EfficientNet v1
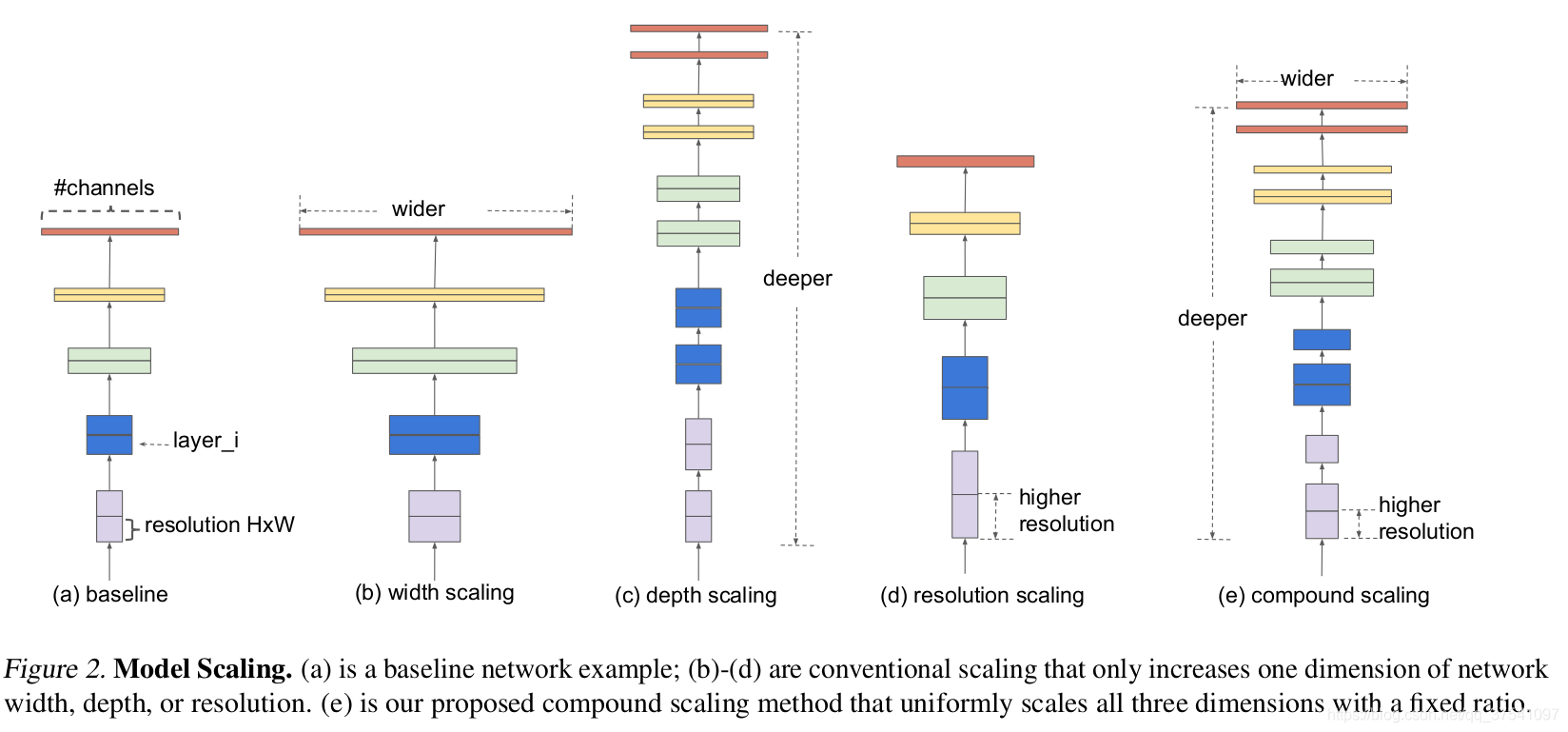
- 增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
- 增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
- 增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。但大分辨率图像会增加计算量。
efficientnet则是通过NAS搜索,同时增加width、depth以及resolution,使网络结构达到最优。
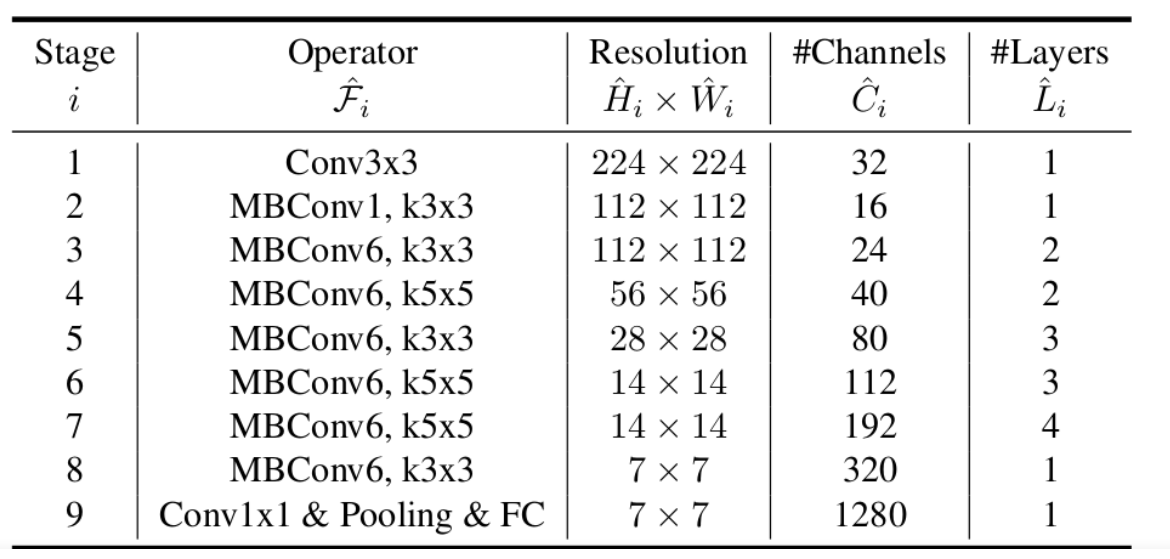
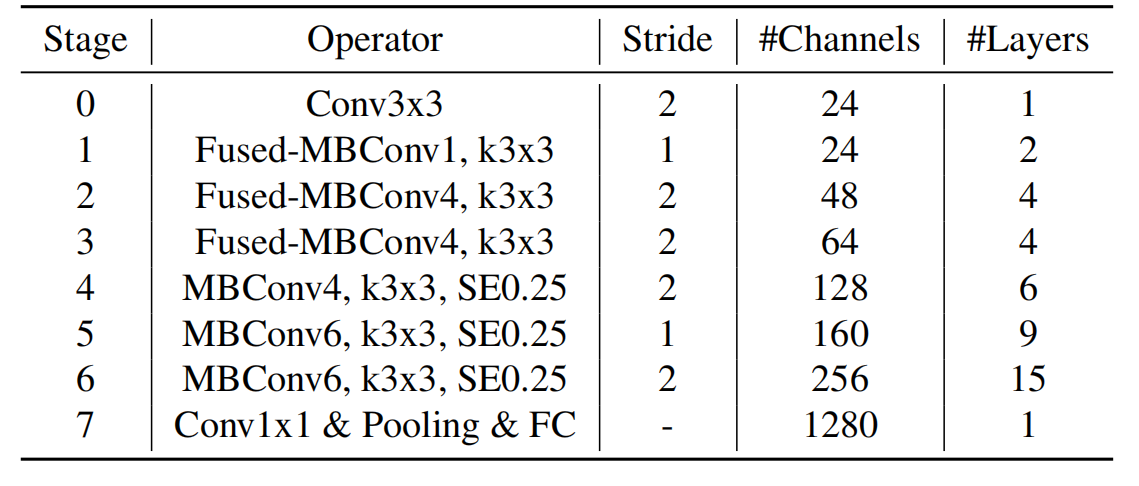
下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage。
第一个Stage是一个卷积核大小为3x3,stride为2的普通卷积层(包含BN和Swish激活函数);
Stage2~Stage8都是在重复堆叠MBConv结构(Layers表示该Stage重复MBConv结构多少次),Stage9由一个普通的1x1的卷积层 + 平均池化层 + 全连接层组成。
MBConv后的1或6就是倍率因子n,即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构如下:

MBConv主要由一个 1x1 的卷积进行升维 (它的卷积核个数是输入特征矩阵channel的n倍, n ∈ { 1 , 6 } n \in \left\{1, 6\right\} n∈{
1,6},当n=1时,不升维),一个kxk的Depthwise Conv卷积,k主要有3x3和5x5两种情况,一个SE模块,然后接一个1x1的普通卷积进行降维作用,再加一个Droupout,最后再进行特征图融合。
仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时shortcut连接才存在(代码中可通过stride== 1 and inputc_channels==output_channels条件来判断)
SE模块,由一个全局平均池化,两个全连接层组成。
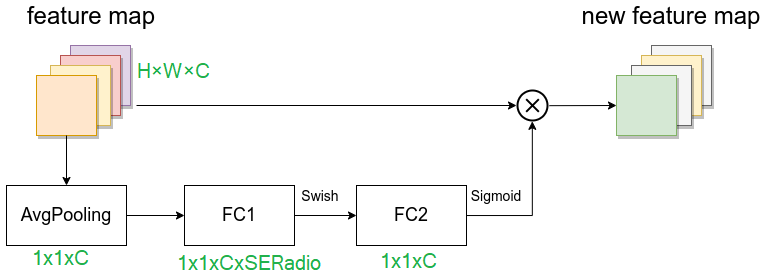
假设输入图像H×W×C,第一个全连接层的节点个数是输入该MBConv特征矩阵 channels 乘SERadio,一般SERadio为 0.25,所以channe为 C 4 \frac{C}{4} 4C ,然后是Swish激活函数。
第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵 channels,即 C C C,且使用Sigmoid激活函数,这样就拉伸成了1×1×C,然后再与原图像相乘,将每个通道赋予权重。这样就实现了注意力。
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
Dropout层在源码实现中只有使用shortcut的时候才有Dropout层。
EfficientNet V2
EfficientNet V1在训练图像的尺寸很大时,训练速度非常慢,而且非常吃显存。
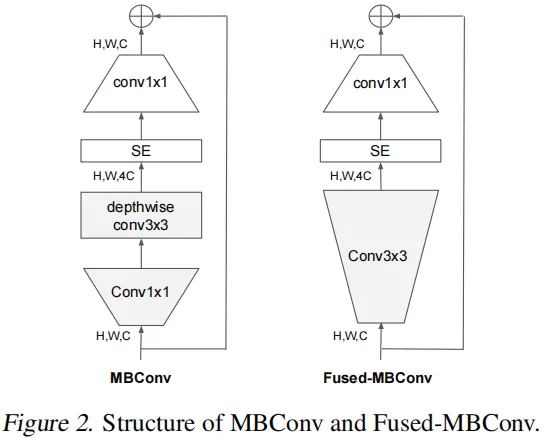
在网络浅层中使用Depthwise convolutions速度会很慢。虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器,于是有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。
Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的 conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图所示。
