第三章 优化神经网络的学习过程
作者: Michael Nielsen
简介
本章将覆盖神经网络中的一些常用技术,包括交叉熵代价函数,四种正规化方法,更好的初始化权重的方法,为网络选择更好的超参数。
交叉熵代价函数
我们希望我们的神经网络可以从误差中学习得更加快,现在举一个简单的例子

我们要做的是输入1,使得输出为0。改变weight和bias的初始值会显著改变神经网络的学习过程,但是它们的结果还是趋近于相同的。与期望偏离较大的weight和bias并没有从显著误差中学习得更快,这与我们的认知不符。原因在于我们所使用的sigmoid函数在x的值特别大时,它的导数很小,导致学习的速率非常慢。
那么如何解决这个问题呢,
我们需要做的是把平方代价函数换成交叉熵代价函数,下面举例说明:

假设现在有这样的一个神经元,我们可以得到
n为训练数据中的样本总数,y为我们期望的输出。
将它作为代价函数是合理的,首先,它一定为正数,其次,当网络的输出很接近期望输出时,函数值接近0,同时它也不会有误差很大但是学习率却很慢的问题,这可以通过求偏导数来得到
同样的,我们可以得到
交叉熵代价函数可用于拥有多个神经元的多层网络,它被定义为如下形式
实践证明,在激活函数为sigmoid函数的情况下,使用交叉熵往往会取得更好的效果。
softmax
这部分主要介绍神经网络中的softmax层,这在深度网络中有很多的应用。不同于sigmoid激活函数,softmax的形式如下:
假设我们的网络有4个输出,
将它们代入上面的式子,我们可以发现输出均为正数并且和为1,所以这个输出可以看作是一种概率分布.
过拟合以及正则化
过拟合
当一个模型有了过多的参数,它可以在训练集上表现得很好。但是,很有可能它并不能把握到问题的本质,这体现在它在测试集上的表现欠佳。
