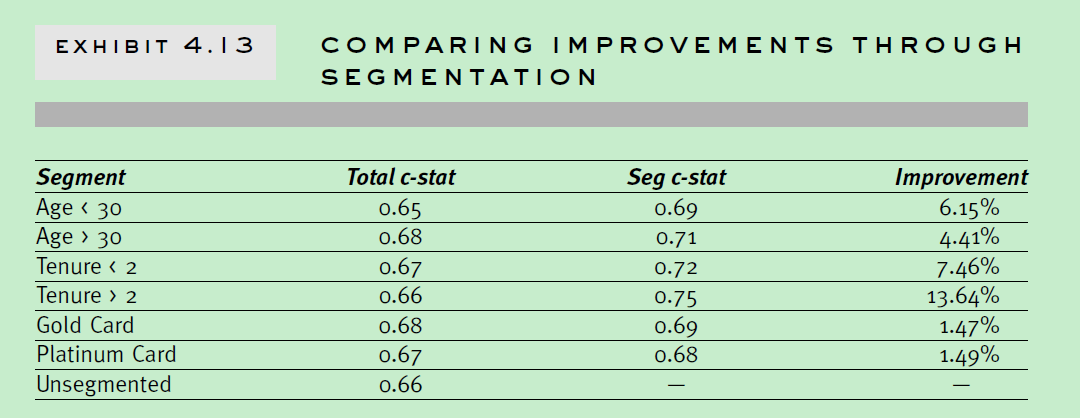
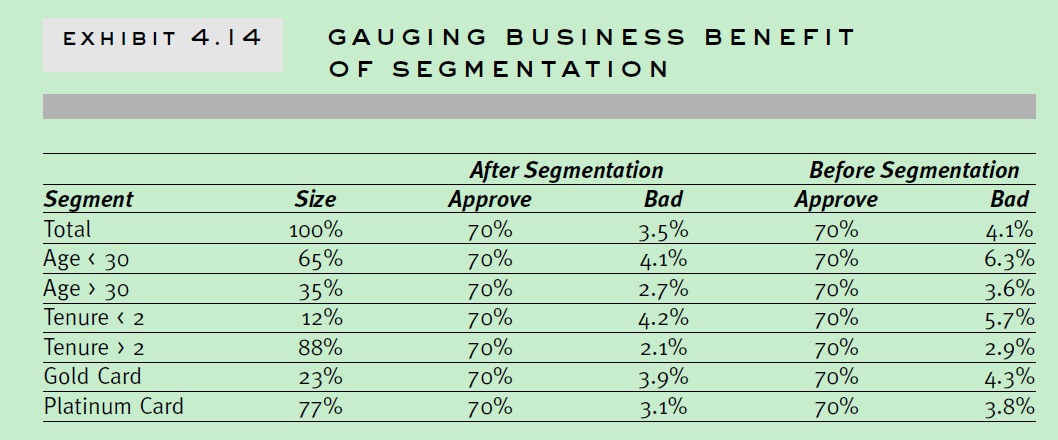
4.4 chose segments至于选择什么划分方式,需要综合考虑开发代价,实现代价,监控策略等。