统计学习有一些常用的损失函数
1.0-1损失函数
2.平方损失函数
3.绝对损失函数
4.对数损失函数
损失函数越小,模型越好,由于模型的输入和输出(X,Y)是随机变量,遵循联合分布P(X,Y),所以损失函数的期望是
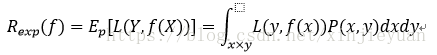
这也是泛化误差(generalization ability),也是期望风险(expected loss)
但是期望风险中的联合分布P(x,y)是未知的,所以无法运算。而且知道了P(X,Y)那还运算个屁啊,不需要学习了。
所以我们需要风险函数(risk function)来判断学习的风险最小学习模型。
对于模型f(x)关于训练数据集的平均损失成为经验风险(empirical risk)或者经验损失(empirical loss)
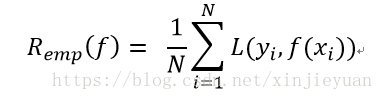
只要这个最小化,就可以得到w,b的最佳解。就是最好的