前言
上一节爬取了网络图片,写的不过瘾,最近发文访问量破1W了,主页看不到具体的访问量数有点小苦恼,刚好写个脚本来解决这个问题,练练手。
技术框架
bs4 + requests库
bs4教程:Python中使用Beautiful Soup库的超详细教程
这兄弟写的很详细,哈哈哈以后可以在这里查找要用的命令
网页分析
右键检查源码打开我自己的博客网站,然后ctrl + f搜索关键字“1万+”
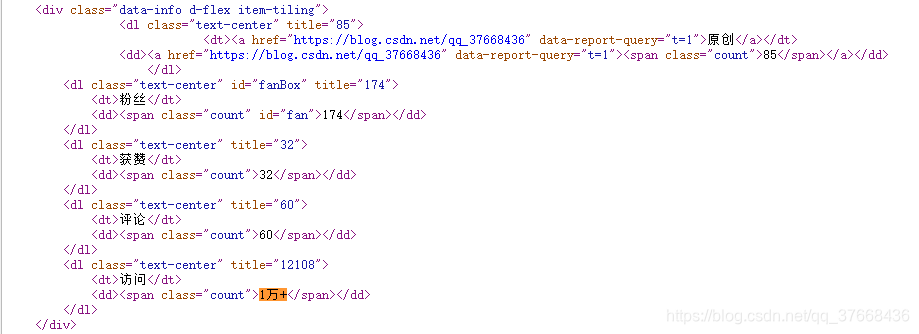
欧克,他的特点显而易见,存在dl标签中,有一个class属性并且都是text-center,然后具体的数存在他的title属性中。
于是就知道操作了:
匹配所以dl标签并且class属性是text-center,然后获取title属性里面的值
代码设计
整体框架:
def main():
uinfo = []
url = "https://blog.csdn.net/"
userId = "qq_37668436"
html = getHTMLText(url + userId)
fillUnivList(uinfo,html)
printUnivList(uinfo)
- uinfo列表用来存放数据
- url是csdn链接
- userId是每个用户的Id
- 写getHtmlText函数来获取网页文本
- fillUnivList解析文本数据存在unifo中
- 最后写printUnivList打印结果
getHTMLText函数:
def getHTMLText(url):
try:
r = req.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print("html文本获取成功")
return r.text
except:
print("html文本获取失败")
return ""
fillUnivList函数:
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for dl in soup.find_all('dl', class_ = 'text-center'):
ulist.append(str(dl.get('title')))
printUnivList函数:
def printUnivList(ulist):
table = PrettyTable(["文章数", "粉丝数", "点赞数","评论数","阅读量"])
try:
table.add_row(ulist[0:5])
print(table)
except:
table.add_row(["null","null","null","null","null"])
print(table)
printUnivList函数用了prettyTable来打印消息,它会自动帮你格式化打印,比较好看,这里面如果用户Id不存在的话传入的ulist是null的,所以加个异常处理全打印null。
完整代码
csdn网页做了点小修改,代码也做了点小修改,还是用英文吧,prettytable对中文的支持不太行。。。
# -*- coding:utf-8 -*-
import requests as req
from bs4 import BeautifulSoup
from prettytable import PrettyTable
def getHTMLText(url):
try:
r = req.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("html文本获取失败")
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for dl in soup.find_all('dl', class_ = 'text-center'):
ulist.append(str(dl.get('title')))
def printUnivList(ulist):
table = PrettyTable(["Articles", "Fans", "Likes","Comments","Reading","Integral","Collections","Weekly ranking", "Total ranking"])
try:
table.add_row(ulist[0:9])
print(table)
except:
table.add_row(["null","null","null","null","null","null","null","null","null"])
print(table)
print("解析错误")
def main():
uinfo = []
url = "https://blog.csdn.net/"
userId = "qq_37668436"
html = getHTMLText(url + userId)
fillUnivList(uinfo,html)
printUnivList(uinfo)
if __name__ == '__main__':
main()
输出效果

总结
学以致用吧~