1 读《Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels》-NeurIPS 2019
GNN的优势:1. 图神经网络使用多层结构和非线性激活函数来提取图的高阶信息作为特征。
GNN的缺点:1.训练过程中存在大量的超参数,且训练过程具有非凸性,使得 GNN 的训练更加困难。2.GNN 的表达能力随参数的数量而变化,在计算资源有限的情况下,很难充分利用 GNN 的表达能力。
GKs的优势:1. GKs继承了内核方法的所有优点。由于相应的优化问题是凸的,GKs易于训练;2.显式或隐式地,基于输入图的组合特性构建特征向量;3.较好的理论证明。
GKs的当前缺点:1.手工制作的功能可能不足以捕获高阶的涉及节点间复杂交互的信息。
这篇文章的核心创新点:提出一类新的graph kernel,即图神经切线核 (GNTKs),它对应于通过梯度下降训练的无限宽的多层 GNN。即结合GNN和GKs两者的优势,提出了一个能像GNNs一样提取强大功能,并且像GKs一样容易训练和分析的模型。 其中的NTKs方法来源于neural tangent kernels(非GNN)Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. arXiv preprint arXiv:1806.07572, 2018.
1.1相关概念
- Block Operation:块操作在领域以及本身节点下获得特征。例如典型的块操作:求和,并用非线性变换聚集特征,例如多层感知器(MLP)或紧跟ReLU的完全连接层。
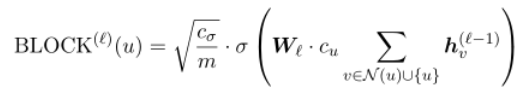
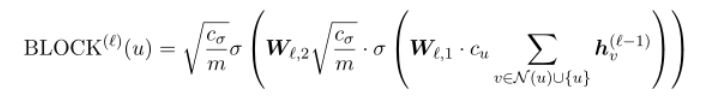
- Readout Operation:为了得到一个完整的图的表示,在L个聚合步骤之后,我们对所有的节点特征进行求和。
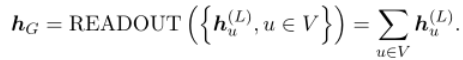
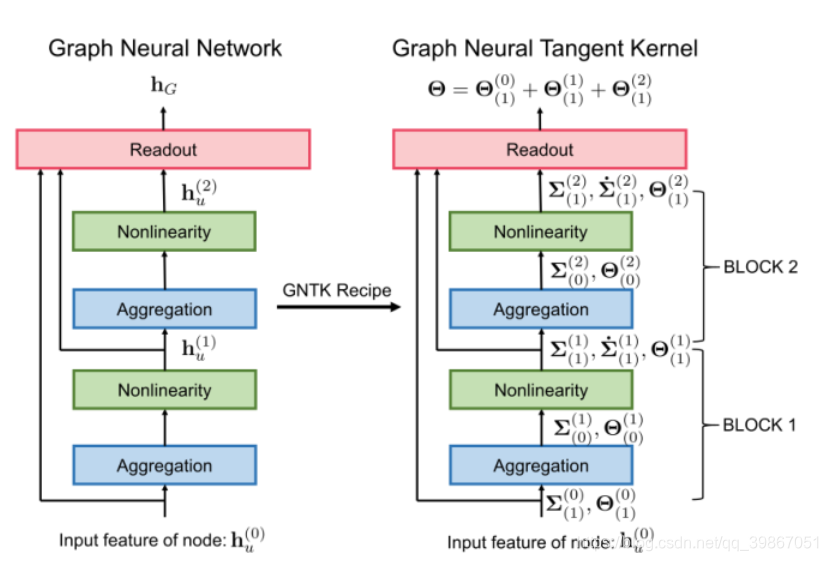
1.2GNTK
首先说明NTK(神经切核),其定义为在参数的随机初始化下,随机矩阵H(0)在概率上收敛到的确定的核矩阵。其中的H(t)如下图表示:
