Hadoop是基于分布式的系统应用,但很多时候我们只是进行简单的测试,没有必要做集群。所谓的伪分布式本质上就是进行单机版的Hadoop配置。
1.在Hadoop中不允许IP地址变更,所以要保证从项目的开发到运行结束状态,都要求IP地址是同一个,如果变更了就要重头来过
(编辑-虚拟网络编辑器)

2.为了保证配置的方便,那么一定要为每台电脑设置主机名称
#vim /etc/hostname
将里面的localhost修改为hadoopm
3.修改主机的映射配置
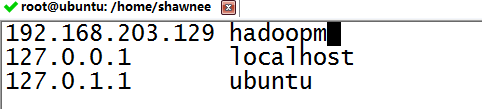
在里面追加IP地址与hadoopm主机名称的映射
#ifconfig
![]()
#vim /etc/hosts
4.为了使配置生效,我们重启系统,输入reboot
5.在电脑上配置ssh免登陆处理
在整个Hadoop的处理过程中,都是使用ssh实现通讯(就算在本机也一样)
- 由于电脑上可能已经出现过SSH的相关配置,所以建议删除在根路径下的“.ssh”文件夹
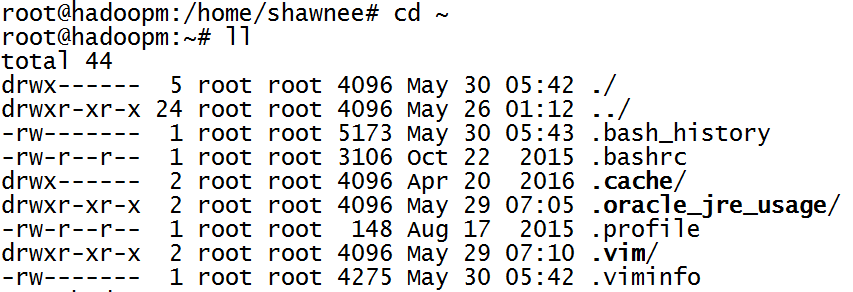
如图所示,并未存在已有配置,故不需要删除。
如果存在ssh配置,则
#rm -rf ~/.ssh
- 在hadoop主机上生成ssh
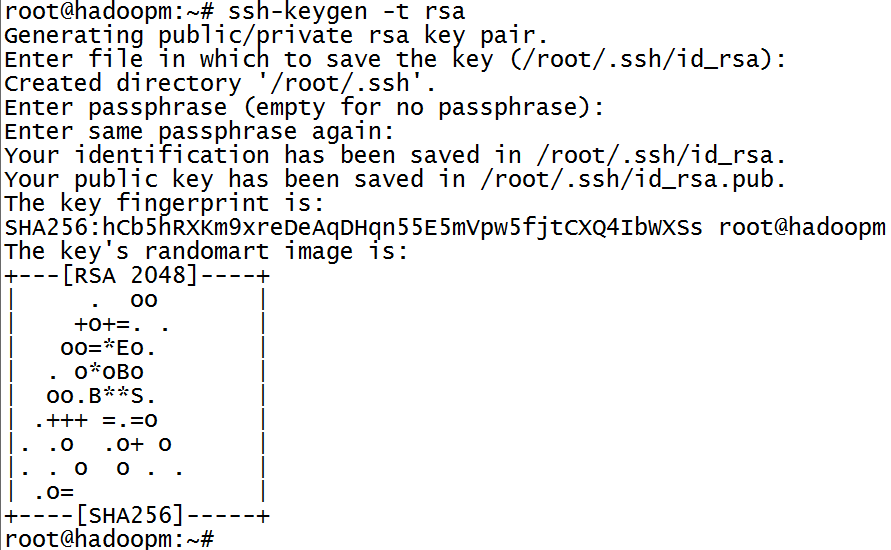
# ssh-keygen -t rsa
接下来所有出现的配置信息都使用默认的方式进行处理
-
将公钥信息保存在授权认证的文件之中,“authorized_keys” 文件里面
root@hadoopm:~# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
那么以后就可以进行免登陆处理

- 测试登录
#ssh root@hadoopm
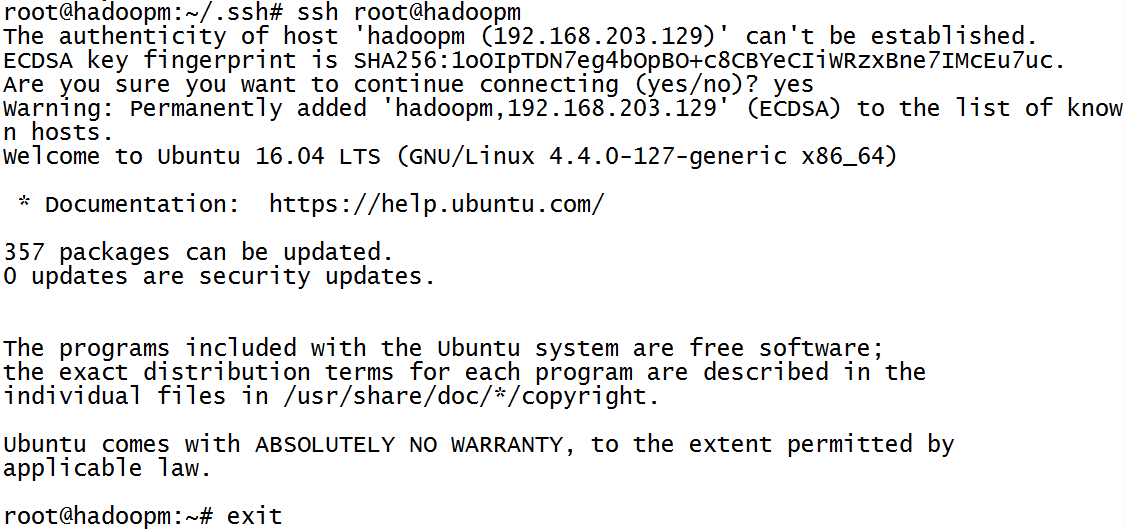
登录之后变成了远程连接,那么此时可以使用exit退出当前连接
6.实现Hadoop的相关配置,需要配置如下几个配置(/home/shawnee/local/hadoop/etc/hadoop)
- 配置“core-site.xml”,确定Hadoop的核心信息,包括临时目录、访问地址
- 配置“yarn-site.xml”,可以理解为配置相关job的处理
- 配置“hdfs-site.xml”,可以确定文件的备份个数以及数据文件夹的路径
7.配置“core-site.xml”文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/root/hadoop_tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopm:9000</value>
</property>
</configuration>
本文件配置的“hdfs://hadoopm:9000”信息,描述的是日后打开的页面管理器的路径
本配置中最重要的:“/home/root/hadoop_tmp”配置的是临时文件信息,如果不配置,就会在hadoop的文件夹里生成“tmp”文件(“/home/shawnee/local/hadoop/tmp/”)
如果这样配置,一旦重新启动,所有信息都会被清空,也就是说此时Hadoop的环境就失效了
由于本次用的Hadoop2.x开发版本,一般而言默认端口是9000,如果是1.x开发版本,默认为8020
