简介
首先来回顾一下CNN发展的历史,为什么要做这个总结呢?除了加深我们对CNN框架的理解之外,沿着CNN发展的历史进程走一遍也是非常有趣的事。假如你不研究历史,你肯定不知道打火机居然早于火柴被发明,而ReLU比tanh更早被应用在神经网络中。
.
.
很久很久以前:
神经网络这一概念最早是生物界提出的,而人工智能界的神经网络很大程度上是在模拟人类的神经元。影响到CNN起源的相关研究是有关视觉皮层的,其中较著名的是Hubel 和Wiesel1968年做出的工作。他们将猫麻醉后,把电极插到其视觉神经上连接示波器,并给它们看不同的图像,观察脑电波的反应。由这些现象得到的结论有:

由于这项发现,Hubel和Wiesel共享了1981年的诺贝尔奖。这项发现不仅在生物学上留下浓墨重彩的一笔,而且对20年后人工智能的发展埋下了伏笔。
- 最直接的就是多层级结构,这项研究发现几层不同的细胞,最早的视网膜和LGN用于接受视觉信息并做初步处理响应光点,然后简单细胞开始响应线条,再之后复杂细胞和超复杂细胞做进一步处理。
- 另一个就是过滤(filtering)的概念,我们不同细胞只对特定的输入感兴趣,而会过滤掉其他的信息。
- 此外还有本地连接,即每个神经元不会对整个图像做出响应,它只会对其本地附近的区域感兴趣。
- 最后但是同样重要的概念就是平移不变性,这种不变性被认为是启发了神经网络中池化单元的设计。
虽然我们在生物上得到了很多启发,但是我们对人类大脑的工作机理的了解仍然只是皮毛,由此也给仿生的CNN留下许多疑惑。例如:

总之,这么来看,CNN中大部分重要的思想都在生物中有所体现。
.
.
.
(-1980年-)Neocognitron :
日本科学家福岛邦彦提出了neocognitron,其目标是构建一个能够像人脑一样实现模式识别的网络结构从而帮助我们理解大脑的运作。他创造性的从人类视觉系统引入了许多新的思想到人工神经网络,被许多人认为是CNN的雏形。
Neocoginitron的主要贡献:

这么一看的话,基本上大部分现代CNN的结构在这个模型上都已经得到了体现。卷积运算的三个重要思想:稀疏交互、参数共享和等变表示也只有参数共享没有考虑到了。
.
.
.
(-1985-)BP for CNN :
1985年,Rumelhart和Hinton等人提出了反向传播(Back Propagation,BP)算法。BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。
具体来说,对于如下的只含一个隐层的神经网络模型:

