归一化在画分布图的时候经常要用到。而在神经网络中使用归一化,我理解的还不够深刻,确切来说应该算是不理解吧。我也看了看几个人的博客,给分享一下:
Pytorch中 nn.BatchNorm2d() 归一化操作
上面的第二个链接已经吧这三节的内容都包括了。下面我只展示一些练习题中的错误:
1.
nn.BatchNorm2d(6)的含义是
全连接层的批量归一化,batchsize为6
卷积层的批量归一化,batchsize为6
全连接层的批量归一化,输出神经元个数为6
卷积层的批量归一化,通道数为6
答案解释
选项四:正确,nn.BatchNorm2d()表示卷积层的BN,参数为通道数。nn.BatchNorm1d()表示全连接层的BN,参数为输出神经元个数。
2.
关于BN层描述错误的是
卷积层的BN位于卷积计算之后,激活函数之前。
拉伸参数和偏移参数均为超参数。
预测时用移动平均估算整个训练数据集的样本均值和方差。
BN层能使整个神经网络在各层的中间输出的数值更稳定。
答案解释
选项1:正确,参考BN层的定义。
选项2:错误,拉伸参数和偏移参数为可学习参数。
选项3:正确,参考BN层的定义。
选项4:正确,参考BN层的定义。
3.
关于ResNet描述错误的是
残差网络由多个残差块组成。
在残差块中,输⼊可通过跨层的数据线路更快地向前传播。
可以通过不断加深网络层数来提高分类性能。
较普通网络而言,残差网络在网络较深时能更好的收敛。
答案解释
选项1:正确,参考ResNet的结构特征。
选项2:正确,参考ResNet的结构图。
选项3:错误,网络达到一定深度后再一味地增加层数反而会招致网络收敛变得更慢,准确率也变得更差。
选项4:正确,参考ResNet的结构特征。
4.
稠密连接网络过渡层中,1*1卷积层的主要作用是
减小通道数
增加通道数
引入非线性
代替全连接层
答案解释
选项1:正确,参考过渡层的作用。
5.
在稠密块中,假设由3个输出通道数为8的卷积层组成,稠密块的输入通道数是3,那么稠密块的输出通道数是
8
11
24
27
答案解释
输出通道数=输入通道数+卷积层个数*卷积输出通道数
其实错的还是蛮多的,还需要好好理解一下。
凸优化部分,我将他们的教程讲义复制过来,供以后用。
优化与深度学习
优化与估计
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
- 优化方法目标:训练集损失函数值
- 深度学习目标:测试集损失函数值(泛化性)
%matplotlib inline
import sys
sys.path.append('/home/kesci/input')
import d2lzh1981 as d2l
from mpl_toolkits import mplot3d # 三维画图
import numpy as np
def f(x): return x * np.cos(np.pi * x)
def g(x): return f(x) + 0.2 * np.cos(5 * np.pi * x)
d2l.set_figsize((5, 3))
x = np.arange(0.5, 1.5, 0.01)
fig_f, = d2l.plt.plot(x, f(x),label="train error")
fig_g, = d2l.plt.plot(x, g(x),'--', c='purple', label="test error")
fig_f.axes.annotate('empirical risk', (1.0, -1.2), (0.5, -1.1),arrowprops=dict(arrowstyle='->'))
fig_g.axes.annotate('expected risk', (1.1, -1.05), (0.95, -0.5),arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('risk')
d2l.plt.legend(loc="upper right")
<matplotlib.legend.Legend at 0x7fc092436080>
优化在深度学习中的挑战
- 局部最小值
- 鞍点
- 梯度消失
局部最小值
f(x)=xcosπx
def f(x):
return x * np.cos(np.pi * x)
d2l.set_figsize((4.5, 2.5))
x = np.arange(-1.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, f(x))
fig.axes.annotate('local minimum', xy=(-0.3, -0.25), xytext=(-0.77, -1.0),
arrowprops=dict(arrowstyle='->'))
fig.axes.annotate('global minimum', xy=(1.1, -0.95), xytext=(0.6, 0.8),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');


鞍点
x = np.arange(-2.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, x**3)
fig.axes.annotate('saddle point', xy=(0, -0.2), xytext=(-0.52, -5.0),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');
A=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢∂2f∂x21∂2f∂x2∂x1⋮∂2f∂xn∂x1∂2f∂x1∂x2∂2f∂x22⋮∂2f∂xn∂x2⋯⋯⋱⋯∂2f∂x1∂xn∂2f∂x2∂xn⋮∂2f∂x2n⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
e.g.
