- 注:具体请参考视频教程以及课件,连续更新中。。。。
一、课程导学
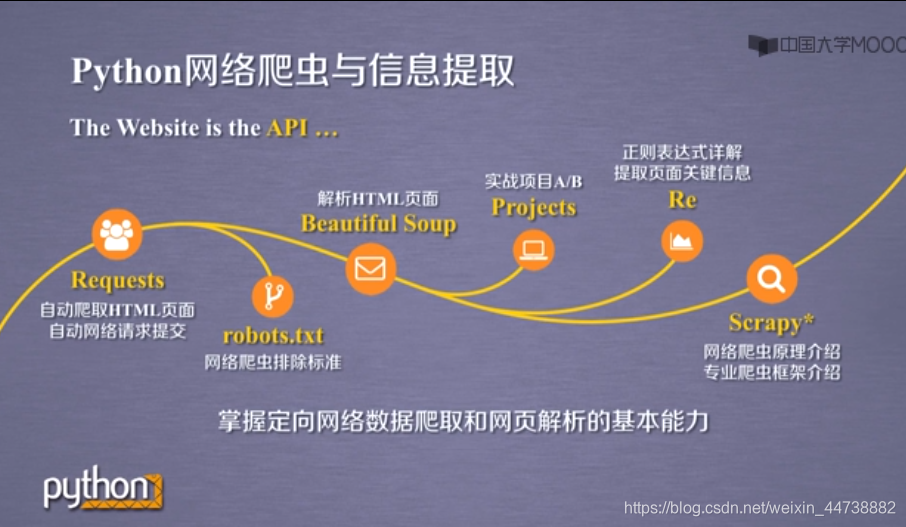
二、python语言开发工具:
- IDLE
- Sublime Test
- PyCham
- Anaconda(科学计算、数据分析)
三、网络爬虫之规则
1、Request库入门
- 安装Requests库
- 一个例子:
import requests
r = requests.get("http://www.baidu.com")
r.status_code
r.encoding = 'utf-8'
r.text
-
requests库的7个主要方法:
-
Requests库的get()方法
-
爬取网页的通用代码框架
-
HTTP协议及Requests库方法
-
Requests库主要方法解析
-
一个例子:
import requests
r = requests.get("http://www.baidu.com")
r.status_code
# r.text
# r.encoding
# r.apparent_encoding
r.encoding = r.apparent_encoding
r.text
- 注:备注部分表示没有转换编码时的显示情况
2、网络爬虫排除标准 robots.txt
3、Requests库网络爬取实战
- 实例1:京东商品页面爬取
import requests
url = "https://item.jd.com/40922103042.html"
r = requests.get(url)
# r.status_code
r.encoding
r.text[-200:]
全代码:
import requests
url = "https://item.jd.com/40922103042.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-200:])
except:
print("爬取失败")
- 实例2:亚马逊商品页面爬取
全代码:
import requests
url = "https://www.amazon.cn/gp/product/B01M8L5z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
- 实例3:百度/360关键词提交
百度:
import requests
url = "http://www.baidu.com/s"
keyword = "python"
try:
kv = {'wd':keyword}
r = requests.get(url,params=kv)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
360:
import requests
url = "http://www.so.com/s"
keyword = "python"
try:
kv = {'q':keyword}
r = requests.get(url,params=kv)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
-
区别:关键词提交接口不一样
-
*网络图片爬取和存储
import requests
import os
url = "https://www.fzu.edu.cn/attach/2019/04/04/341364.jpg"
root = "D://pictures//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
- 启示:注意文件处理方式
- IP地址归属地自动查询
import requests
url = 'http://m.ip138.com/ip.asp?ip='
try:
r.requests.get(url+'202.204.80.112') #域名自己想
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print('爬取失败')
- 启示:平时多留意url,以爬虫的视角看待网络
四、网络爬虫之提取
1、Beautiful Soup库入门
- Beautiful Soup库的安装
- 安装小测
from bs4 import BeautifulSoup
import requests
r = requests.get("http://python123.io/ws/demo.html")
r.text
#下半部分为改变输出样式
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
-
Beautiful Soup库的基本元素
-
Beautiful Soup库的理解
-
Beautiful Soup库的引用
-
Beautiful Soup类
-
Beautiful Soup库解析器
-
Beautiful Soup类的基本元素(5个)
-
基于bs4库的HTML内容遍历方法
-
HTML基本格式
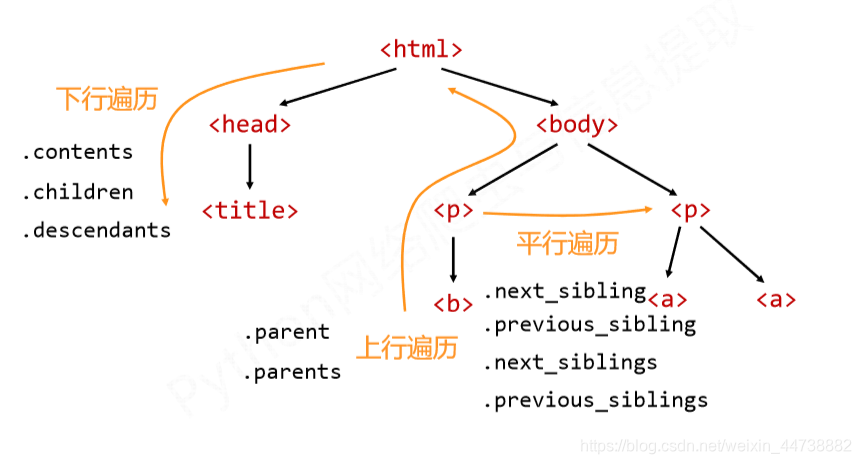
-
基于bs4库的HTML格式输出
-
能否让HTML内容更加友好的显示
-
bs4库的prettify()方法
-
bs4库的编码(均为utf-8编码)
-
小结:

