前言
- 这是篇从语音生成3d landmarks的文章, 从题目中可以看出来作者提出的是对背景噪音有抵抗力的脸部生成。
贡献如下:
- 生成3维人脸landmarks ,而不是二维的
- 取代了MFCC和它们的时间倒数,而是直接把原始波形输入到网络中
- 提出了新的网络结构, 用卷积来取代LSTM改善原始波形输入的结果
- 提出了一种抗噪的训练方法, 在特征层面上纳入了语音增强的思想,以提高系统对非稳态背景噪声的鲁棒性。
方法
预处理
- face landmark extration
使用dlib提取2d点, 然后使用论文How far are we from solving the 2D&3D face alignment problem中的方法变为3d点
- face landmark alignment
提取的原始坐标是以像素坐标为单位的, 可以位于不同的位置, 比例, 方向上, 这些变化对于训练是不利的, 因为它们和输入语音无关, 为了最小化这些变化, 使用Procrustes analysis来对齐3D landmarks, 这是创建active shape model(ASMs) 和active appearance models(AAMs)的常见做法.
下图第二行是对齐之后的.

- face landmark identity removal
不同说话人有不同的面部形状, 最好能去除身份的变化。
对于每个landmarks 序列, 检测一个包含closed mouth(嘴部闭合)的参考帧, 这种检测是通过thresholding the distance between the upper lip and lower lip coordinates (阈值化上唇和下唇坐标之间的距离)来实现的。
然后计算序列中每帧landmark坐标和这个参考帧的偏差(deviations), 然后把这些偏差施加到所有身份的所有序列的模板face上(impose these deviations onto a template face across all sequences of all identities.)这个模板face是所有identities中闭着嘴的对齐的面部平均值。
下面是3d landmarks 坐标的表示:
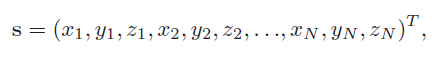
身份去除工作可以表示为:

S I R S_{IR} SIR代表身份去除后的face shape, S C M S_{CM} SCM 是一个从视频中自动选取的嘴部闭合的face frame, S T S_T ST 是template face, 下图第三行展示了去除身份后的图
- Active shape model(ASM)
ASMs介绍
其实有些类似人脸3DMM模型, 就是平均值加上权重*PCA降维后的向量.
公式如下:

