UA MATH571A R语言回归分析实践 一元回归3 NBA球员的工资
前两讲已经完成了大致的分析了,我们已经明确了NBA球员名次与工资的负相关关系,接下来我们对一元线性回归模型做个诊断,看看为什么它的解释力很弱。
残差分析
做残差分析以前,我们先来看看解释变量X,这里就看看点图和序列图
dotchart(X)# dot plot
I <- c(1:651) # 651 is the sample size
plot(I,X,type = "l")# sequence plot
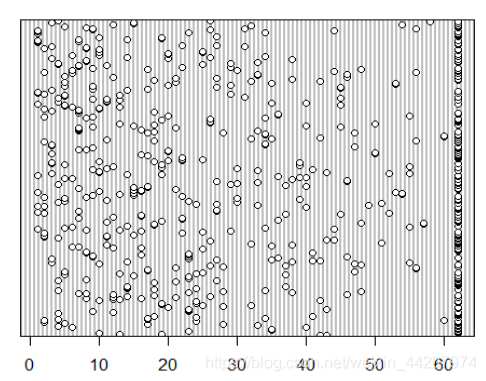
这个点图告诉我们两个信息,第一个信息是Draft Number是62的选手未必太多了点,这是很典型的删失数据的特征,计量经济学告诉我们应该用Tobit模型来分析这种数据;第二个信息是一个X的值可能对应多个Y的值,这说明数据存在replicate,我们有理由怀疑一元线性回归是欠拟合的。考虑到这个是讲回归分析的文章,就先不介绍Tobit模型怎么处理这个例子了,但之后我们需要做一个欠拟合检验,看看一元线性回归是不是真的欠拟合。
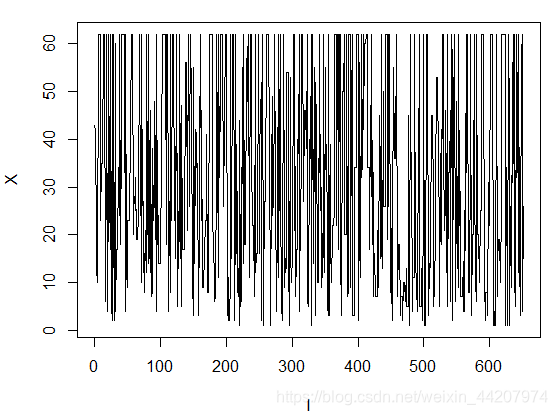
这个序列图不存在什么特别的模式,我们可以借此排除掉序列相关性。
看完解释变量的特征后,我们再来看看残差的特征。
plot(resid(ureg01.lm)~I,type = "l")
abline(h=0)

这是残差的序列图,里面也没有很神奇的模式,所以残差也是不存在序列相关的。解释一下plot函数,比如想画X关于Y的图第一个输入可以是Y~X,也可以是X,Y。resid函数会返回模型对象的残差,也可以用ureg01.lm$residuals代替,那个$就是访问模型对象的某个属性。abline是辅助线的命令,h=0表示是截距为0的水平线。
plot(resid(ureg01.lm)~X)
abline(h=0)

这个是残差关于解释变量的图,我们能看出两个信息:62那个位置存在删失、已经存在一个明显的非线性的模式,因此模型关于X很可能不应该是线性的。删失先按下不表,关于模型关于X非线性的问题,我们之后可以做一个Box-Cox变换来解决。
plot(resid(ureg01.lm)~fitted(ureg01.lm))
abline(h=0)

这个是残差关于拟合值的图,它能告诉我们的信息和残差关于X的差不多,就不细说了。但残差图中的这种模式还说明残差可能并不具有同方差的性质,我们有必要再做一个同方差检验判断一下。plot中用了一个resid,它返回一个模型对象的拟合值,也可以用ureg01.lm$fitted.values代替。
正态性、同方差性的检验
先做一个QQ图来看一下
qqnorm(ureg01.lm$residuals)

比较明显,这个完全不是线性关系,基本可以否定残差是服从正态分布的,为了保险起见,还是做一下假设检验看看。用Shapiro检验
> shapiro.test(resid(ureg01.lm))
Shapiro-Wilk normality test
data: resid(ureg01.lm)
W = 0.85832, p-value < 2.2e-16
发现p值非常小,可以显著拒绝原假设(正态性检验的原假设是服从正态分布),认同残差的确不服从正态分布。
关于残差的分布还需要做一下同方差检验,一般用Brown-Forsythe检验就可以。为了做这个检验,我们需要先下载一个包,
install.packages("car")
做这个检验的思路其实是把样本分成不同的group,检验是不是所有group的残差都是同方差的,只要有任意两个group残差不是同方差的,那么同方差假设就不成立,一般分类可以依据之前画的残差图来分类。这里我就简单分两类,把名次在30以内的分为一类,在30以外的分为另一类,也就是第三行,分好类别忘了把类别用as.factor变成一个factor。然后用car包中的levene检验的函数来做检验,输入的时候残差需要根据X排序。根据p值,我们可以拒绝原假设(同方差),所以同方差的确是不成立。
> library(car)
> ei <- resid(ureg01.lm)
> G<-(X<30)[order(X)]
> group<-as.factor(G)
> BF.htest <- leveneTest(ei[order(X)],group)
> BF.htest
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 48.474 8.218e-12 ***
649
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
欠拟合检验
接下来我们需要验证一下模型是不是欠拟合了,我们用lack-of-fit ANOVA来完成这个检验。因为存在replicate,所以full model应该是factor model,reduced model才是一元线性回归。第一行就是估计factor model的code,只需要把X变成factor(X)就好,然后用ANOVA分析这两个模型,注意是reduced model的模型对象在前,full model的在后。看ANOVA的那个p值,在0.1的显著性水平下我们应该拒绝原假设,即full model和reduced model还是有差别的,模型存在欠拟合,我们应该用full model;在0.05或者0.01的显著性水平下,我们不能拒绝原假设,即两种模型没有差别。
> fmodel.lm <- lm(Y ~ factor(X))
> anova(ureg01.lm,fmodel.lm)
Analysis of Variance Table
Model 1: Y ~ X
Model 2: Y ~ factor(X)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 649 2.6290e+16
2 591 2.3267e+16 58 3.0227e+15 1.3238 0.06068 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
最后总结一下我们诊断出的这个模型存在的问题:
- 工资关于名次存在负相关,但可能不是线性关系;
- 残差独立同分布,但不是正态分布;并且同方差假设也不成立;
- 模型存在replicate,一元线性回归有欠拟合的风险