2、信息标记与提取方法
- 信息标记的三种形式
- HTML的信息标记(www的信息组织方式)
- XML
- JSON
- YAML
- 三种信息标记形式的比较(含实例)
- 信息提取的一般方法
- 法一:完整解析信息的标记形式,再提取关键信息
- 法二:五十标记形式,直接搜索关键词
- 法三:融合方法
- 实例:提取HTML中所有URL链接

- 基于bs4库的HTML内容查找方法
- find_all() (配合正则表达式使用)
- 扩展方法
- 单元小结

3、实例一:中国大学排名定向爬虫
- 实例介绍
- 功能描述
- 定向爬虫可行性
- 程序结构设计
- 实例编写
#CrawUnivRankingA.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#这步不是很理解
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
- 实例优化
#CrawUnivRankingB.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
- 中文对其问题的原因:当中文宽度不够时,采用西文字符填充,中西文字符占用宽度不同
- 解决办法:采用中文字符的空格填充chr(12288)
五、网络爬虫之实战
Re(正则表达式)库入门
- 正则表达式的概念
- regular expression
- 正则表达式的语法
- 常用操作符
- 正则表达式语法实例
- Re库的基本使用
- Re库介绍
- 原生字符串类型 r’text’
- 正则表达式的表示类型
- Re库主要功能函数:

- 正则表达式使用时的控制标记:

- 使用格式(其余类似,使用前查看参数):

- Re库的另一种等价用法:
面向对象法:编译后的多次操作(适用于进行多次匹配) - Re库的Match对象
- Match对象介绍
- Match对象的属性
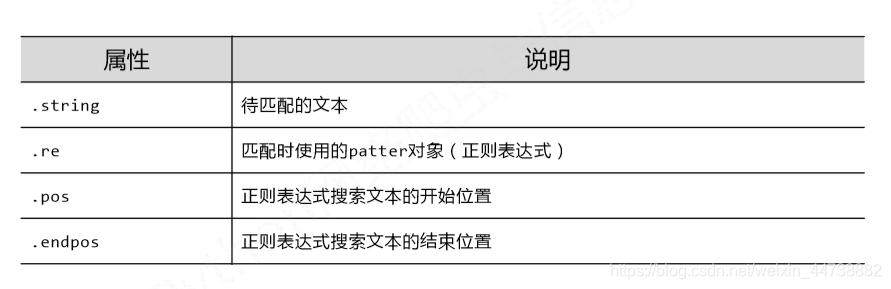
- Match对象的方法

- Match对象的实例
- Re库的贪婪匹配和最小匹配
- Re库默认采用贪婪匹配
- 如何输出最短子串?:
只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配 - 小结:

实例2、淘宝商品比价定向爬虫
#CrowTaobaoPrice.py
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
- 注:字符串和正则表达式是难点
实例3、股票数据定向爬虫
-
优化前:
#CrawBaiduStocksA.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html=="": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write( str(infoDict) + '\n' ) except: traceback.print_exc() continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:/BaiduStockInfo.txt' slist=[] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main() -
优化后:
#CrawBaiduStocksB.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url, code="utf-8"): try: r = requests.get(url) r.raise_for_status() r.encoding = code return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL, "GB2312") soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html=="": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'股票名称': name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write( str(infoDict) + '\n' ) count = count + 1 print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="") except: count = count + 1 print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="") continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:/BaiduStockInfo.txt' slist=[] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
后续见文章网络爬虫之框架。。。