博客原文 https://blog.csdn.net/yongxiebin9947/article/details/79368752
PointNet 是斯垣福大学在2016年提出的一种点云分类/分割深度学习框架。众所周知,点云在分类或分割时存在空间关系不规则的特点,因此不能直接将已有的图像分类分割框架套用到点云上,也因此在点云领域产生了许多基于将点云体素化(格网化)的深度学习框架,取得了很好的效果。但是将点云体素化势必会改变点云数据的原始特征,造成不必要的数据损失,并且额外增加了工作量,而 PointNet 采用了原始点云的输入方式,最大限度地保留了点云的空间特征,并在最终的测试中取得了很好的效果。
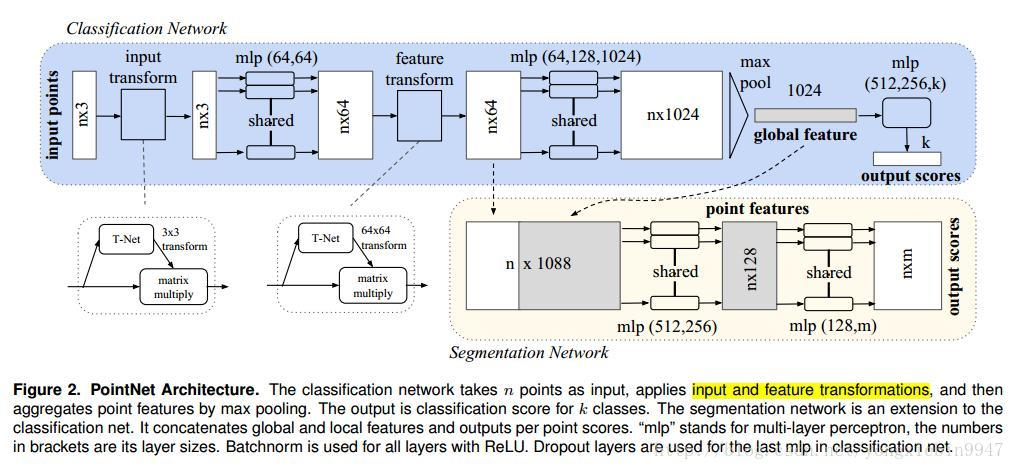
主要是那张流程图。文章中的其他地方基本都是对各种方法的比较与数学证明,前者一直在说为啥我这个框架中的这个地方要用这个方法,对理解这个框架用途不大;而后者我直接跳过了,等有兴趣了(N年过后?)再来深究。
这里主要说一下PointNet的程序在分类模块实现的大致流程。
PointNet 官方使用了 tensorflow 实现,代码写的相当工整易读,而这个方法在代码中实现起来也比论文中看起来更简单。其主要分成以下三部分:数据处理 TF图谱构建 开始学习
数据处理,将点云处理成程序可用的格式,具体实现在 provider.py 中,主要包含了数据下载、预处理(shuffle、rotate等)、格式转换(hdf5->txt)
TF图谱
构建,绿线框是一些很常规的操作,对应流程图中相对应的部分看看就好了。

红线框部分才是这篇论文一直在强调、证明的部分。下面先看一下第一个红线框中 input_transform_net() 对应的代码部分(下图)。可以看出,文章中的转换矩阵是使用额外一个小网络(T-Net),对其输入训练数据而学习得到的3*K的矩阵(K=3)。

而第二个转换矩阵微微有些不同,由于当进行到这一步的时候,点云已经被处理成了一条条的特征向量(B*N*1*K)。输入不同了,网络结构和参数也自然有了一些变化。最终输出 B*K*K 的转换矩阵。

在网络图谱整体框架搭好之后,就可以用TF提供的API进行训练了。
以上即为 PointNet
分类网络的大致框架。
博客原文 https://blog.csdn.net/yongxiebin9947/article/details/79368752