看论文时查的知识点
前馈神经网络就是一层的节点只有前面一层作为输入,并输出到后面一层,自身之间、与其它层之间都没有联系,由于数据是一层层向前传播的,因此称为前馈网络。
BP网络是最常见的一种前馈网络,BP体现在运作机制上,数据输入后,一层层向前传播,然后计算损失函数,得到损失函数的残差,然后把残差向后一层层传播。
卷积神经网络是根据人的视觉特性,认为视觉都是从局部到全局认知的,因此不全部采用全连接(一般只有1-2个全连接层,甚至最近的研究建议取消CNN的全连接层),而是采用一个滑动窗口只处理一个局部,这种操作像一个滤波器,这个操作称为卷积操作(不是信号处理那个卷积操作,当然卷积也可以),这种网络就称为卷积神经网络。
目前流行的大部分网络就是前馈网络和递归网络,这两种网络一般都是BP网络;深度网络一般采用卷积操作,因此也属于卷积神经网络。在出现深度学习之前的那些网络,基本都是全连接的,则不属于卷积网络的范围,但大部分是前馈网络和BP网络。
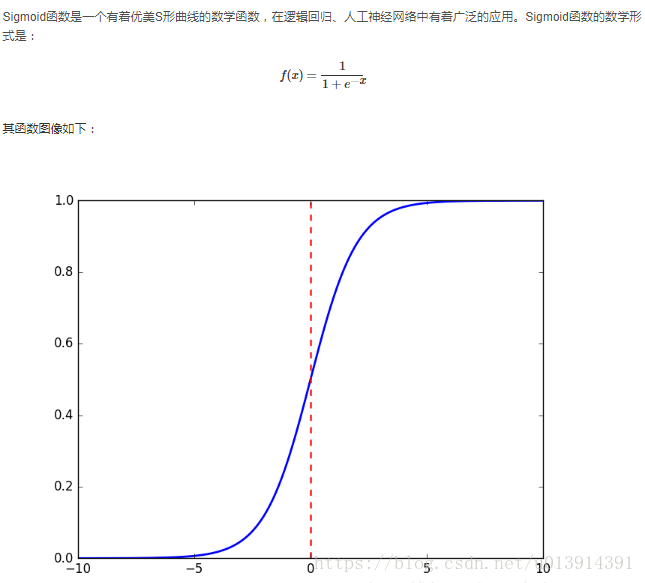
sigmoid函数
softmax函数
原文链接:https://www.cnblogs.com/liuyu124/p/7332476.html

论文
摘要abstract
DNNs很强大,在许多学习任务都表现卓越。DNNs在很多有大量训练标签的数据集上表现良好,但是无法完成将序列映射到序列的任务。在这篇论文中,作者提出了一种通用的端到端序列学习方法,它对序列结构的假设最小。
论文亮点
- 使用多层(原文说是4层)的LSTM将input sequence(不定长度的输入) 映射到一个固定维度的向量。然后使用另外1个LSTM将这个向量解码输出。
- 使用本文模型将WMT-14数据集用于翻译英语到法语的任务中,BLEU(BLEU是一种用于评估从一种自然语言到另一种自然语言的机器翻译的质量的算法)得分34.8分。
- 对词序敏感。同一个句子的主被动语态包容性很好。
- 发现颠倒输入的句子顺序可以显著提高模型的性能。ex:一个句子是abc,在传入模型的顺序是cba 。据作者讲会引入一些短期依赖,从而使模型性能更好。
1引言introduction
- DNNs很灵活也很强大,但是它的输入和输出输出长度必须固定。
- 使用LSTM来解决DNNs对输入长度必须固定的问题(可变长度的输入语句映射到一个固定维向量表示)思想是:使用两个LSTM。一个LSTM用于读取输入序列,每次读取一个时间步长,获得大的固定维度向量,然后使用另一个LSTM从该向量中提取输入序列。第2个LSTM本质上就是循环神经网络,只不过受输入序列的限制(依靠第一个LSTM)。
- LSTM在长时间依赖性的数据上的成功,举例。
2 模型 The model

1. rnn也可以使用两个rnn来将变长的input sequence转换到固定维度的向量,但是由于长期依赖关系,训练RNN很困难。所以不选用RNN。
2. 文章所使用的模型:a.两个LSTM(一个用于输入序列,另一个用于输出序列)。b.4层LSTM(深的LSTMs明显优于浅的LSTMs)。 c. 交换了input sentences的词序(这样使a与α,更近,b与β更近,当然使c与 γ更远,但是据作者将c与 γ更远,对模型没有影响)交换词序后,令模型性能更好。d.使用EOS(end-of-sentences)作为句子结束的标志。
3实验 experiments
数据集 Dataset details
- 使用了固定的词汇表。160000个最常用的源语言单词(被翻译的语言,在本文中为英文)。80000个常用的目标语言单词(翻译后的语言,在本文为法语)。
- 不在单词表的单词用UNK标记替换。
解码和重新排序 Decoding and Rescoring
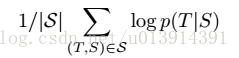
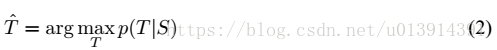
解码:
- T correct translation
- S source sentence
S 训练集
最大化对数概率。当训练完成后,根据公式2寻找最可能的翻译。一些细节部分暂时还看不大懂==
转换输入句子的顺序 Reversing the Source Sentences
ex: input sentence:abc,传入模型的顺序是cba。作者认为建立了更多的短期依赖。
训练详情Training details
4层LSTM,每层1000个单元
词向量维度是1000维
输入词典大小是160,000,输出词典大小是80,000
LSTM的初始参数服从[-0.08,0.08]的均匀分布
用随机梯度下降算法,没有momentum,开始学习率为0.7,5 epochs之后,每个epoch之后学习率降低一半。
batch是128
每次training batch 之后,计算s=||g||2, g 是梯度除以128,如果s > 5, 令 g = 5g/s。
不同的句子长度不同,为了降低计算量,一个batch中的句子的长度差不多相同。
用8个GPU同时进行处理
模型分析
- 在长句的翻译中表现良好。
- 主动语态和被动语态包容性好。
- 将input sentences映射到一个固定维度的向量上。