1前言
地统计课设算是彻底结束了,从中也收获了不少,对于优化算法也是相应学了深入一下,这里公布我们组我写了粒子群算法来拟合变异函数的这一部分源代码,仅供大家学习
2方法原理
这里粒子群的算法原理不再赘述,再我之前的博客已经有了很详细的讲解了,这里放上链接地址,https://blog.csdn.net/qq_44589327/article/details/105371963
本偏文章主要讲解的是基于自动匹配单一模型类型参数的粒子群算法拟合参数。
我们都知道常用的变异函数模型有以下几种
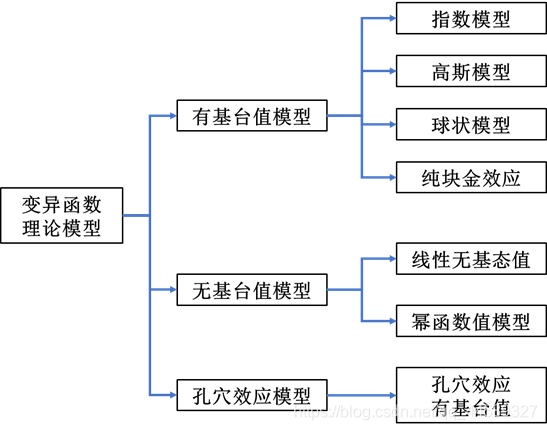
当我们拿到了变异函数的基础数据,即滞后距
与滞后距对应的经验半方差
,基于现有的常用模型怎样来自动识别出用哪种模型较好,不需要自己去将每个模型都跑一遍最后来决定使用哪个模型。
2.1初始解空间
以自动匹配单一模型举例,假设我们常用的模型库种模型有如下几种:球状模型,指数模型,高斯模型,为每个模型加上一个标识符,在粒子上因此有一个模型类型的维度,并且在该维度上,必须要规定范围在 其中 是模型类型的数量,且在粒子位置进行更新时,该维度必须进行取整才能进行适应度的计算
2.2适应度函数计算
根据统计学思想,对理论模型的最优拟合实质上就是让理论变异函数值和实际变异函数值之间的方差最小,然而在实际计算中,实际变异函数曲线上个点的重要性是不同的,往往滞后距小的点的重要性要大于滞后距大的点,因此采用以滞后距的倒数作为权系数参与适应度评价函数的构建,最终函数形式为( 函数值越大,个体适应度越高)
其中
其余步骤可以参考我上一篇粒子群算法博文原理,基本类似
3 计算实例
这里仍然以全氮数据为基础,设置
,粒子维度
,粒子规模
,最大迭代次数
,分别设置块金常数、基台值、变程(要拟合的三个参数)的估值范围
,其中模型参数,1代表球状,2代表指数,3代表高斯,本里所采用的惯性因子w对搜寻最优解尤为重要,为了更好地平衡算法的全局搜索能力与局部搜索能力,这里引用,Shi.Y提出了线性递减惯性权重(LDIW)
基于粒子群算法模型拟合效果如图所示
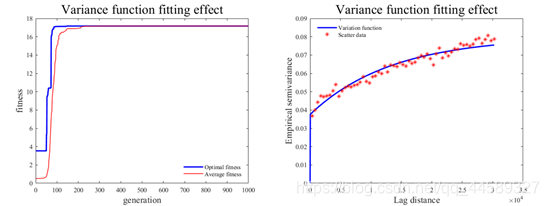
上图显示历代来粒子群最优适应度以及最终的拟合效果,最终模型的精度如下

其最优解的解空间矩阵如下:

附录
代码不完整,这里适应度函数与其他函数可以参考我上一篇粒子群算法的博文仔细深究,写出适合自己实际问题的适应度函数
clear;clc
data=xlsread('F:\geostatistical_test\test\data_and_materials\rh_N.xlsx');
%读取处理后的滞后距及经验半方差
x0=data(:,1);y0=data(:,2);%h是滞后距,rh是滞后距下对应的经验半方差值
c1=2;%自我学习因子
c2=2;%社会学习因子
Dimension=4;%设置粒子维度因为拟合的是4个参数
Size=100;%设置粒子规模
Tmax=1000;%最大迭代次数
Vmaximum=100;%粒子最大速度
c0min=0;c0max=0.05;%设置c0估值区间,即块金常数
c1min=0.05;c1max=0.2;%设置c1估值区间,即基态值
amin=15000;amax=50000;%设置a估值区间,即变程
mmin=1;mmax=3;%设置模型参数范围,1代表球状,2代表指数,3代表高斯
position=zeros(Dimension,Size);velocity=zeros(Dimension,Size);
%初始化例子的位置与速度
vmax(1:Dimension)=Vmaximum;vmin(1:Dimension)=-Vmaximum;
%设置速度上下界
xmax=[c0max,c1max,amax,mmax];xmin=[c0min,c1min,amin,mmin];%设置位置即拟合参数上下限
[position,velocity]=Initial_position_velocity(Dimension,Size,xmax,xmin,vmax,vmin);
position(4,:)=round(position(4,:));%转换为模型参数的整数
pbest_position=position;%粒子的历史最优位置,初始值为粒子的起始位置,存储每个粒子的历史最优位置
gbest_position=zeros(Dimension,1);%全局最优的那个粒子所在位置,初始值认为是第1个粒子
for j=1:Size
Pos=position(:,j);%取第j列,即第j个粒子的位置
fz(j)=Fitness_Function(Pos,x0,y0);%计算第j个粒子的适应值
end
[gbest_fitness,I]=max(fz);%求出所有适应值中最大的那个适应值,并获得该粒子的位置
gbest_position=position(:,I);%取最大适应值的那个粒子的位置,即I列
%开始循环找到最优解