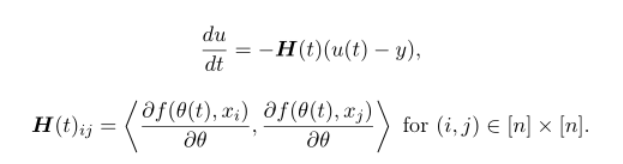
所以作者将起类比到GNN中,并将上面的表达式“更新”为,即该式对应的值不随训练次数而改变:
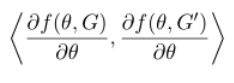
并使用上面的定义重新定义了上面的Block Operation以及Readout Operation。
其中Block Operation:第一个为协方差,第二个为中间核的值
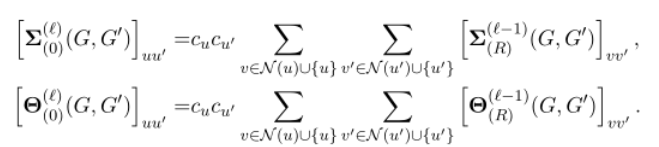
对于每一个 定义如下的公式, 块操作的个数, 全连接层。
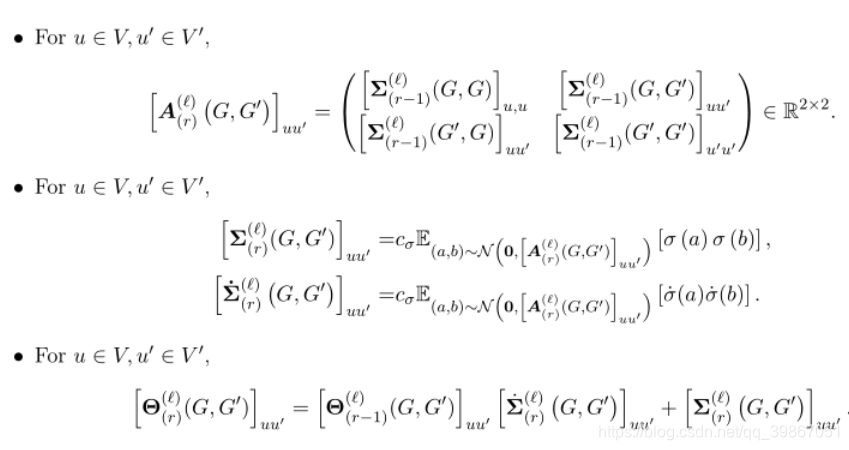
对于Readout Operation
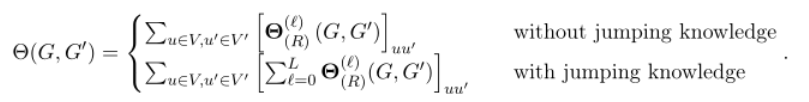
对于完整的GNTKs和GNN的区别:
GNTK的总体损失为:(在概率为 下)
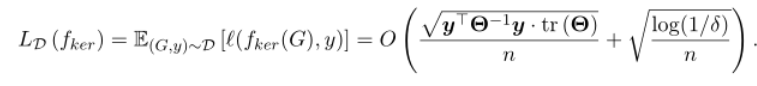
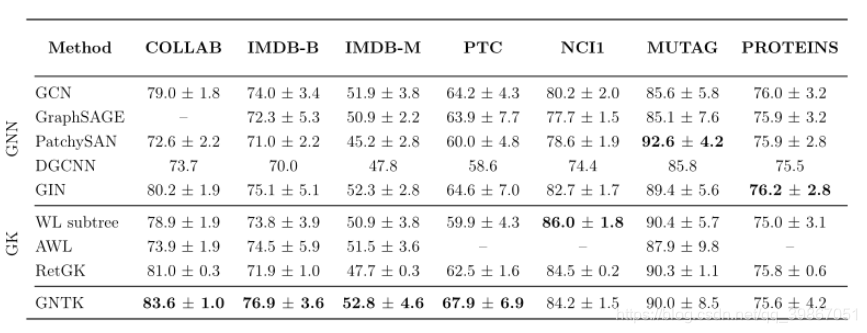
1.3 结果
效果的提升:运算速度提升(在社交数据集中GPU TITAN x 19min-2min),在社会数据集中的分类精度有所提升。
在社会数据集(社交网络)中的效果好,但是在蛋白质网络中的效果没有前人工作好
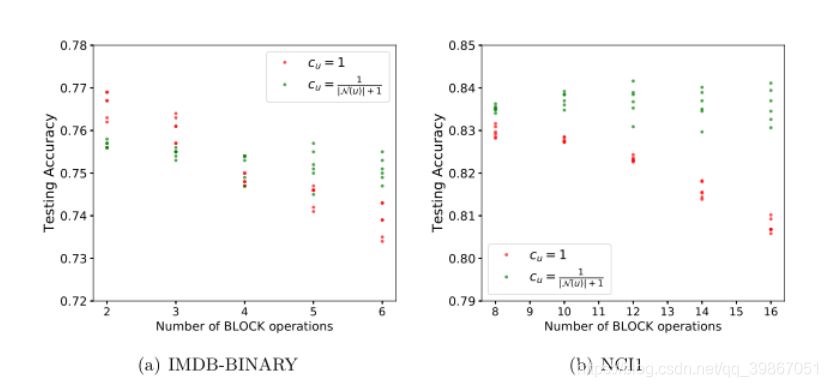
块操作数和缩放因子对GNTK性能的影响:
跳跃知识和MLP层数对GNTK性能的影响:
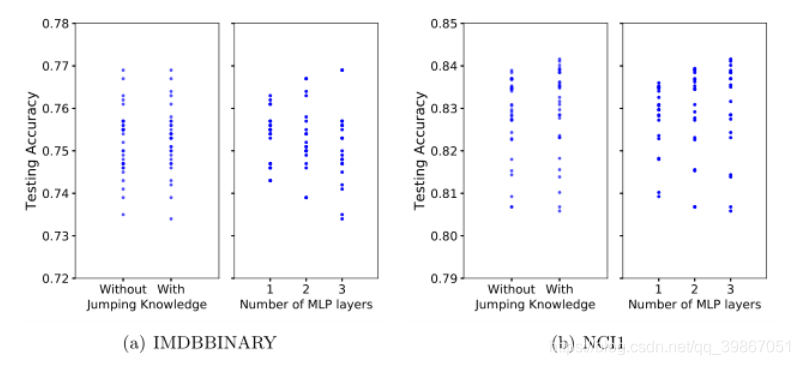
跳跃知识网络(JK)对跳跃知识和MLP层数的影响有望提高性能当跳跃知识被应用时(JK-Net),GNTK在NCI和IMDB数据集上的性能都得到了提高。此外,增加MLP层的数目可以使性能提高0.8%。这些实证结果进一步证实了GNTKs可以继承GNNs的优点,因为GNN架构的改进反映在GNTKs的改进上。我们的结论是,GNTKs对图形表示学习具有吸引力,因为它们可以结合GNNs和GKs的优点。
可深入
其他的kernel模型可以看一下的:
-
