学习算法:
主要应用于:
分类:输出对应的类。
输入缺失分类:数据不完整,通过机器学习方式补全,主要用GAN
回归:输出输入对应的值。
转录:转录非结构化数据为离散数据。
机器翻译:序列对序列的转换。
结构化输出、异常检测、合成和采样、去噪等等。
性能度量:
准确率表示输出正确结果的样本比率。
错误率表示输出错误样本的样本比率。
。。。填补roc,auc之类如果后面几章没有的话
机器学习算法分类:
主要分为有监督和无监督学习还有强化学习。
有监督学习的样本具有标签。无监督学习无标签,主要用于聚类、去噪等。强化学习也没有标签,只是对行为进行奖惩,相当于设定一个规则,最经典代表alpha go zero,没有任何数据即可完成学习。本书没有强化学习,等笔记写完继续强化学习。
实例:线性回归
均方误差:mse 为
f(x) = wx + b,b为偏置。
容量、过拟合和欠拟合:
训练误差为在训练集上的误差,泛化误差为在测试集上的误差,我们主要期望得到一个泛化误差小,即泛化能力强的模型。
我们的测试集和训练集期望是独立同分布的。
机器学习遇到的主要问题是欠拟合和过拟合。模型的容量表示模型的能力,能力过强容易过拟合,过弱容易欠拟合。
表示容量:模型的可选函数族。
有效容量:通常不会找到最优函数,只要能符合预期即可,所以有效容量小于表示容量。
奥卡姆剃刀表示同样能解释观测现象的假设中,相对简单的模型更好。
VC维:量化模型容量的参数。二元分类器的容量。西瓜书中有详细解说,后面补充。
贝叶斯误差:从预先知道的分布预测二出现的误差。
非参数模型:最近邻算法。(就是不用训练的意思吗?)
没有免费午餐定理:没有一个无敌的计算机算法。但是目前好像很多算法都期望能够运用于多领域。强人工智能不就是这个意思吗。
正则化:加入对模型复杂度的惩罚机制,即代价函数。正则化定义是指修改学习算法,降低泛化误差而非训练误差。
超参数和验证集:
验证集是训练集互斥的一部分,用于挑选超参数。超参数是设置而非训练的。
通常训练集中80%训练参数,20%挑选超参数。
交叉验证:k折交叉验证。分成K分,训练k次,取误差平均。
估计、方差和偏差:
点估计:为
的点估计。就是预测的函数呀感觉。。
偏差:
偏差为0则无偏估计。有偏无偏主要针对看是对什么的估计,而不是对模型的估计。比如对方差和均值估计。
置信区间:
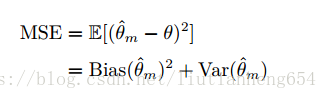
增加容量会降低偏差,增加方差。
一致性表示必然收敛。(不知道这个定义有什么用)
最大似然估计:
从不同模型中得到特定函数作为适合的估计。
贝叶斯统计:
不同于之前都属于频率派统计。
监督学习方法:
logistic sigmoid函数:将线性函数的输出压缩在0到1之间,输出一个概率,称为逻辑回归,但实际上一般用来分类。
常用监督学习方法:
支持向量机:
找到一个可以分离开两类样本的最大分割平面。书中说不支持输出概率,但实际是有变种可以输出概率的。可以搜支持向量回归。然后花书中对支持向量的介绍不够详细,详细原理推荐李航的《统计学习方法》。
支持向量的含义就是离分割平面距离最近的样本。分割平面仅与支持向量有关,与其他样本无关。但是大多情况下样本是无法线性可分的,这时候支持向量机的创新性的引入了核函数,将样本可分。核函数将原本不可分的样本映射到了高维空间变得可分。最常用的核函数就是高斯核,用K表示,标准正态分布的高斯核被称为径向基函数。
K近邻算法:
分类算法,没有训练过程,待测样本直接认为是离其最近的K个样本分类中的众数。当k为1时,退化为最近邻算法,k为样本集大小时,则永远为样本中最多的类。K的选择方法通常是交叉验证法。
主要使用中考虑三点:距离度量方式选择、k值选择、分类决策选择
k近邻一般通过k-d树搜索,这两个k不相关。
弱点:无法判断特征的强弱。
决策树:
决策树根据信息增益、信息增益比和基尼系数分为ID3,C4.5和CART
一般为防止过拟合采用剪枝技术。
无监督学习方法:
主要应用降维、稀疏表示、独立表示、聚类。表示学习后面会有专门章节介绍
主成分分析:
k-均值聚类:
个人理解,该算法重点在如何选取最初的k个点以及选取K值为多少。
书中说无法衡量聚类的好坏,但是我记得有个什么距离时衡量聚类结果的。
随机选取
这里再介绍几种聚类算法:
。。。
密度聚类
层次聚类
随机梯度下降:
就是每次不使用全部样本,仅使用一个小batch的样本量进行运算,提高训练速度。后面会有一个章节专门介绍其优化方式。
构建机器学习方法:
主要构成由:特定的数据集、代价函数、优化过程和模型
促使深度学习方法的挑战:
维数灾难:导致运算过于复杂以及样本不足。
局部不变性和平滑正则化:
主要是指我们通常的学习都具有局部不变和平滑的先验,即在小范围内样本变化不会很大。导致当函数较复杂时,我们需要学习的样本很多。才能覆盖所有测试集。
局部核:核函数k(u,v)在u = v时很大,当距离拉大时减小。用于度量测试样本和每个样本的相似性。
流形学习:西瓜书中更加详细,后面补。