A New Target-specific Object Proposal Generation Method for Visual Tracking
这篇论文提出了一种 target-specific object proposal generation (TOPG) method
并且将这种proposal generation方法应用在Visual Tracking中,取得了特别好的效果。
出发点:
目前的object proposal方法,可以分为两种:
① 一种是基于图像分割的(这里面会涉及到很多颜色方面的信息);但这种方法的计算复杂度很高,而且这种方法往往是在寻找一个完整的物体(当物体被遮挡时就不适用了)。并且在处理灰度图像时不适用。代表:Selective Search 仅仅利用color cue
② 另一种是基于边缘信息进行滑动窗口的得分计算。这种方法虽然计算速度较快,但是在object的边缘不清晰时(例如图像出现motion blur, low contrast等情况时),对score的计算也会受到影响。代表:EdgeBoxes 仅仅利用edge cue
color cue和edge cue这两种cue对proposal的产生其实都是很重要的。而且,在Visual Tracking这个领域,涉及到视频帧,motion blur, low contrast, occlusion的现象时有发生,上述的经典算法就不适用了。

所以,作者提出了一种集成了color cue和edge cue的target-specific object proposal的方法。

作者联合color cue和edge cue的思路:

具体流程:
一、generate object proposals
对于一张原始图像(a region surrounding the target),统计foreground和background的颜色直方图。

当然,为了适应target和背景外观以及颜色的变化,需要对直方图进行更新(每个k帧更新一次):(实验中设为了30,有详细的实验过程,取30最好)

这样在test image上:(这是一个典型的涉及到运动模糊的图像)

利用概率统计得到每个像素属于前景的概率:
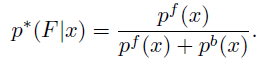
得到颜色直方图的概率图:

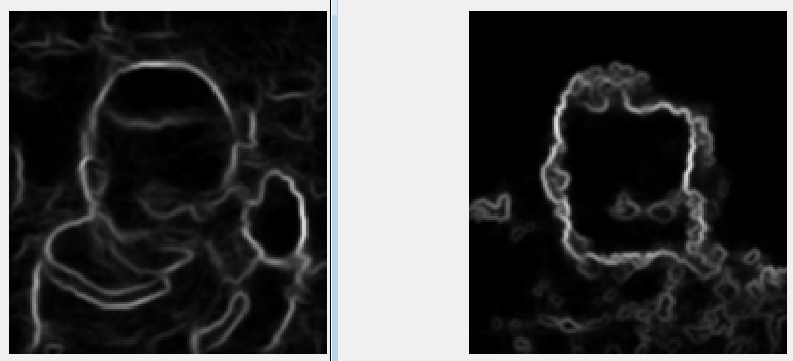
可以清楚的看到,对于原图像,利用边缘检测基本是检测不到边缘的。此时利用edgebox基于这些边缘再去产生proposal,大部分也就是不正确的。
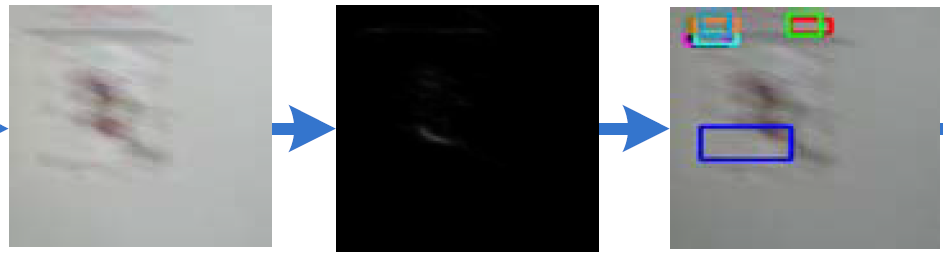
但是如果对颜色直方图的概率图进行边缘检测,却可以得到比较满意的效果。而且,因为其利用到了target的信息,所以是可以有效地突出terget的。这样,我们依据边缘检测图,利用edgebox的proposal产生方法就能得到一些high-quality object proposals。