s u s_u su 是mean shape vector, w = [ c 1 , . . . . . c P ] w=[c_1, .....c_P] w=[c1,.....cP] 是一个包含权重的向量, S = [ s 1 , . . . . . s P ] S=[s_1, .....s_P] S=[s1,.....sP] 是一个包含特征向量的的矩阵. P是PCA的主成分, P<N
- Data Augmentation
3D landmarks没有变化, 对于语音输入, 执行数据增强, 以提高系统在音高和声响变化方面(pitch and loudness variations)的稳健性
- 增强不是训练开始之前进行的, 而是在训练迭代期间执行的, 对于每个training batch里的每个sample, 随机选取是否使用原始样本还是增强样本 (有点teaching forch的感觉hhhh), 如果是增强数据, 则:
- We first pitch shift the sample by one or two semitones up or down.
我们首先将样本的音高向上或向下移动一个或两个半音。 - We then apply a gain factor to the amplitude of the sample between −12 dB and 6 dB with a 3 dB granularity
然后我们在-12dB和6dB之间的样本振幅上应用一个增益因子,粒度为3dB。
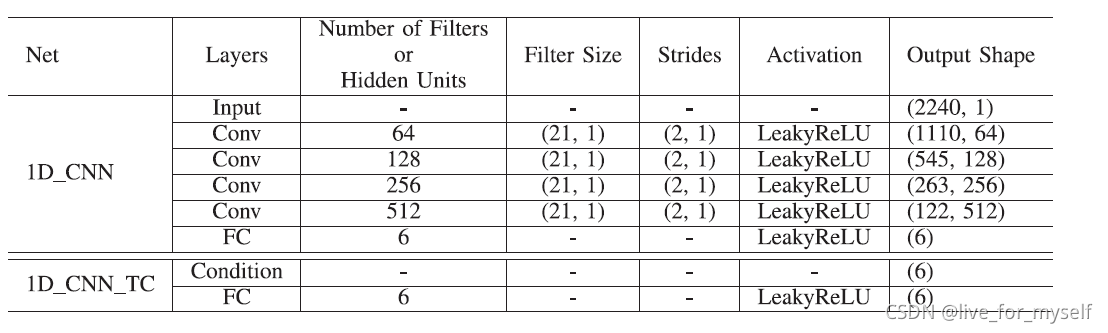
网络结构
深神经网络 (DNN) 接受一帧(280毫秒)的原始波形作为输入, 并输出该帧的ASM权重。
网络有四个带有1D filter kernals的卷积层对原始波形进行操作。filter的数量随着时间尺寸的缩小而增加。使用strides的方式来处理每个卷积层,这样可以将时间步长减半。每个卷积层之后是LeakyReLU激活,斜率为0.3。还有一个随机丢弃20%的dropout层, 最后一层是一个全连接层,输出ASM权重。
网络如下图:
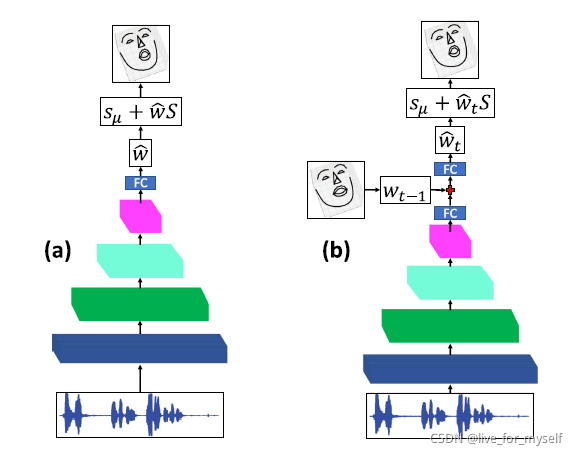
左边和右边的网络结构是相同的, 不同在于右边的接受前一帧的ASM权重作为条件来执行时间约束(enforce temporal constraint), 声音经过4个卷积层然后是fc
- 关于时间约束:
为了实现生成帧之间的平滑过渡,我们在网络结构中进一步增加了一个时间约束。它把前一帧的ASM权重作为条件,以获得更平滑的结果。该条件被concatenated到中间张量紧随全连接层之后,我们再增加一个fc, 像是上图的b结构.
我们在第四节讨论这两种模型之间的权衡。
我们将我们提出的方法称为1D_CNN,将时间约束的版本称为1D_CNN_TC。
最小化预测ASM权重和真实ASM权重的L1 loss, 下面是单个样本的损失:
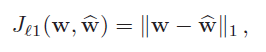
训练时取所有训练样本的平均.
噪声适应性训练 Noise-Resilient Training
为了使系统对噪音有鲁棒性,我们提出了一种新颖而简单的抗噪音训练方法。其理念是匹配从干净和嘈杂的语音中获得的中间特征,因为在理论上,它们包含相同的语音信息,因此提取的feature理论上是相同的。结构如下图:
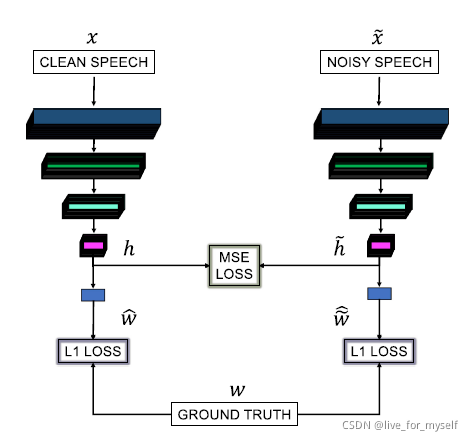
clean features h 是从clean speech x中提取的, corrupted features h ~ \tilde h h~ 是从corrupted speech x ~ \tilde x x~中提取的. 这两个提取网络结构是相同的, 除了两个网络的ASM 系数损失, 我们还加入h 和 h ~ \tilde h h~之间的加权MSE loss, 损失函数如下:
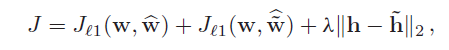
λ 是权重系数
W ~ ^ \widehat {\widetilde W} W 是从corrupted speech x ~ \tilde x x~ 获得的ASM权重
系统概述
在推理过程中,我们的系统利用了一个speech buffer,作为先进先出(first-in-first-out)(FIFO)队列。首先,语音缓冲器
被初始化为零。当系统收到新的语音数据时,它被push到speech buffer,然后网络预测出下一帧的权重。语音没有经过预处理;原始语音被直接送入神经网络。预测的权重被转换为三维地标点,使用下面式子:
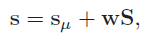
对于1D_CNN_TC网络,系统利用了另一个缓冲器,称为conditioning buffer, 用于存储最后一帧。
conditioning buffer被初始化为模板脸部形状权重(The conditioning buffer is initialized with the template face shape weights)。
系统概述图如下:
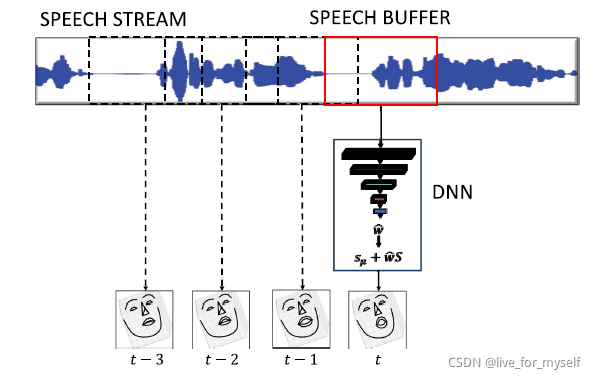
从320ms(frame length)的音频中, 每40ms(frame hop size)产生一个talking face, t代表时间
实验
单人视频选择奥马巴, 多人是GRID, 每个视频3s 75帧, 采样率44.1kHz, 把音频降采样到8kHz(down-sample the audio to 8 kHz which is a typical sampling rate for speech signals in telecommunication), 92% 训练 8% 验证
实施细节
我们的系统被训练成生成25FPS的视频,即系统每40毫秒产生一个说话的脸。在输入语音中包含了上下文信息, 这里作者concatenate 3 frames from past and future, 共7帧
对于8kHz的语音信号, 一个40ms窗口包含320个数据点, 输入speech size变为7*320=2240, 参见下表的Input