WL subtree:Nino Shervashidze, Pascal Schweitzer, Erik Jan van Leeuwen, Kurt Mehlhorn, and Karsten M Borgwardt. Weisfeiler-lehman graph kernels. Journal of Machine Learning Research, 12(Sep): 2539–2561, 2011.
-
AWL:Sergey Ivanov and Evgeniy Burnaev. Anonymous walk embeddings. In ICML, 2018.
-
RetGK:Zhen Zhang, Mianzhi Wang, Yijian Xiang, Yan Huang, and Arye Nehorai. RetGK: Graph kernels based on return probabilities of random walks. In NeurIPS, 2018b.
-
graphlet kernel:Nino Shervashidze, SVN Vishwanathan, Tobias Petri, Kurt Mehlhorn, and Karsten Borgwardt. Efficient graphlet kernels for large graph comparison. In Artificial Intelligence and Statistics, pages 488–495, 2009
-
random walk kernel:S Vichy N Vishwanathan, Nicol N Schraudolph, Risi Kondor, and Karsten M Borgwardt. Graph kernels. Journal of Machine Learning Research, 11(Apr):1201–1242, 2010. && Thomas Gärtner, Peter Flach, and Stefan Wrobel. On graph kernels: Hardness results and efficient alternatives. In Learning theory and kernel machines, pages 129–143. Springer, 2003.