现在我们使用1000个训练样本来训练拥有23860个参数的30层神经网络,在训练时,它的表现和之前一样好,cost在稳步下降,accuracy也在稳步上升,但是这样的网络在测试集中的表现很不好,这就产生了过拟合的现象。
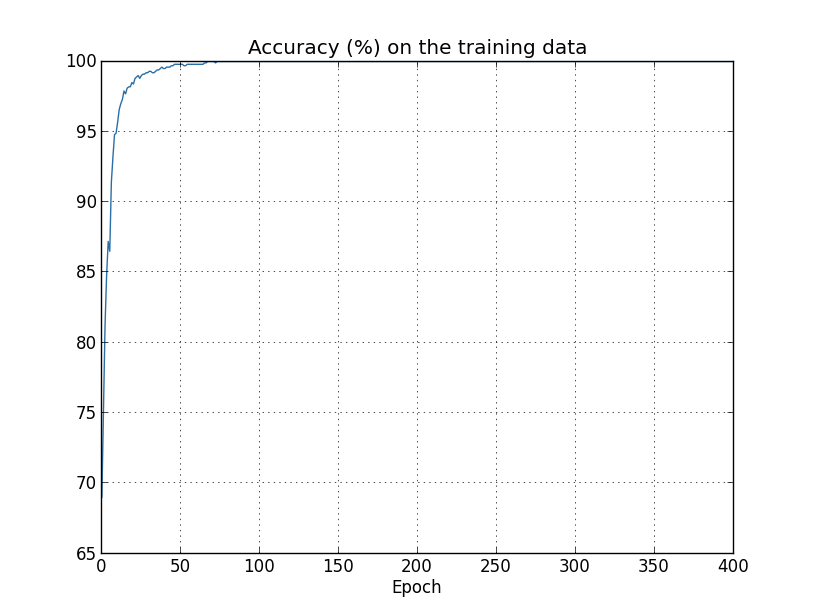
从这张图上可以看出,模型对于训练样本的识别准确率非常高,它更像是记住了数据而不是从中学到了规律,这同样是过拟合的表现。
针对这个问题,我们可以采取很多方法。其中之一就是观察训练时的准确率,一旦它停止上升,就可以停止训练了。还有一种方式就是使用validation_data这个数据集,在每一轮训练完成后,我们跑一部分这个数据集,并跟踪它的识别准确率,一旦准确率停止上升就停止训练,同时这个数据集可以供我们调试超参数。
现在使用完整的数据集来做实验,得到下面的accuracy曲线
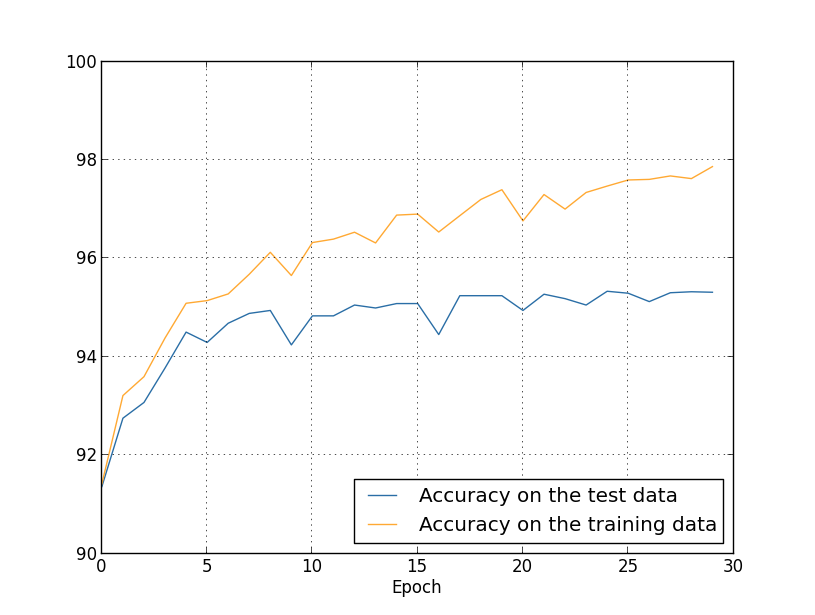
可以看出,过拟合问题得到了很好的解决,方法就是增加训练集的数目,这样做的代价就是大量的数据集并不是很好获取。
正则化
这一部分主要介绍权值衰减技术。
方法就是给代价函数加上正则化项,改写交叉熵代价函数如下:
其中
这相当于我们需要在较小的cost和较小的权值之间权衡,这由泛化参数来控制。
观察一下反向传播过程,依旧是求偏导:
bias的更新方式不变,weight的更新方式如下
运用此项方法后,我们再来观察实验效果:
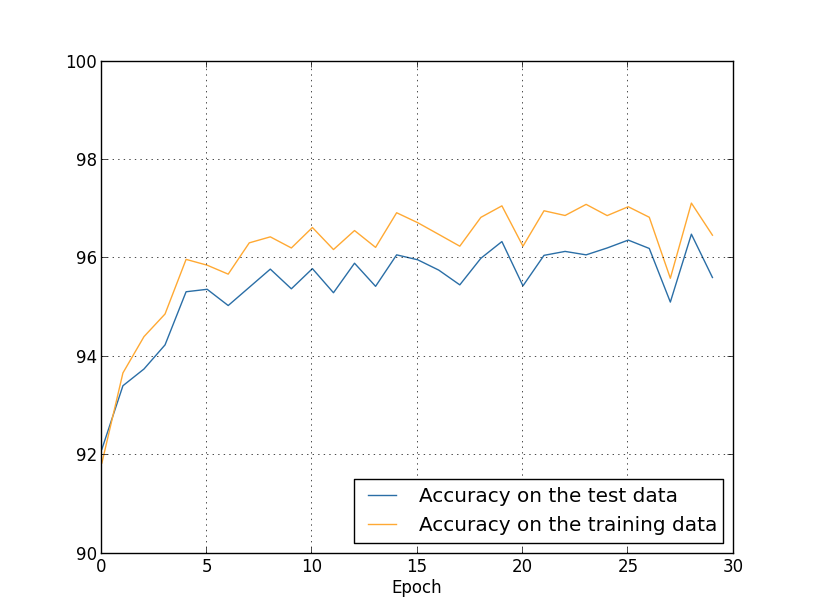
首先,识别的准确率提升了,并且,训练集和测试集的准确率差距也减小了。