1、怎么将CNN用在特定的任务中
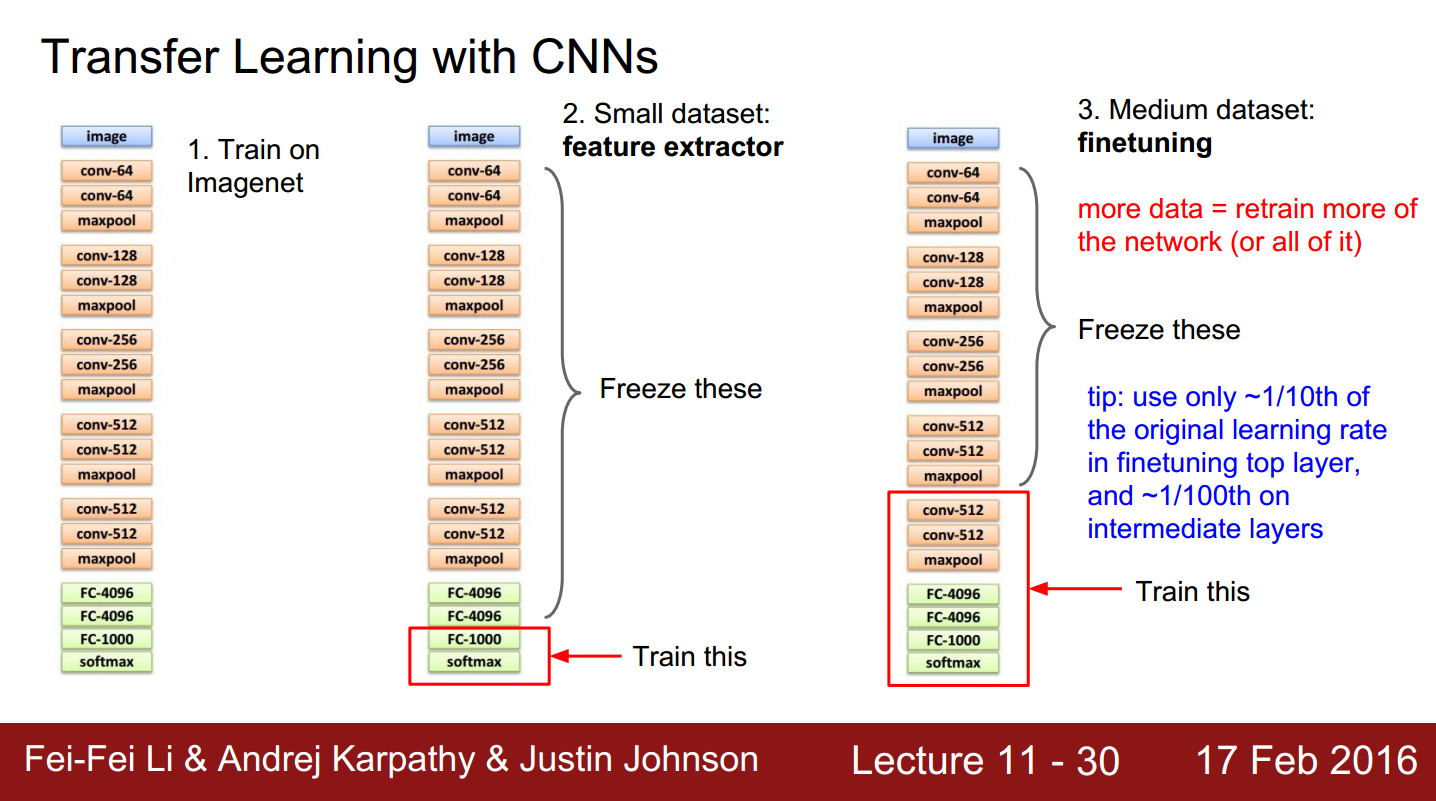
图1. 将CNN用在特定的任务中
众所周知CNN的使用往往需要大量的训练样本,但是我们在很多特定任务中是没法获得像imageNet那样庞大的样本库,因此如何在小样本中使用CNN是一个难题。后来很多学者经过研究发现CNN的模型有很好的泛化性能,即在大样本库中训练好的CNN模型对于特定的任务也有不错的性能。一些学者根据这个特性提出了fine-tune的方法,
如图1所示。我们首先在big dataset上训练好CNN模型,然后用我们特定任务中获得的样本对CNN模型进行微调(fine-tune),上图中最左侧是经典的CNN模型VGGnet,我们用imagenet数据库对其训练(其实是别人训练好,我们直接把训练结果拿来用);
如果我们的训练样本数量不少,如上图右侧部分所示,那么我们可以用自己的样本更新更多的层,比如上图右侧中,不仅更新了全连接层,还更新了pooling层以及卷积层。
2、将CNN用在visual tracking中
目前用CNN做跟踪的方法主要有两种,一种是利用已经训练好的CNN模型提取目标特征,再采用传统的目标跟踪方法进行跟踪;一种是利用已知的跟踪目标样本来对CNN模型进行fine-tune,将最终训练的结果用于跟踪。
第一种方法本身具有局限性,CNN提取到的特征具有很强的语义信息,但是空间信息却很缺乏。第二种方法由于跟踪中样本数量太少,确定的样本往往只有第一帧的目标,因此fine-tune出的新模型很容易出现过拟合。
为缓解上述问题,作者提出了sequential training method,将CNN中每个卷积核对应的特征map输出看成是一个基学习器,将CNN的训练过程看成是一个集成学习的过程,然后用集成学习的方法得到最终的跟踪分类器。
3、集成学习(ensemble learning)
说到集成学习,可能有些人听起来会觉得陌生,但是提到adaboost,相信很多人都听过,而adaboost就是集成学习中的一个经典算法。中心思想是将最终的高级分类器看成是一些低级(基)分类器的加权组合。即:
其中
类似于一般的分类算法中的损失函数,集成学习中用