BP神经网络的过程主要分为两个阶段,第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
.
.
.
(-1992-)Cresceptron :
在1992年,美籍华裔科学家翁巨杨发表了他的Cresceptron。虽然从结构上来看他的模型没有非常出彩之处,但是这篇论文中的两个trick却被广泛应用至今:
-
数据增强(Data Augmentation)
我们将训练的输入进行平移,旋转,缩放等变换操作然后加入到训练集中,一方面这可以扩充训练集,另一方面也提高了算法的鲁棒性,减少了过拟合的风险。 -
最大池化的提出
改变了千篇一律的用平均池化做downsampling的状况。
.
.
.
(-1998-)LeNet-5 :
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。
LenNet-5共有7层(不包括输入层),每层都包含不同数量的训练参数,如下图所示:
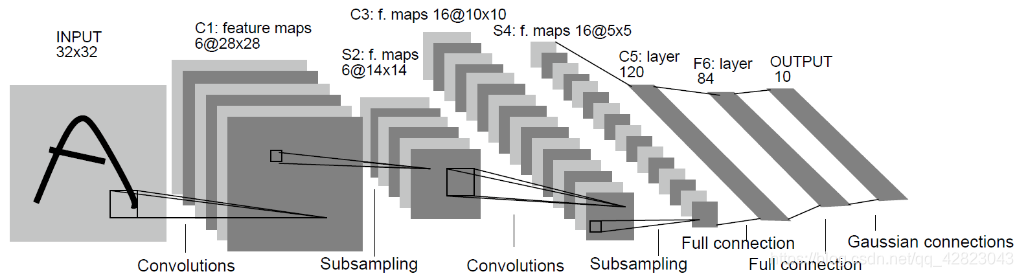
LeNet-5中主要有2个卷积层、2个下抽样层(池化层)、3个全连接层3种连接方式。 -
LeNet-5第一层:卷积层C1
C1层是卷积层,形成6个特征图谱。卷积的输入区域大小是5x5,每个特征图谱内参数共享,即每个特征图谱内只使用一个共同卷积核,卷积核有5x5个连接参数加上1个偏置共26个参数。卷积区域每次滑动一个像素,这样卷积层形成的每个特征图谱大小是(32-5)/1+1=28x28。C1层共有26x6=156个训练参数,有(5x5+1)x28x28x6=122304个连接。 -
LeNet-5第二层:池化层S2
S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息)。C1层的6个28x28的特征图谱分别进行以2x2为单位的下抽样得到6个14x14((28-2)/2+1)的图。每个特征图谱使用一个下抽样核。5x14x14x6=5880个连接。 -
LeNet-5第三层:卷积层C3
C3层是一个卷积层,卷积和和C1相同,不同的是C3的每个节点与S2中的多个图相连。C3层有16个10x10(14-5+1)的图,每个图与S2层的连接的方式如下表所示:
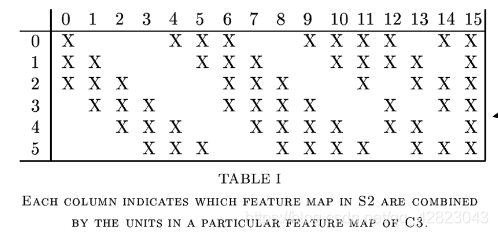
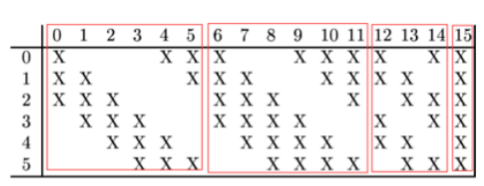
这种不对称的组合连接的方式有利于提取多种组合特征。该层有(5x5x3+1)x6 + (5x5x4 + 1) x 6 + (5x5x4 +1)x3 + (5x5x6+1)x1 = 1516个训练参数,共有1516x10x10=151600个连接。 -
LeNet-5第四层:池化层S4
S4是一个下采样层。C3层的16个10x10的图分别进行以2x2为单位的下抽样得到16个5x5的图。5x5x5x16=2000个连接。连接的方式与S2层类似。 -
LeNet-5第五层:全连接层C5
C5层是一个全连接层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。 -
LeNet-5第六层:全连接层F6
F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,该层的训练参数和连接数都是(120 + 1)x84=10164。 -
LeNet-5第七层:全连接层Output
Output层也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
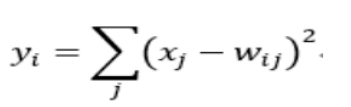
yi的值由i的比特图编码(即参数Wij)确定。yi越接近于0,则标明输入越接近于i的比特图编码,表示当前网络输入的识别结果是字符i。该层有84x10=840个设定的参数和连接。
以上是LeNet-5的卷积神经网络的完整结构,共约有60,840个训练参数,340,908个连接。一个数字识别的效果如图所示:
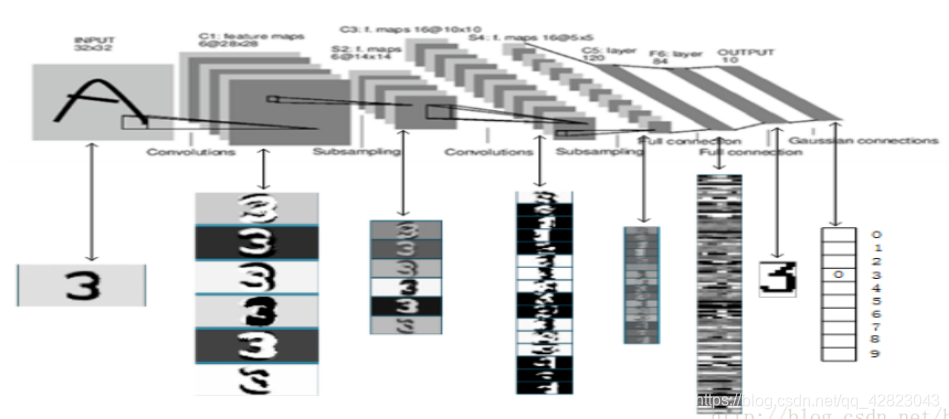
LeNet-5的架构基于这样的观点:图像的特征分布在整张图像上,以及带有可学习参数的卷积是一种用少量参数在多个位置上提取相似特征的有效方法。
在那时候,没有GPU帮助训练,甚至CPU的速度也很慢。因此,能够保存参数以及计算过程是一个关键的进展。这和将每个像素用作一个大型多层神经网络的单独输入相反。LeNet5阐述了那些像素不应该被使用在第一层,因为图像具有很强的空间相关性,而使用图像中独立的像素作为不同的输入特征则利用不到这些相关性。
但是这个模型在后来的一段时间并未能火起来,主要原因是要求机器性能较好,而且其他的算法像SVM也能达到类似的效果甚至超过。
LeNet5特征能够总结为如下几点:
1)卷积神经网络使用三个层作为一个系列: 卷积,池化,非线性;
2)使用卷积提取空间特征;
3)使用映射到空间均值下采样(subsample);
4)双曲线(tanh)或S型(sigmoid)形式的非线性;
5)多层神经网络(MLP)作为最后的分类器;
6)层与层之间的稀疏连接矩阵避免大的计算成本。
总结:
从1998年到2010年,神经网络处于孵化阶段,大多数人没有意识到他们不断增强的力量,与此同时其他研究者则进展缓慢。由于手机相机以及便宜的数字相机的出现,越来越多的数据可被利用。并且计算能力也在成长,CPU变得更快,GPU变成了多种用途的计算工具。这些趋势使得神经网络有所进展,虽然速度很慢,数据和计算能力使得神经网络能够完成的任务越来越有趣,之后一切变得清晰起来。
通过对LeNet-5的网络结构的分析,可以直观地了解一个卷积神经网络的构建方法,可以为分析、构建更复杂、更多层的卷积神经网络做准备。
LeNet的Keras实现:

系列传送门:
CNN发展简史——AlexNet(二)
CNN发展简史——VGG(三)
CNN发展简史——GoogLeNet(四)
CNN发展简史——ResNet(五)
CNN发展简史——DenseNet(六)