x, y = np.mgrid[-1: 1: 31j, -1: 1: 31j]
z = x**2 - y**2
d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 2, 'cstride': 2})
ax.plot([0], [0], [0], 'ro', markersize=10)
ticks = [-1, 0, 1]
d2l.plt.xticks(ticks)
d2l.plt.yticks(ticks)
ax.set_zticks(ticks)
d2l.plt.xlabel('x')
d2l.plt.ylabel('y');
梯度消失
x = np.arange(-2.0, 5.0, 0.01)
fig, = d2l.plt.plot(x, np.tanh(x))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)')
fig.axes.annotate('vanishing gradient', (4, 1), (2, 0.0) ,arrowprops=dict(arrowstyle='->'))
Text(2, 0.0, 'vanishing gradient')

凸性 (Convexity)
基础
集合
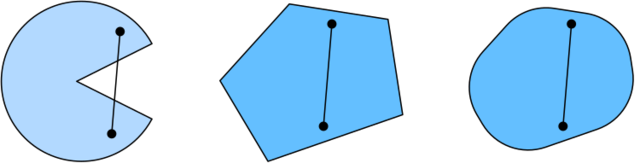
函数
λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
def f(x):
return 0.5 * x**2 # Convex
def g(x):
return np.cos(np.pi * x) # Nonconvex
def h(x):
return np.exp(0.5 * x) # Convex
x, segment = np.arange(-2, 2, 0.01), np.array([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):
ax.plot(x, func(x))
ax.plot(segment, func(segment),'--', color="purple")
# d2l.plt.plot([x, segment], [func(x), func(segment)], axes=ax)

Jensen 不等式
∑iαif(xi)≥f(∑iαixi) and Ex[f(x)]≥f(Ex[x])
性质
- 无局部极小值
- 与凸集的关系
- 二阶条件
无局部最小值
证明:假设存在 x∈X
是局部最小值,则存在全局最小值 x′∈X, 使得 f(x)>f(x′), 则对 λ∈(0,1]
:
f(x)>λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
与凸集的关系
对于凸函数 f(x)
,定义集合 Sb:={x|x∈X and f(x)≤b},则集合 Sb
为凸集
证明:对于点 x,x′∈Sb
, 有 f(λx+(1−λ)x′)≤λf(x)+(1−λ)f(x′)≤b, 故 λx+(1−λ)x′∈Sb
f(x,y)=0.5x2+cos(2πy)
x, y = np.meshgrid(np.linspace(-1, 1, 101), np.linspace(-1, 1, 101),
indexing='ij')
z = x**2 + 0.5 * np.cos(2 * np.pi * y)
# Plot the 3D surface
d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 10, 'cstride': 10})
ax.contour(x, y, z, offset=-1)
ax.set_zlim(-1, 1.5)
# Adjust labels
for func in [d2l.plt.xticks, d2l.plt.yticks, ax.set_zticks]:
func([-1, 0, 1])
凸函数与二阶导数
f′′(x)≥0⟺f(x)
是凸函数
必要性 (⇐
):
对于凸函数:
12f(x+ϵ)+12f(x−ϵ)≥f(x+ϵ2+x−ϵ2)=f(x)
故:
f′′(x)=limε→0f(x+ϵ)−f(x)ϵ−f(x)−f(x−ϵ)ϵϵ
f′′(x)=limε→0f(x+ϵ)+f(x−ϵ)−2f(x)ϵ2≥0
充分性 (⇒
):
令 a<x<b
为 f(x)
上的三个点,由拉格朗日中值定理:
f(x)−f(a)=(x−a)f′(α) for some α∈[a,x] and f(b)−f(x)=(b−x)f′(β) for some β∈[x,b]
根据单调性,有 f′(β)≥f′(α)
, 故:
f(b)−f(a)=f(b)−f(x)+f(x)−f(a)=(b−x)f′(β)+(x−a)f′(α)≥(b−a)f′(α)
def f(x):
return 0.5 * x**2
x = np.arange(-2, 2, 0.01)
axb, ab = np.array([-1.5, -0.5, 1]), np.array([-1.5, 1])
d2l.set_figsize((3.5, 2.5))
fig_x, = d2l.plt.plot(x, f(x))
fig_axb, = d2l.plt.plot(axb, f(axb), '-.',color="purple")
fig_ab, = d2l.plt.plot(ab, f(ab),'g-.')
