最近看的论文涉及到了下降方法,所以专门做一个总结,暂时先总结了随机梯度下降法,关于最速下降法和牛顿法以后有时间慢慢总结
本文总结的方法包括:
- 梯度下降法
- 随机梯度下降法
1.梯度下降法
在机器学习算法中,常常根据原始的模型构建出一个代价韩式,然后需要通过优化算法来寻找最合适的参数,使得代价函数的值最小。梯度下降法(Gradient Descent, GD)是最常用的优化方法。
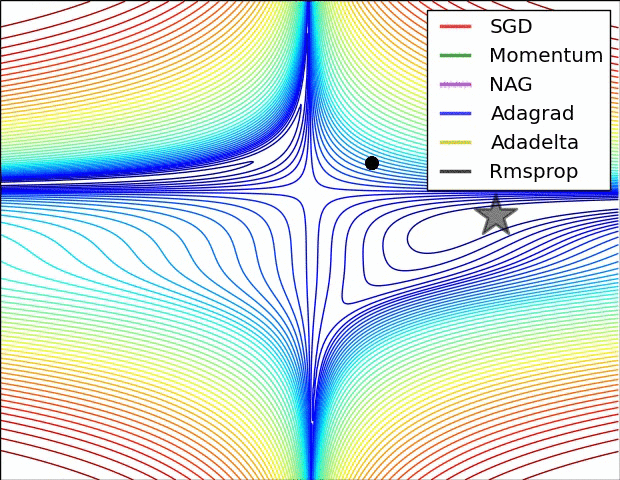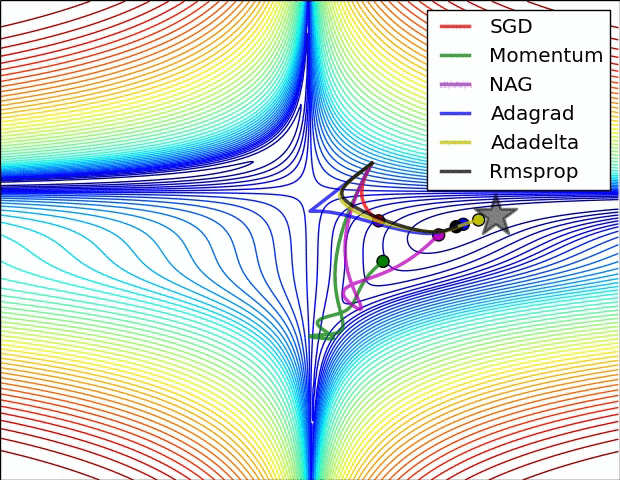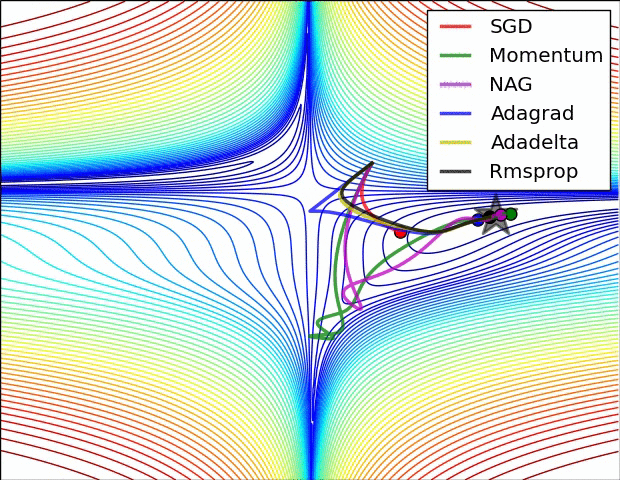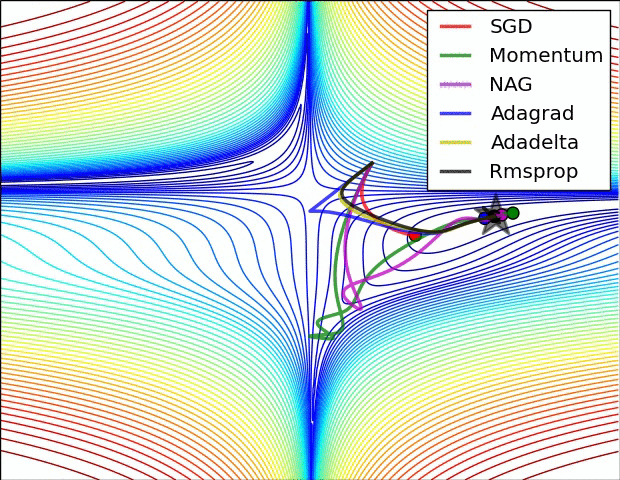

梯度下降我们要考虑三个问题:从哪里开始下降?往哪个方向下降?每一次下降多少?
机器学习常用的权重更新表达式为:
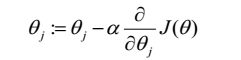
α是机器学习中的学习率,决定了下降的步长
下降的梯度方向则为
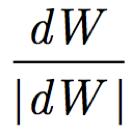
将这种下降方法应用于所有的参数,这种方法被叫做批量梯度下降法(BGD),这种方法每次迭代都考虑所有的样本,可以保证每次迭代均为全局最优,但是在大规模的数据中,这种方法消耗的算力极大,难以实现
2.随机梯度下降法(SGD)
随机梯度下降法可以解决批量梯度下降中计算量大的缺点
随机梯度下降(SGD)多用于支持向量机,Logistic回归等损失函数为凸函数的线性分类器的学习。也可以用于回归计算中。
随机梯度下降法的思想为:从样本中随机抽出一组,训练之后按梯度更新一次,然后再抽取一次,再更新一次。即:在更新每一个参数时都随机选择一个样本来进行计算更新。
参考资料:
[1]https://blog.csdn.net/abc13526222160/article/details/90812165
扫描二维码关注公众号,回复:
11286491 查看本文章