集成学习的一大好处就是能够增加分类器的表达能力(泛化能力),但是我们该如何选择基分类器呢?如果基分类器之间非常相似,那最终的集成分类器则不具有较好的多样性,因此在集成学习中用
各个基分类器与最优基分类器的相关性。当
这里的
有了上述改进的基分类器损失表达形式,则选出的新的基分类器的参数为:
通过这种方法能够有效的增加基分类器的多样性,提升分类器的泛化性能。
4、用序贯集成学习方法在线训练CNN
CNN-E来表示预训练(pre-trained)的卷积神经网络,这个预训练的图像能够将输入的RGB图像转化为512*7*7的输出特征图X。
CNN-A表示在线更新的卷积神经网络。这是一个两层的卷积神经网络,采用ReLU作为非线性激活函数。CNN-A以CNN-E的输出X作为输入,并输出最终的特征图。整个模型如下图:
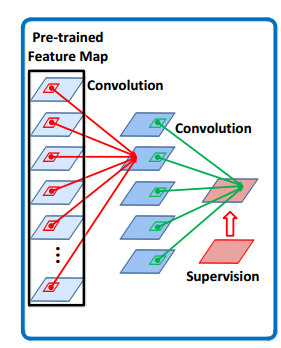
图2. STCT模型图
其中的pre-trained feature map是VGGnet的输出,输出的特征是512个通道,7*7大小的特征图,即512*7*7。

图3. VGGnet结构图
在线更新的CNN共有两层卷积层,第一层采用大小为5*5的卷积核,生成100*3*3的结果,第二层采用3*3的卷积核,生成一个通道的输出结果,代表目标的位置。
所以最后的输出,即卷积输出结果可以表示成如下形式:
根据集成学习的形式,作者讲上述的卷积的输出
所以,在线的更新CNN-A就可以等价的看成更新每一个基分类器,并且序贯的选择最优基分类器来构成最终的分类器。
5、怎么训练级联分类器,以及在线更新每个基分类器
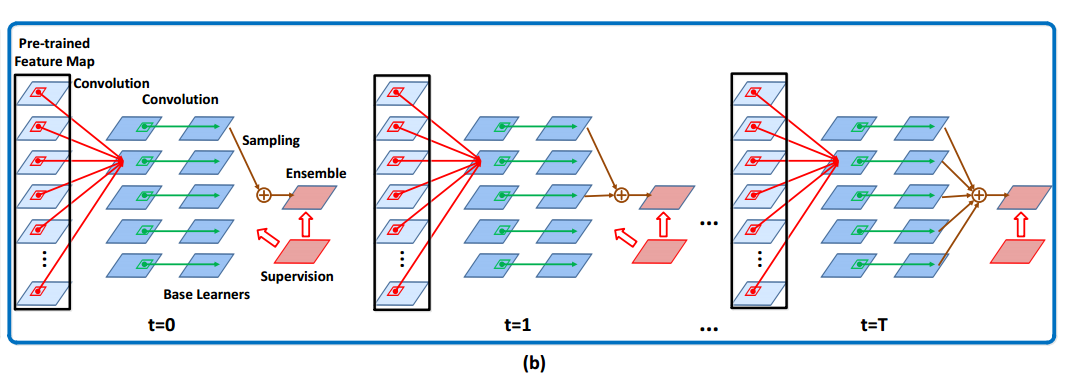
图4. STCT实现流程图
- 1、随机初始化每个基分类器,并用第一帧的目标图像对每个基分类器用SGD进行更新
- 2、从这些基分类器中选出训练误差最小的分类器,将这个基分类器放入ensemble set集合
ε 中,并将剩余的C1−1 个基分类器放入候选集合ξ 中。ensemble set中基分类器的结合看成是集成分类器,可以写成如下形式:
F(X;ε)=1|ε|∑γi∈εf(X;γi) - 3、在第t帧,当获得新的训练样本
