这是一个了解CNN主流变化和特点的旅程。
卷积神经网络:构建基块
卷积神经网络(或简称CNN)是提取“可学习特征”的常用方法。 CNN在深度学习和神经网络的发展与普及中发挥了重要作用。
但是,这篇博客中,我将重点放在完整的CNN架构上,而不是只关注单个内核。 我们可能无法逐一浏览CNN历史上的每个主要发展节点,但是我将尝试带您了解常见的CNN架构如何随着时间演变。 您需要对什么是CNN有所了解。

LeNet:一切开始的地方
LeNet是第一个将反向传播应用于实际应用的CNN架构,突然之间,深度学习不再只是一种理论。 LeNet用于手写数字识别,能够轻松胜过其他所有现有方法。 LeNet体系结构非常简单,只有5个层,由5 * 5卷积和2 * 2池化组成,它为更好,更复杂的模型铺平了道路。

AlexNet:越深越好
AlexNet是最早在GPU上实现的CNN模型之一,该模型真正将当时不断增长的计算机计算能力与深度学习联系在一起。 他们创建了一个更深,更复杂的CNN模型,该模型具有各种大小的内核(例如11 * 11、5 * 5和3 * 3),并且通道数比LeNet大得多。 他们还开始使用ReLU激活代替S型或tanh激活,这有助于训练更好的模型。 AlexNet不仅在2012年赢得了Imagenet分类挑战的冠军,而且以惊人的优势击败了亚军,这突然使非深度模型几乎被淘汰。

InceptionNet:多尺度特征提取
InceptionNet是CNN历史上的一大进步,它解决了多个方面的问题。 首先,与现有模型相比,InceptionNet具有更深,更多的参数。 为了解决训练更深层模型的问题,他们采用了在模型之间使用多个辅助分类器的思想,以防止梯度消失。 但是,他们的主要主张之一是并行使用各种大小的内核,因此增加了模型的宽度而不是深度。 他们提出,这样的体系结构可以帮助他们同时提取更大或更小的特征。

VGG:3x3卷积的力量
尽管CNN模型的所有先前模型都使用更大的卷积核(例如AlexNet具有11 * 11卷积核),但VGG提出了将所有这些卷积核分解为3 * 3卷积核的想法。 根据VGG架构,堆叠在一起的多个3 * 3卷积能够复制更大的卷积核,并且它们之间存在更多的非线性特征(就激活函数而言),甚至比具有更大卷积核的对应模型表现更好。 他们甚至引入了1 * 1卷积,以进一步增加模型中存在的非线性。 从那时起,VGG模型就变得非常出名,甚至在今天的各种教程中也使用了VGG模型。
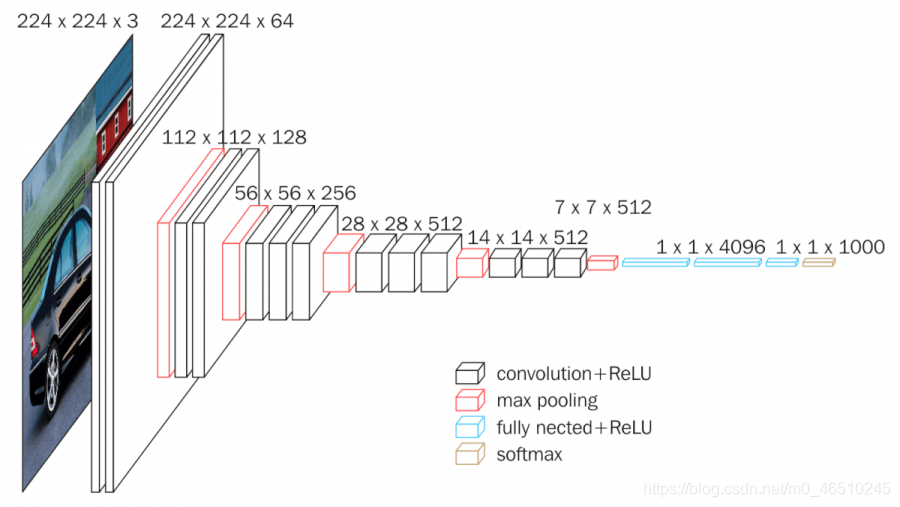
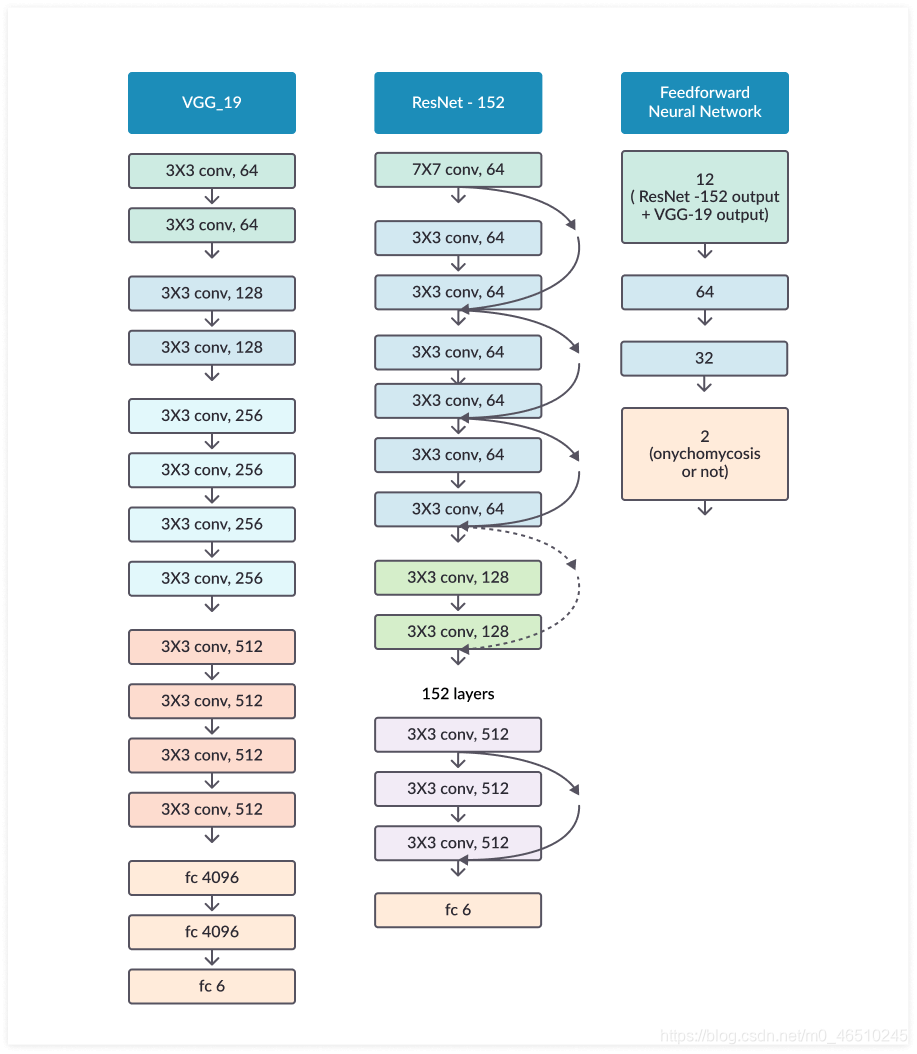
ResNet:解决梯度消失
由于深度学习中一个非常普遍的问题,即消失的梯度,简单地堆叠多个CNN层以创建更深层模型的大趋势很快就停止了。 简而言之,在训练CNN时,梯度从最后一层开始,需要在到达初始层之前穿过中间的每一层。 这可能会导致梯度完全消失,从而难以训练模型的初始层。 ResNet模型引入了残差块连接,该模型为梯度传递创建了替代路径以跳过中间层并直接到达初始层。 这使人们能够训练出性能较好的极深模型。 现在在现代CNN架构中具有残留连接已成为一种常见的做法。
MobileNet和MobileNetV2:迈向边缘友好模型
CNN在此阶段的总体趋势是创建越来越大的模型以获得更好的性能。 尽管GPU提供的计算能力的进步使他们能够做到这一点,但在机器学习世界中也出现了一系列新产品,称为边缘设备。 边缘设备具有极大的内存和计算约束,但是为许多无法应用GPU的应用打开了大门。
为了创建可以与现有最新技术相媲美的更轻巧的CNN模型,提出了MobileNet。 MobileNet引入了可分离卷积的概念。 用更简单的术语来说,它将二维卷积内核分解为两个单独的卷积内核,即深度方向(负责收集每个单独通道的空间信息)和点方向(负责处理各个通道之间的交互)。 后来,还引入了MobileNetV2,并在体系结构中进行了剩余连接和其他调整,以进一步减小模型的大小。

