参考文章地址:https://www.cnblogs.com/skyfsm/p/8451834.html
1、LeNet
 定义了CNN的最基本的架构:卷积层、池化层、全连接层。
定义了CNN的最基本的架构:卷积层、池化层、全连接层。
2、AlexNet
 特点:
特点:
- 更深的网络
- 数据增广技巧来增加模型泛化能力。
- 用ReLU代替Sigmoid来加快SGD的收敛速度
- 引入drop out防止过拟合
- Local Responce Normalization:局部响应归一层
3、VGG-16

特点:
- 进一步加深;
- 卷积层都是same的卷积,下采样完全是由max pooling来实现;
- 卷积层使用更小的filter尺寸和间隔,使用1×1和3×3的小卷积核;
- 3×3卷积核的优点:
(1)多个3×3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性
(2)多个3×3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3×3的卷积层参数个数3×(3×3×C×C)=27CC;一个7×7的卷积层参数为49CC;所以可以把三个3×3的filter看成是一个7×7filter的分解(中间层有非线性的分解) - 1*1卷积核的优点:
作用是在不影响输入输出维数的情况下,对输入进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
4、GoogLeNet
 特点:
特点:
(1)引入Inception结构(如下图),增加深度也增加宽度;
Inception结构里的卷积stride都是1,另外为了保持特征响应图大小一致,都用了零填充。最后每个卷积层后面都立刻接了个ReLU层。在输出前有个叫concatenate的层,直译的意思是“并置”,即把4组不同类型但大小相同的特征响应图一张张并排叠起来,形成新的特征响应图。Inception结构里主要做了两件事:
- 通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。
- 为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。
(2)中间层的辅助LOSS单元,目的是计算损失时让低层的特征也有很好的区分能力,从而让网络更好地被训练;
(3)后面的全连接层全部替换为简单的全局平均pooling,减少参数个数;

5、ResNet

特点:
- 层数非常深,已经超过百层
- 引入残差单元来解决退化问题
对于一般的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。
虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。
退化问题说明了深度网络不能很简单地被很好地优化。也就是说想通过学习优化实现H(x)=x,即通过学习让F(x)操作失效很困难,那么怎么解决退化问题呢?
深度残差网络。
增加一个连接(short cut),让H(x)=x+F(x),即F(x)=H(x)-x,那么现在想解决退化,网络只需要通过学习让F(x)=0即可,而F(x)就是残差,所以网络叫残差网络,拟合残差相对而言是要容易很多的。
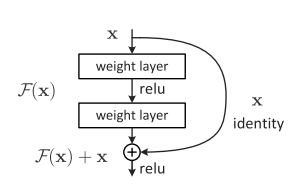
考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
- zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
- projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
6、DenseNet
特点:
1,减轻了消失梯度(梯度消失)
2,加强了特征的传递
3,更有效地利用了特征
4,一定程度上较少了参数数量
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。下图是 DenseNet 的一个dense block示意图,一个block里面的结构如下,与ResNet中的BottleNeck基本一致:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) ,而一个DenseNet则由多个这种block组成。每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成

密集连接不会带来冗余吗?不会!密集连接这个词给人的第一感觉就是极大的增加了网络的参数量和计算量。但实际上 DenseNet 比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet则是让l层的输入直接影响到之后的所有层,它的输出为:xl=Hl([X0,X1,…,xl−1]),其中[x0,x1,…,xl−1]就是将之前的feature map以通道的维度进行合并。并且由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了,这也是为什么DneseNet的参数量较其他模型大大减少的原因。这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题
需要明确一点,dense connectivity 仅仅是在一个dense block里的,不同dense block 之间是没有dense connectivity的,比如下图所示。
 缺点:内存占用非常大
缺点:内存占用非常大