ViT
AN IMAGE IS WORTH 16X16 WORDS :TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE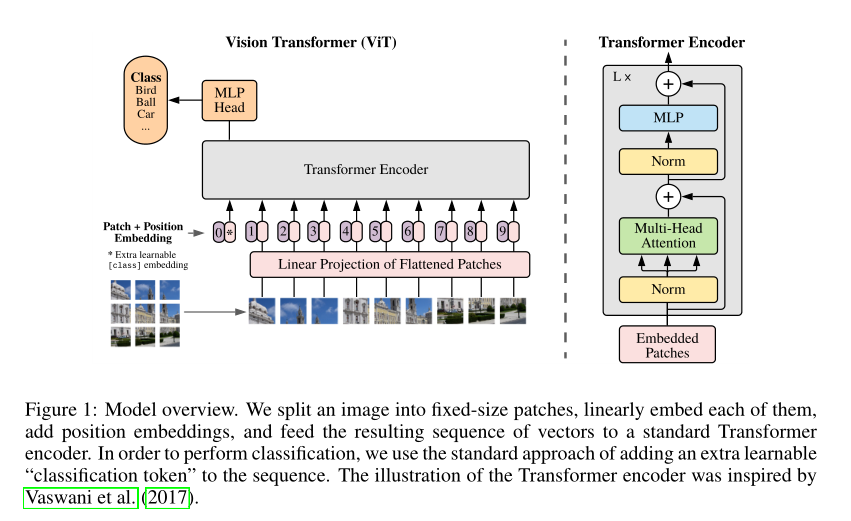


Vision Transformer(ViT)将输入图片拆分成16x16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer,避免了像素级attention的运算。类似BERT[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
Self-attention 是quadratic级别的时间和内存复杂度。
我们使用简短的符号来表示模型大小和输入Patch大小:例如,ViT-L/16表示具有16×16输入补丁大小变量。值得注意,Transformer的序列长度与补丁尺寸的平方成反比,因此补丁尺寸较小的模型的计算成本更高。其中,HW为原图像分辨率,PP为每个图像patch的分辨率。N=HW/P*P为Transformer输入序列的长度。
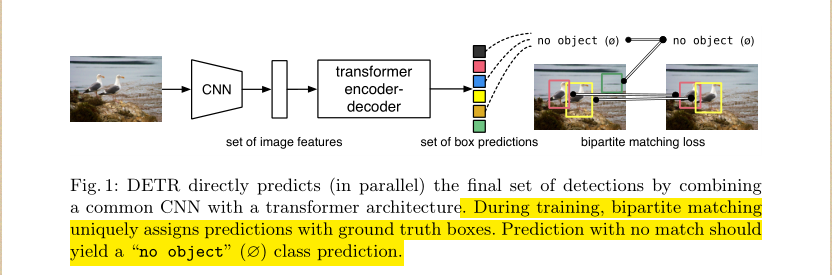
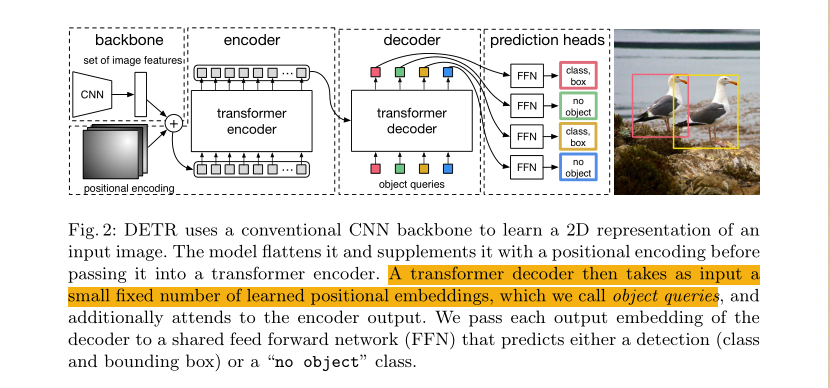
DETR
End-to-End Object Detection with Transformers