w_start=0.9;w_end=0.4;
for itrtn=1:Tmax
%Weight=1;%惯性因子
Weight=w_end+(w_start-w_end)*(Tmax-itrtn)/Tmax;
%Weight=((0.95-0.4)/(1-Tmax))*(itrtn-1)+0.95;
r1=rand(1);
r2=rand(1);
%进行速度更新
for i=1:Size
velocity(:,i)=Weight*velocity(:,i)+c1*r1*(pbest_position(:,i)-position(:,i))+c2*r2*(gbest_position-position(:,i));
end
%限制速度边界
for i=1:Size
for row=1:Dimension
if velocity(row,i)>vmax(row)
velocity(row,i)=vmax(row);
elseif velocity(row,i)<vmin(row)
velocity(row,i)=vmin(row);
else
end
end
end
%大于最大速度的用最大速度代替,小于最小速度的用最小速度代替
position=position+velocity;%位置更新
position(4,:)=round(position(4,:));%转换为模型参数的整数
%限制位置边界
for i=1:Size
for row=1:Dimension
if position(row,i)>xmax(row)
position(row,i)=xmax(row);
elseif position(row,i)<xmin(row)
position(row,i)=xmin(row);
else
end
end
end
for j=1:Size
p_position=position(:,j)';%取一个粒子的位置
fitness_p(j)=Fitness_Function(p_position,x0,y0);%计算第j个粒子适应度的值
if fitness_p(j)> fz(j) %粒子的适应值比运动之前的适应值要好,更新原来的适应值
pbest_position(:,j)=position(:,j);
fz(j)=fitness_p(j);
end
if fitness_p(j)>gbest_fitness
gbest_fitness=fitness_p(j);%如果该粒子比当前全局适应度的值还好,则代替
end
end
[gbest_fitness_new,I]=max(fz);%更新后的所有粒子的适应值,取最大的那个,并求出其编号
mean_fitness(itrtn)=mean(fz);
best_fitness(itrtn)=gbest_fitness_new; %记录每一代的最好适应值
gbest_position=pbest_position(:,I);%最好适应值对应的个体所在位置
end
figure;
plot(best_fitness,'b','Linewidth',2);
hold on;
plot(mean_fitness,'r','Linewidth',1);
xlabel('generation','FontSize',14);
ylabel('fitness','FontSize',14);
legend('Optimal fitness','Average fitness','Location','southeast');%添加图例
legend('boxoff','FontSize',14);%删除图例的轮廓宇背景
title('Variance function fitting effect','FontSize',20);
set(gca,'Fontname','times new Roman');
figure;
x=0:0.1:max(x0);
yf=fun(gbest_position,x);
plot(x,yf,'b','Linewidth',2);
hold on;
plot(x0,y0,'r*');
xlabel('Lag distance','FontSize',14);
ylabel('Empirical semivariance','FontSize',14);
legend('Variation function','Scatter data','Location','northwest');%添加图例
legend('boxoff','FontSize',14);%删除图例的轮廓宇背景
title('Variance function fitting effect','FontSize',20);
set(gca,'Fontname','times new Roman');
yp=fun(gbest_position,x0);%求对应的拟合值
[R2,RSS]=test(y0,yp);%求R2,RSS
result=gbest_position;%分别代表块金值,基台值,变程,以及模型参数,