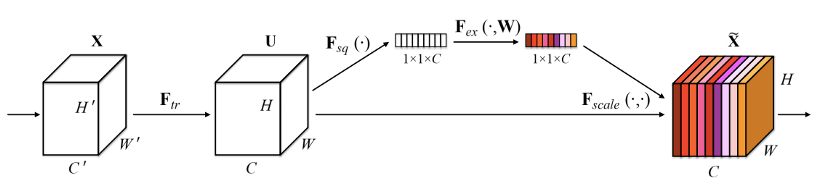
EfficientNet:挤压和激活层
随着各种针对性能或计算效率进行改进的独特模型的出现,EfficientNet模型提出了这样的想法,即可以通过相似的体系结构解决这两个问题。 他们提出了一种通用的CNN骨架架构和三个参数,即宽度,深度和分辨率。 模型的宽度是指各层中存在的通道数,深度是指模型中的层数,分辨率是指模型的输入图像大小。 他们声称,通过将所有这些参数保持较小,可以创建一种竞争性强但计算效率高的CNN模型。 另一方面,仅通过增加这些参数的值,就可以创建更好的高精度模型。
尽管之前已经提出了“挤压”和“激活”层,但它们是第一个将这种想法引入主流CNN的。 S&E层跨通道创建交互,这些交互不会改变空间信息。 这可以用来降低不太重要的因素的影响。 他们还介绍了新出现的Swish激活函数而不是ReLU,这是提高性能的重要因素。 在各种计算资源可用性类别下,EfficientNets是目前性能最好的分类模型。
下面是什么呢?
如今,CNN模型已在其图像分类性能以及各种其他问题(例如对象检测和分段)的传递学习能力方面进行了测试。 这些问题中的一些已经被认为已经解决。 重点正转向沙漏架构之类的CNN模型,它的输出图像分辨率与输入相同。 但是,我在本博客中介绍的骨干结构也可以直接用于各种深度学习任务,因此,即使图像分类问题已基本解决,但该领域的发展在将来仍将具有重要意义。
参考文献
[1] LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278–2324.
[2] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
[3] Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
[4] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[5] Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[6] Howard, Andrew G., et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv preprint arXiv:1704.04861 (2017).
[7] Tan, Mingxing, and Quoc V. Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” arXiv preprint arXiv:1905.11946 (2019).
作者:Prakhar Ganesh
deephub翻译组:孟翔杰