为了保证整体的运行不出错,可以直接建立一个“/home/root/hadoop_tmp”
#cd ~ #mkdir hadoop_tmp
8.修改“hdfs-site.xml”文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoopm:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopm:50090</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
在以上的配置中有如下的意义:
“dfs.replication”表示文件的副本数,一般情况下,一个文件会备份3份
“dfs.namenode.name.dir”定义名称结点路径
“dfs.datanode.data.dir”定义数据文件结点路径
“dfs.namenode.http-address”名称服务的http路径访问
“dfs.namenode.secondary.http-address”第二名称结点
“dfs.permissions”权限认证问题,如果设置了,以后可能无法进行文件处理访问
9.配置“yarn-site.xml”文件
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoopm:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoopm:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoopm:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoopm:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoopm:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoopm:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>hadoopm:8090</value>
</property>
</configuration>
10.创建一个masters文件,里面写上主机名称
由于Hadoop属于分布式开发环境,考虑到日后要进行集群的搭建
建议在“/home/shawnee/local/hadoop/etc/hadoop/”目录中创建一个masters文件,里面写上主机名称,内容就是hadoopm(之前在hosts文件里面定义的主机名称)(如果是单机环境不写也可以,这里会写上)
root@hadoopm:/home/shawnee/local/hadoop/etc/hadoop# vim masters
![]()
11.修改从节点文件"slaves",增加hadoopm
root@hadoopm:/home/shawnee/local/hadoop/etc/hadoop# vim slaves
![]()
12.由于此时是将所有的namenode、datanode保存路径设置在hadoop目录中,如果为了保险起见,可以自己创建
root@hadoopm:/home/shawnee/local/hadoop# mkdir dfs dfs/name dfs/data
如果hadoop出现了问题之后并需要重新配置,请把这两个文件夹彻底清除
13.格式化文件系统