大多数深度学习的算法多涉及某种形式的优化。优化指的是改变x以最小化或者最大化某个函数f(x)的任务。我们把最大化或者最小化的函数叫做目标函数(objection function),我们对其进行最小化时,也把它称为代价函数(cost function)或损失函数(loss function)或误差函数(error function)。
梯度下降法分类:
1. 批量梯度下降法 :
批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新。
2. 随机梯度下降法:
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法(Stochastic Gradient Descent,简称SGD)正是为了解决批量梯度下降法这一弊端而提出的。
3. 小批量梯度下降法:
有上述的两种梯度下降法可以看出,其各自均有优缺点,那么能不能在两种方法的性能之间取得一个折衷呢?即,算法的训练过程比较快,而且也要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷。
如果想更加深入了解有关这三种梯度下降法可以参考这位作者的一篇博客
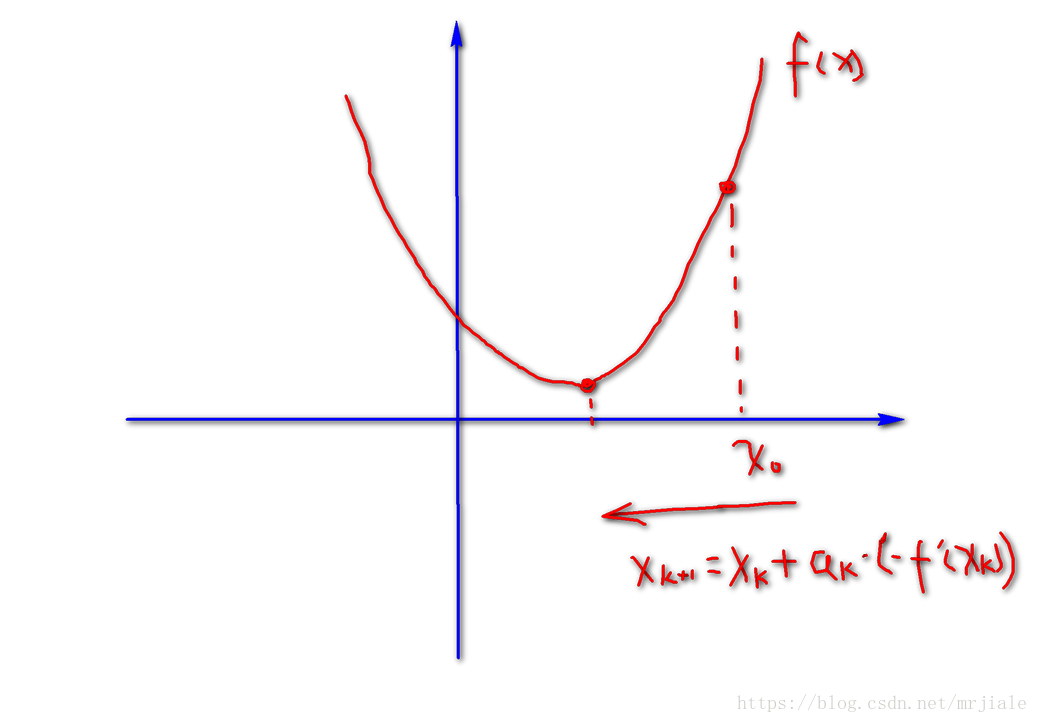
其实梯度下降法很简单理解,就是如果知道一个初始值
,我们从现在开始就不停地把这个初始值优化为函数的最小值(
表示学习率)
如果想更加深入了解有关梯度下降算法可以参考这位作者的一篇博客