Xt 以及其对应的标签Yt 后,仍旧采用SGD和如下的损失函数对ε 中的分类器F(X;ε) 进行参数更新:Lε=L(Yt,F(Xt;ε) 。对于候选集合ξ 中的每一个基分类器也都各自的采用如下损失函数和SGD进行更新:Lξ(Yt,f(Xt;γj))=L(Yt,f(Xt;γj)+ηF(Xt;ε)) 4、当训练误差
Lε 高于我们给定的一个阈值,并且候选集合ξ 不为空,那么在候选集合中选出训练误差最小的一个基分类器,将其放入ensemble set中,同时从候选集中删除。经过上述训练过程,最终训练出的CNN的每个通道都是采用不同的损失函数训练而成,因此整个CNN模型更加具有多样性和较好的泛化性能。
6、带有掩膜的卷积层
dropout是神经网络中一种常见的正则方法,其原理是在全连接层随机的让一些激活神经元的输出为0。但是这种正则化方法不适用于卷积层,而本文使用的是两层卷积层,因此没法采用dropout方法防止过拟合。后面又有spatial dropout方法,这种方法是直接让卷积层的某个通道全为0,可以适用于卷积层,但是作者通过实验发现这种方法有时候会导致发散。
为了提高模型的泛化能力,作者提出在卷积层后面加上一层二值掩膜层(mask layer),掩膜层的空间大小与卷积层的空间大小一致,其在初始阶段随机初始化,并且在后面的在线训练过程中不发生改变。
卷积层与掩膜层相乘的结果如下:
7、跟踪中的具体实现
一、在初始化阶段:
1、采用欧氏距离作为损失函数对基分类器
其中
根据上述式子,计算出每个初始的基分类器的损失值后,选择损失值最小的一个基分类器,将其取出,放入ensemble set中,其余的放入候选集合中。
2、采用hinge loss作为尺度金字塔网络的损失函数,构造SPN network:
其中
二、在线更新阶段
在第t帧的图像,首先获取一个以上一帧目标为中心矩形框,将矩形框内容通过CNN-E提取特征图,同时用如下式子预测特征的响应热图:
找到热图中响应最大的位置,并且此位置的响应值大于置信阈值conf时,将此位置定为当前帧的目标框所在位置。为了预测当前目标尺度,获取以当前预测位置为中心,两倍目标大小的区域,将其传入SPN network,并根据