目前国际公认的信息标记种类共有如下三种:
| 名称 | 方式 | 实例 |
| XML(eXtensible Markup Language) | 基于HTML的用有名称与属性的标签进行标记的方式 | <name>...</name> <name /> <!-- --> |
| JSON(JavaScript Object Notation) | 可直接作为JS程序的一部分的用有类型的键值对进行标记的方式 | "key" : "value" "key" : ["value1", "value2"]
扫描二维码关注公众号,回复:
141047 查看本文章

"key" : {"subkey" : "subvalue"} |
| YAML(YAML Ain't Markup Language) | 用无类型键值对进行标记的方法 | key : value key : #Comment -value1 -value2 key : subkey : subvalue |
对于想要提取的信息,我们既可以通过完整解析信息的标记形式,再提取关键信息;又可以无视标记形式,直接搜索关键信息。
第一种方法对于信息的解析较为准确并可以对整个信息的结构有较为清楚的认识,但随之而来的是提取过程繁琐、对于大量信息的提取效率较低的问题;第二种方法较为快速,但其提取结果的准确性与信息内容相关,对于过于复杂的信息则可能提取错误。所以通常情况下我们是将这两种方法结合起来使用,即先通过解析标记形式确定要提取的信息的大致范围再在这范围中直接搜索与提取相关信息。
下面我们用实例来讲解一下
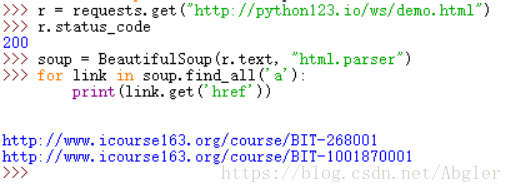
find_all()方法,故名思意即是对整个文档中的信息进行解析与查找,而第二个get方法则是直接在我们规定的<a>标签范围内对href进行搜索。
find_all方法的完整形式为:
| name | 对标签名称的检索字符串 |
| attrs | 对标签属性值的检索字符串,可标注属性检索 |
| recursive | 是否对子孙全部检索,默认为True |
| string | <>...</>中字符串区域的检索字符串 |
若其中某个参数需输入多个值时可用列表来实现,如:
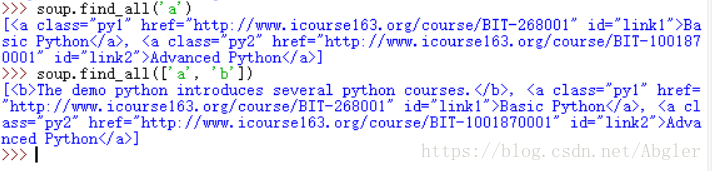
若name的值为True,则会现实当前文档的所有标签信息。
我们不仅可直接查找文本中具有相应属性的标签,也可以对属性进行规定再进行查找:

需要注意的是,find_all方法的所有参数必须为HTML文档中已含有的字段的全称,如上图中若将"link1"改为"link"则find_all将无法找到对应的标签,若想在不知道字段全称的情况下进行查找则需要用到正则表达式库(import re),这个库的相应用法我们将在以后具体实例中进行讲解。
因为find_all是bs4库中最常用的方法,所以可以直接使用<tag>(...)来代替<tag>.find_all(...),此外find_all()方法还有七个扩展方法:
| 方法 | 说明 |
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,字符串类型,同.find_all()参数 |