范涛
发表于2017-03-31
第五章:Scorecard Development Process, Stage 3: Development Database Creation
Selection of Characteristics
特征选择需要考虑:(1)有预测能力; (2)可靠并且鲁棒性; (3)易于收集; (4)可解释性;
Sampling
Development/Validation: 样本划分为训练集和测试集。这种常用的方法,交叉验证,跨时间窗验证等。Good/Bad/Reject:常见的开发样本采样方式:()oversamling (过采样),这种需要事后进行模型调整; (2)按比率采样,开发样本分布和真实样本分布保持一致。
Development Data Collection and Construction
Random and Representative: 样本选择必须是随机的,代表开发的评分卡应用的对象(需要排除特定类型的样本)。样本倾斜某些群体会造成弱化其他群体的预测能力。
Nonsegmented Dataset:划分不同场景开发评分卡,所有需要对不同场景构造相对独立的切分样本集。同时,也需要保留一份没划分的样本。这样的做的目的,是方便统计划分场景的评分卡对不划分场景的评分卡模型带来的提升效果有多大。
Data Quirks: 当收集数据的时候,需要了解数据库相关数据变更历史,尤其样本窗口前后。这里面可能设计点字段值定义的改变,字段名的改变等。
Adjusting for Prior Probabilities (预测概率调整)
实际开发样本是经过一定过采样后的,这样开发样本好坏样本分布和真实样本中好坏分布是不一致的。针对这样情况,需要模型做一定的处理,来还原真实的分布情况。当然,有些情况是不需要调整的,比如如果你只关心评分相对排序(关心分数具体值),或者自变量和目标值关系。一般信用评分模型中是需要做特殊处理的,因为信用评分模型是用来做真实决策,设定阈值,考察评分和坏样本率具体真实对应关系。假设一个开发样本集,有2000好样本,2000坏样本,2000拒绝样本组成,那开发样本,申请通过率为67%,坏样本率为50%。但是真实的样本分布情况,如下图所示,其中申请通过率为70.5%, 坏样本率为12.4%。
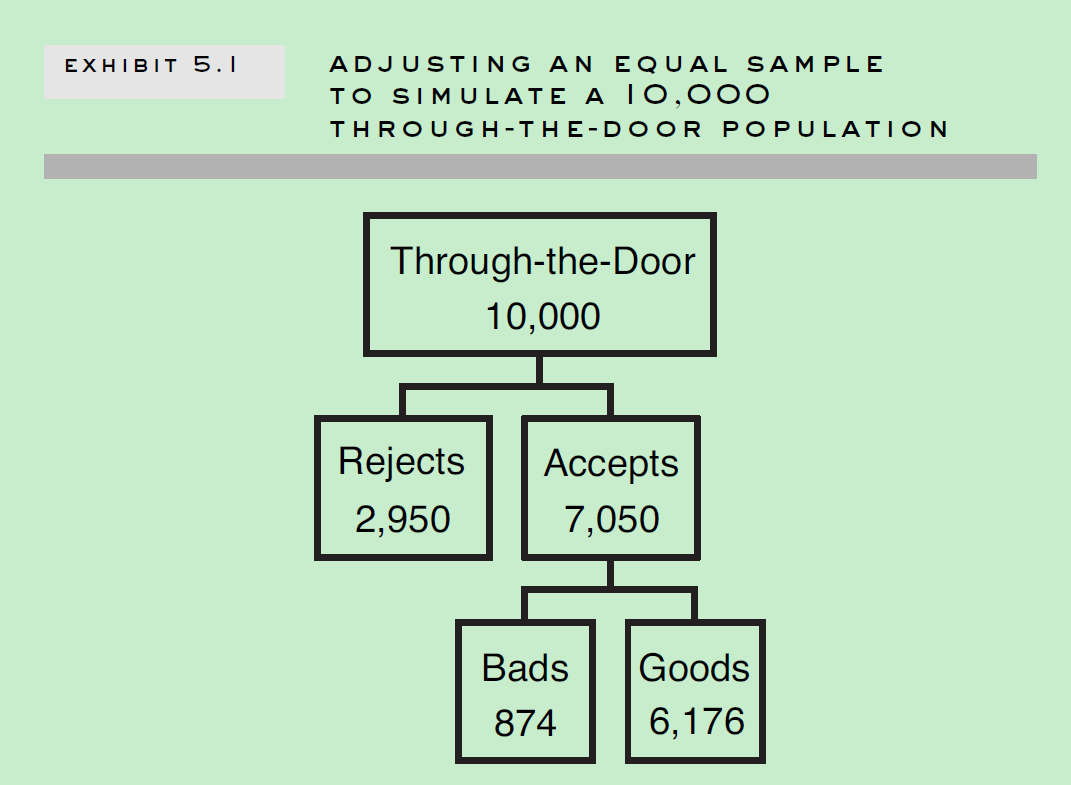
常见的调整方法:(1)偏置调整(offset); (2)样本权重调整(sample weight)
Offset Method:偏置调整,一般可以在模型预测概率后进行调整,下面是调整公式。
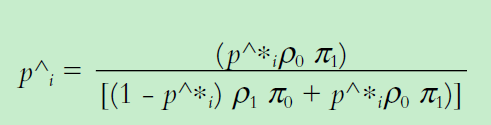
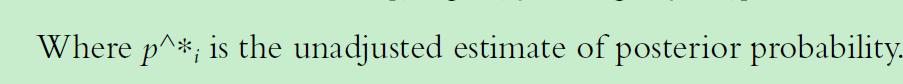

Sampling Weights:样本加权,对样本进行加权后再进行训练。下面提到不同类别的样本权重。
具体采用偏置调整方法,还是样本加权方法? 如果是lr模型,优先选择偏置调整方法,如果是一些非线性模型,加权方法更合适。同时,如果是基于非分组变量开发,那偏置调整方法更好;如果基于分组变量,点分卡开发,加权方法更好,因为他不仅修正预测概率,同时更正了参数估计,进而使派生出的特征评分更合理。