下面这个图可以更加清楚的表现分别利用原始图像和颜色直方图概率图进行边缘检测得到边缘图的差异。


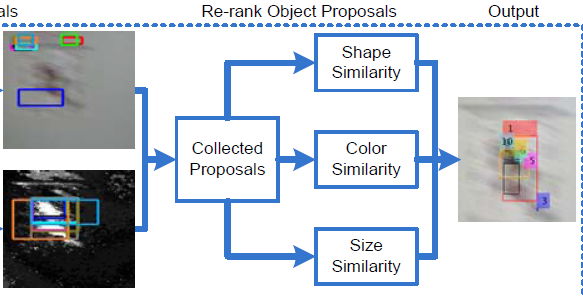
二、re-ranking
将两种边缘图得到的proposals看成是proposal的候选池,这些proposal可能存在冗余情况,所以,我们需要对这些proposal进行重排,得到高质量的proposal。这三种affinity涉及到了object proposal和target region的三种联系。
① shape affinity
object proposal和target region在edgebox的score得分上的差异。
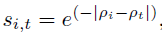
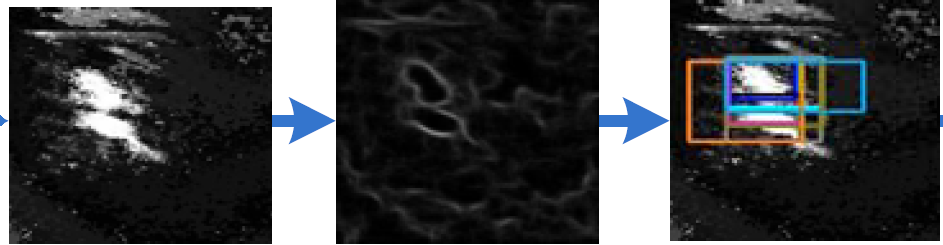
② color affinity
每个object proposal中颜色概率之和的平均值作为这个object proposa的color value。与target region的color value的差值作为color affinity。
③ size affinity
长宽上的联系。
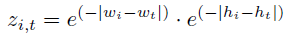
三种联系的组合用于衡量每个object proposal。保留前m个作为最终得到的proposal。
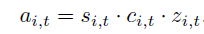
这个过程可以表示为:
以上就是本篇论文中得到proposal的过程。
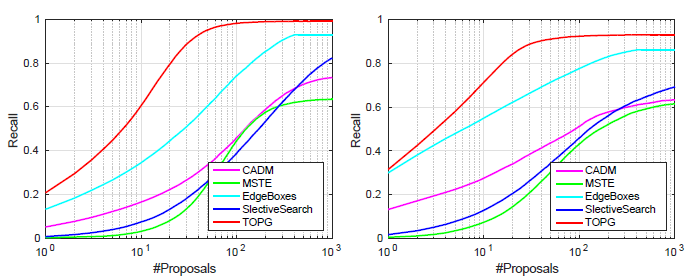
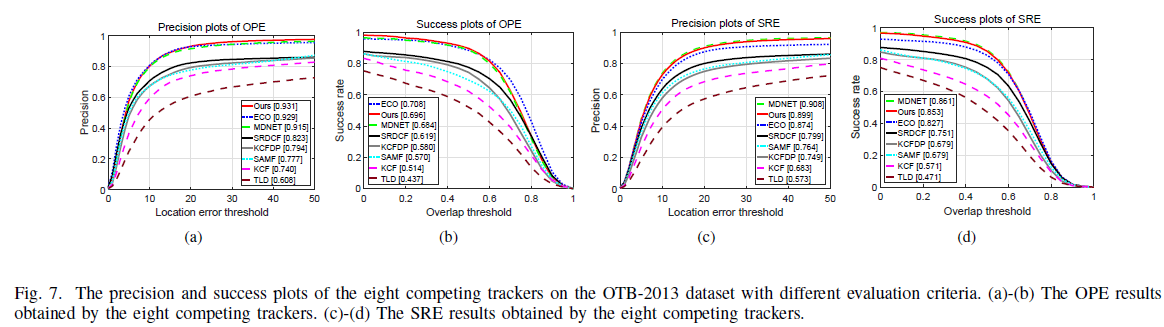
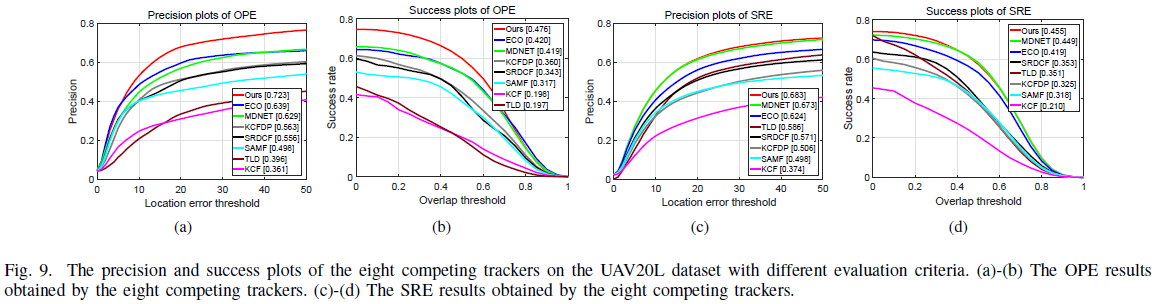
实验表明这种Target-specific Object Proposal Generation Method 可以在在目标跟踪数据集(OTB-2013、UAV20L)上取得很好的racall,说明确实更加 target-specific,而且在motion blur, low contrast, deformation, occlusion发生时,对terget相关proposal的产生也更加有效。
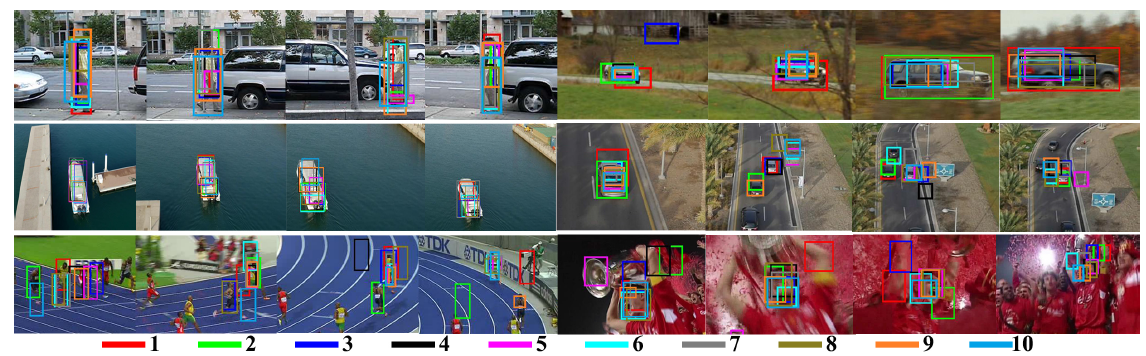
应用在tracking中:
训练过程:
利用VGG-M net,从保留的object proposal中提取feature,然后利用这些feature来fine-tune CNN classifier。为啥要fine-tune呢?

