目录
本文将介绍如下内容
- 多层感知机
- 多层感知机的从零开始实现
- 多层感知机的简洁实现
多层感知机
隐藏层
多层感知机在单层神经网络的基础上引入了一到多个隐藏层。
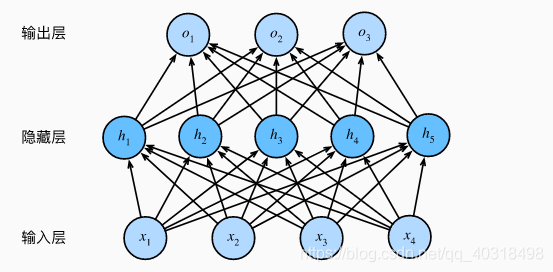
输入和输出个数分别为4和3,隐藏层包含5个隐藏单元。
由于输入层不涉及计算,因此该多层感知机的层数为2。
样本批量大小为n,输入个数为d(4)。假设多层感知机只有一个隐藏层,其中隐藏单元个数为h(5)。
记隐藏层的输出(隐藏层变量)为H,有H∈Rn*h。
可以设隐藏层的权重参数和偏差参数分别为Wh∈Rd*h和bh∈1*h;
输出层的权重和偏差参数分别为Oo∈Rh*q和b0∈R1*q
其输出Oo∈Rh*q 的计算为:
H = XWh + bh
O = HWo + bo
O = (XWh + bh)Wo + bo = XWhWo+bhWo +bo
激活函数
ReLu函数
ReLu(x) = max(x,0),只保留正数元素,负数元素清零
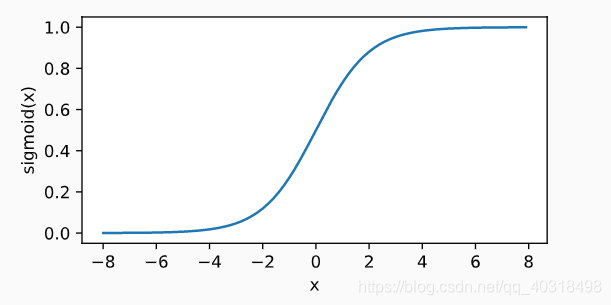
sigmoid函数
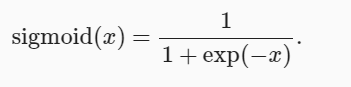
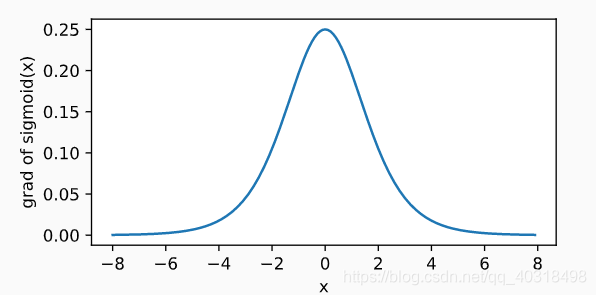
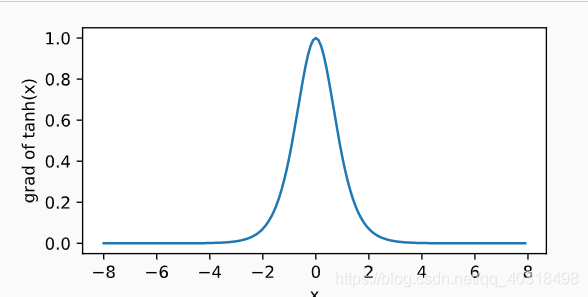
导数为:
tanh函数
tanh(双曲正切)函数可以将元素的值变换到-1和1之间。
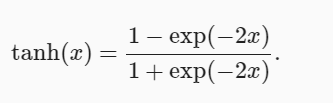
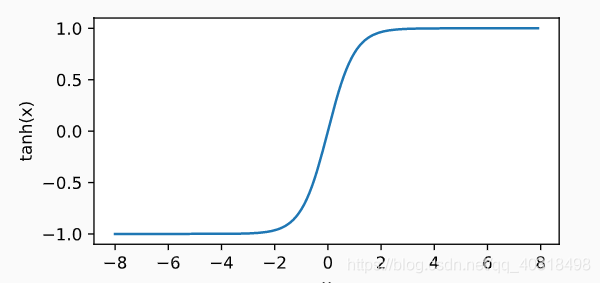
导数为
多层感知机的从零开始实现
# 读取数据集
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
# 定义模型参数
#输入个数784,设超参数隐藏单元个数为256
num_inputs,num_outputs,num_hiddens = 784,10,256
W1 = nd.random.normal(scale=0.01,shape=(num_inputs,num_hiddens))
b1 = nd.zeros(num_hiddens)
W2 = nd.random.normal(scale=0.01,shape=(num_hiddens,num_outputs))
b2 = nd.zeros(num_outputs)
params = [W1,b1,W2,b2]
for param in params:
param.attach_grad()
def relu(X):
return nd.maximum(X,0)
# 定义模型
def net(X):
X = X.reshape((-1,num_inputs))
H = relu(nd.dot(X,W1)+b1)
return nd.dot(H,W2) + b2
# 定义损失函数
loss = gloss.SoftmaxCrossEntropyLoss()
# 训练模型
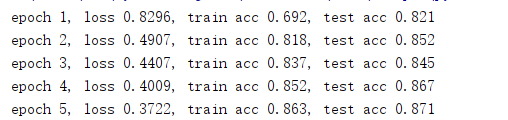
num_epochs,lr = 5,0.5
test = d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,batch_size,params,lr)
print(test)
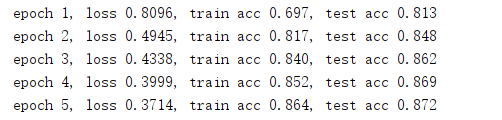
运行结果
多层感知机的简洁实现
# 和softmax回归的唯一不同在于,多加一个全连接层作为隐藏层。隐藏单元为256,并使用ReLu作激活函数
# 读取数据集
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
net = nn.Sequential()
net.add(nn.Dense(256,activation='relu'),nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
# 定义损失函数
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':0.5})
# 训练模型
num_epochs,lr = 5
test = d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,batch_size,None,None,trainer)
print(test)
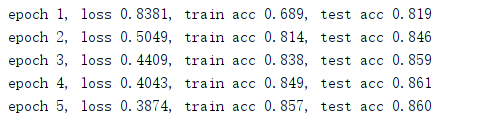
运行结果
- batch_size = 256
- lr = 0.5
- hiddens = 256
- batch_size = 256
- lr = 0.5
- hiddens = 200
- batch_size = 256
- lr = 0.5
- hiddens = 300

增加隐藏层的个数,不一定能提高模型训练的正确率,相反,减少隐藏层个数,也不一定会降低训练的正确率。