第五章 深度神经网络为何很难训练
在深度网络中,不同的层学习的速度差异很大。当网络中后面的层学习的情况很好的时候,先前的层常常会在训练时停滞不变,基本学不到东西。根本原因是学习的速度下降了,学习速度的下降和基于梯度的学习技术有关。
5.1 消失的梯度问题
对于MNIST分类问题,理论上说,增加一个神经网络额外的隐藏层应该让网络能够学到更加复杂的分类函数,然后再分类时表现得更好,但是事情并不是这样子的,随着隐藏层的增加,分类准确率略有下降。假设额外的隐藏层的确能够在原理上起到作用,问题就是我们学习的算法没有发现正确的权值和偏置。
下图这些条表示了每个神经元权重和偏差在神经网络学习时的变化速率。这里只展示了一个两个隐藏层的神经元,进行MNI身体分类,并且忽略输入层神经元,因为他们并不包含需要学习的权重或者偏差。同样输出层神经元也忽略了。在网络初始化后立即得到训练前期的结果如下:
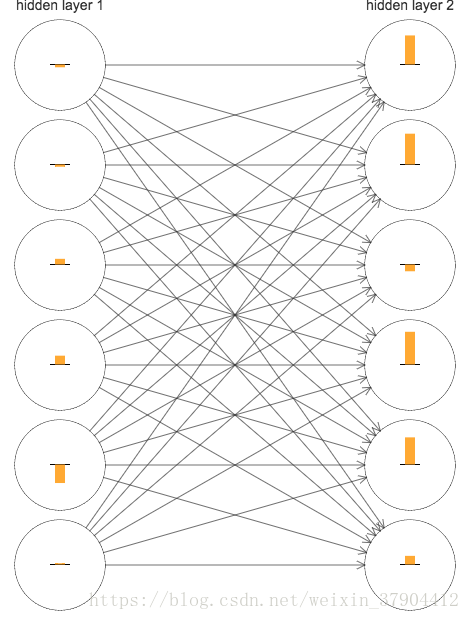
该网络是随机初始化的,因此看到了神经元学习的速度差异很大。而且,我们可以发现,第二个隐藏层上的条基本上都要比第一个隐藏层上的条要大。所以,在第二个隐藏层的神经元将学习得更加快速。
这里讲梯度表示为:
在第
层的第
个神经元的梯度。可以将
看作是一个向量,其中的元素表示第一层隐藏层的学习速度,
则表示第二层隐藏层的学习速度。接着使用这些向量的长度作为全局衡量这些隐藏层的学习速度的度量。因此
就代表第一层隐藏层学习速度,
就代表第二层隐藏层学习速度。上图中,
。
更多试验表明,随着隐藏层的增多,前面隐藏层的神经元学习速度要慢于后面隐藏层的学习速度。这意味着在隐藏层反向传播的时候梯度倾向于变小,这个现象就是梯度消失。但是也会产生同样的问题,在前面层中的梯度会变得非常大,这个现象就是梯度爆炸。深度神经网络中的梯度是不稳定的,在前面的层中会消失,或会爆炸。这种不稳定性是深度神经网络中基于梯度学习的根本问题。
注意一个问题:假设我们正要优化一个函数
,如果其导数
很小,不是一个好消息么?这意味着我们已经接近极值点了。同样地,在深度神经网络中前面隐藏层的小的梯度是不是表示我们不需要对权重和偏置做太多调整了?当然不是这样的。梯度消失问题会出现在训练的前期,而初始状态下我们是随机初始化权重和偏置的。如果此时出现梯度消失,学习停止,那么在面对任意一种任务,单单使用随机初始的值就想获得一个较好的结果是太天真了。
5.2 什么导致了消失的梯度问题?深度神经网络中的梯度不稳定性
下图是有三层隐藏层的神经网络:
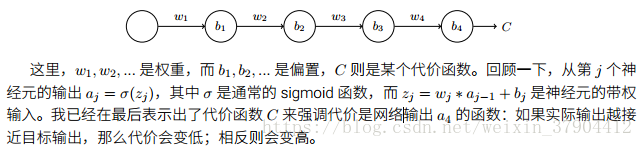
现研究对第一个隐藏神经元梯度:
下面仔细追踪每一步的影响来推导上述表达式。
1. 首先对偏置
进行微小的调整
,它会影响第一个神经元的输出
。
,所以有
。
2. 此时将偏置的改变
转化成了输出的变化
,
随后又影响了带权输入
:
。
3. 将
和
表达式组合起来,可以看到偏置
中的改变如何通过网络传输影响到
:
。这就得到了上述表达式
的前两项。
4. 以此类推,跟踪传播改变的路径就可以完成:
为何出现梯度消失
如果使用sigmoid函数作为激活函数,该函数的导数在
时达到最高。如果使用均值0,标准差1的高斯分布初始化权重,因此所有的权重会满足
。因此会发现
。并且我们对这些项乘积时,最终结果会指数级下降。
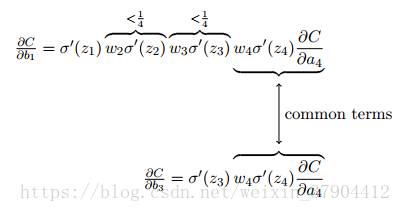
比较一下
和
,显然前者是后者的
或者更小。这就是梯度消失的本质原因。
当然,在训练过程中,有可能权重
会出现增长,甚至超过1。
会不满足之前
的约束。那么遇到的就不再是梯度消失的问题,而是梯度爆炸的问题。
不稳定的梯度问题根本的问题其实并非是消失的梯度问题或者爆炸的梯度问题,而是在前面的层上的梯度是来自后面的层上项的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。让所有层都接近相同的学习速度的方式可以使所有这些项的乘积都能得到一种平衡。如果没有某种机制或者更加本质的保证来达成这样的平衡,那网络就很容易不稳定了。如果我们使用标准的基于梯度的学习算法,在网络中的不同层会出现按照不同学习速度学习的情况。