既然要fine-tune,就会涉及到正负样本:
这里的正样本就是和上一帧的target region的IOU>0.7的object proposals。
这里的负样本就是和上一帧的target region的IOU<0.5的object proposals。
不过正样本的数量可能会比负样本的数量少很多,这是典型的类别不均衡的问题。这样正负样本极不均衡的样本集对分类器进行训练,会导致分类器不具有更有效的区分能力。所以,在上一帧target region的周围,作者采用了加高斯噪声的方式来得到更多的正样本。(100个)

测试过程:
将TOPG得到的object proposal作为目标的候选,利用前面学习到的CNN classifier来计算这些object proposal各自的probability score,score最高对应的proposal作为当前帧的预测结果。
在OTB50以及UAL20L上的评估结果:
联想:
作者提出的这种从颜色直方图概率图中提取边缘的方法可以借鉴一下:

我的尝试:
第一帧的surrouding region:
对它提取前景背景的颜色直方图之后:
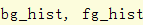
将这个颜色直方图用于当前帧来得到颜色直方图概率图:(黑白显示和彩色显示)
针对原图patch_padded和这个颜色直方图概率图likelihood_map:

分别提取边缘图:
利用edgebox分别提取proposal:(每张图中仅提取10个)

再举几个例子:
(每张图中生成60个proposal,下图画出的是第50-60个proposal)

这个bolt的数据本身比较复杂,之前做过一个实验,对于原图进行边缘检测以及edgebox生成proposal,在生成1000个proposal的情况下,还是没能很好地hit the target。但是利用颜色直方图概率图进行边缘检测,并进行edgebox生成proposal,在前前100个proposal中就大致出现了可以比较好地hit target的proposal。
(每张图中生成10个proposal)