EfficientNetV2网络框架相比与EfficientNetV1,主要有以下不同:
- EfficientNetV2中除了使用到MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。
- EfficientNetV2使用较小的expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6. 这样的好处是能够减少内存访问开销。
- EfficientNetV2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过下表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。
- 移除了EfficientNetV1中最后一个步距为1的stage,就是EfficientNetV1中的stage8,可能是因为它的参数数量过多并且内存访问开销过大。
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN
Fused-MBConv 模块模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。
当stride=1且输入输出channel相等时才有shortcut连接。
当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。
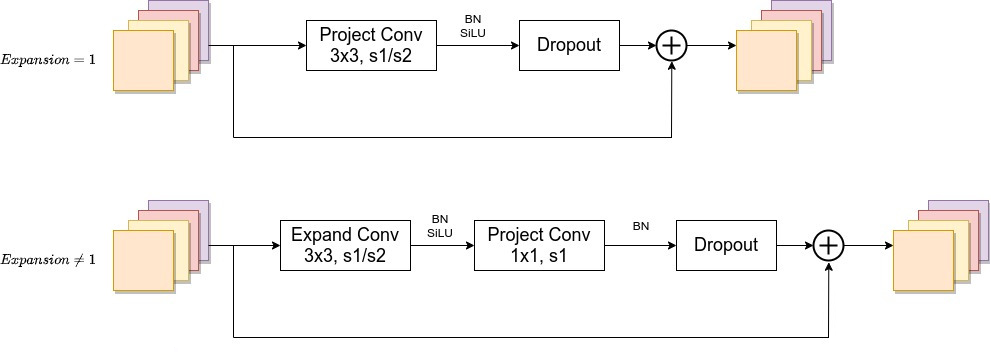
MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的 1 4 \frac{1}{4} 41
注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。

Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,Layers表示该Stage重复堆叠Operator的次数。