fig_x.axes.annotate('a', (-1.5, f(-1.5)), (-1.5, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('b', (1, f(1)), (1, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('x', (-0.5, f(-0.5)), (-1.5, f(-0.5)),arrowprops=dict(arrowstyle='->'))
Text(-1.5, 0.125, 'x')

限制条件
minimizexf(x) subject to ci(x)≤0 for all i∈{1,…,N}
拉格朗日乘子法
L(x,α)=f(x)+∑iαici(x) where αi≥0
惩罚项
欲使 ci(x)≤0
, 将项 αici(x) 加入目标函数,如多层感知机章节中的 λ2||w||2
投影
ProjX(x)=argminx′∈X∥x−x′∥2
练习题目:
1.
优化方法的目标是最小化_____损失函数值,深度学习的目标是最小化_______损失函数值。
训练集,测试集
训练集,训练集
测试集,测试集
测试集,训练集
答案解释
详见视频00:05-00:33
2.
________属于优化在深度学习中面临的挑战。
局部最小值
鞍点
梯度消失
以上都是
答案解释
详见视频2:06-7:40
3.
以下对多维变量的鞍点描述正确的是:_______。
鞍点是对所有自变量一阶偏导数都为0,且Hessian矩阵特征值有正有负的点
鞍点是对所有自变量一阶偏导数都为0,且Hessian矩阵特征值都为0的点
鞍点是对所有自变量一阶偏导数有正有负,且Hessian矩阵特征值都为0的点
鞍点是对所有自变量一阶偏导数有正有负,且Hessian矩阵特征值有正有负的点
答案解释
详见视频04:26-05:14
4.
假设A和B都是凸集合,那以下是凸集合的是:________。
A和B的交集
A和B的并集
A和B的交集和并集都是
A和B的交集和并集都不是
答案解释
详见视频08:30-09:37
5.
有限制条件的优化问题可以用什么方法解决:_______。
拉格朗日乘子法
添加惩罚项
投影法
以上都是
答案解释
详见视频21:26-23:40
随机梯度下降:
1.
关于梯度下降描述正确的是:_______。
梯度下降是沿梯度方向移动自变量从而减小函数值。
梯度下降学习率越大下降得越快,所以学习率越大越好。
梯度下降学习率越大越容易发散,所以学习率越小越好。
局部极小值是梯度下降算法面临的一个挑战。
答案解释
选项1: 错误,梯度下降是沿着梯度的反方向移动自变量从而减小函数值的。
选项2: 错误,详见视频4:30-5:20。
选项3: 错误,详见视频4:02-4:30。
选项4: 正确,详见视频5:30-6:05。
2.
关于牛顿法说法错误的是:______。
牛顿法相比梯度下降的一个优势在于:梯度下降“步幅”的确定比较困难,而牛顿法相当于可以通过Hessian矩阵来调整“步幅”。
牛顿法需要计算Hessian矩阵的逆,计算量比较大。
相比梯度下降法,牛顿法可以避免局部极小值的问题。
在牛顿法中,局部极小值也可以通过调整学习率来解决。
答案解释
选项1:正确,详见自适应方法中牛顿法的介绍。
选项2:正确,详见自适应方法中牛顿法的介绍。
选项3:错误,详见视频14:28-14:52。
选项4:正确,详见视频14:52-15:20。
3.
随机梯度下降的时间复杂度是_____。
O(1)\mathcal{O}(1)O(1)
O(n)\mathcal{O}(n)O(n)
O(logn)\mathcal{O}(logn)O(logn)
O(n2)\mathcal{O}(n^2)O(n2)
答案解释
选择选项1,详见视频20:40-21:30。
4.
关于动态学习率的说法,错误是_______。
在最开始学习率设计比较大,加速收敛
学习率可以设计为指数衰减或多项式衰减
在优化进行一段时间后可以适当减小学习率来避免振荡
动态学习率可以随着迭代次数增加而增大学习率
答案解释
前面三种说法都正确,详见23:30-24:40。选项4错误,应该随着迭代次数增加减小学习率。
5.
可以通过修改视频中 train_sgd 函数的参数_______来分别使用梯度下降、随机梯度下降和小批量随机梯度下降。
batch_size
lr
num_epochs
都不可以
答案解释
选项1正确,三者的区别在于每次更新时用的样本量。