hadoop伪分布式配置和安装
安装环境:Centos7.5,至少2核4G内存
提前准备:Linux中要安装jdk1.8,Zookeeper-3.5.8
1.关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
2.修改主机名
vim /etc/hostname
删除原来的主机名,添加自己的主机名
例如:hadoop01
3.需要将主机名和IP进行映射
vim /etc/hosts
添加当前的主机名IP 主机名,例如
192.168.112.128 hadoop01
4.关闭SELINUX
vim /etc/selinux/config
将SELINUX属性的值改为disabled
5.重启
reboot
6.配置免密登录
ssh-keyen
ssh-copy-id
输入主机的密码
测试是否免密成功:ssh hadoop01
如果不需要密码,那么说明免密成功,输入logout退出
7.下载hadoop
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
放入/home/software目录下并解压
tar -xvf hadoop-3.1.3.tar.gz
8.进入hadoop的配置文件目录
cd /home/software/hadoop-3.1.3/etc/hadoop
9.编辑文件
vim hadoop-env.sh
在文件中添加:
export JAVA_HOME=/home/software/jdk1.8.0_321
保存退出,重新生效这个文件
source hadoop-env.sh
10.编辑文件
vim core-site.xml
在文件中标签内添加:
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-3.1.3/tmp</value>
</property>
11.编辑文件
vim hdfs-site.xml
在文件中标签内添加:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
12.编辑文件
vim mapred-site.xml
在文件中标签内添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
13.编辑文件
vim yarn-site.xml
在文件中标签内添加:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
14.编辑文件
vim workers-----注意,如果是在hadoop2.X,那么这个文件是slaves
将原来的localhost删除掉,然后添加当前主机的主机名
15.配置环境变量
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,生效这个文件
source /etc/profile
通过hadoop version命令来确定配置是否有效

16.第一次启动Hadoop之前,需要先进一次格式化
hadoop namenode -format
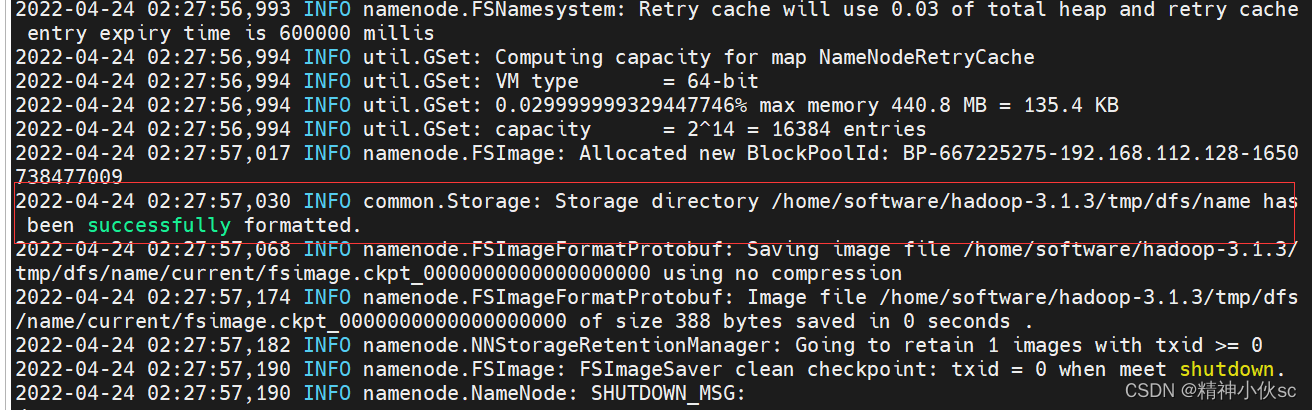
出现图中这句话表示成功
(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在允许过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要刹车农户所有机器的data和logs目录,然后再进行格式化。)
17.进入Hadoop安装目录下的子目录sbin下
cd /home/software/hadoop-3.1.3/sbin
18.编辑文件
vim start-dfs.sh
在文件头部加入
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
19.启动HDFS
start-dfs.sh
通过jps查看多出如下图三个进程
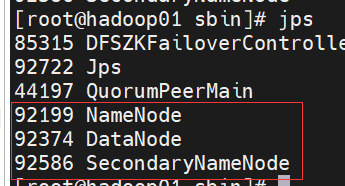
20.编辑文件
vim start-yarn.sh
在文件头部加入
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
21.启动yarn
start-yarn.sh
通过jps查看多出如下图两个进程
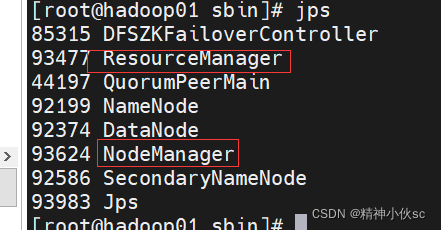
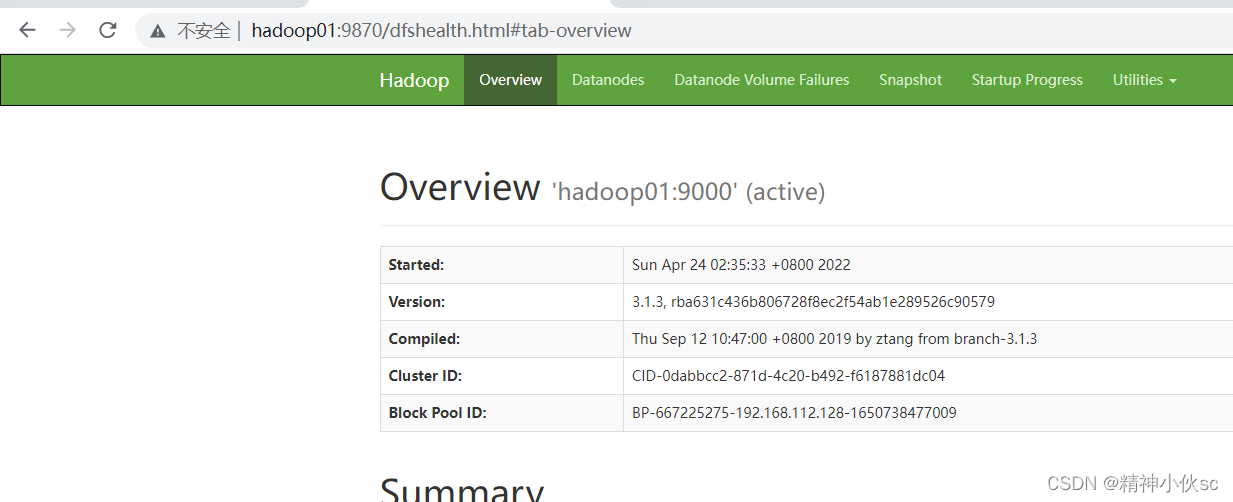
22.启动之后:提供了可视化页面来进行查看,需要通过IP:port的形式查看
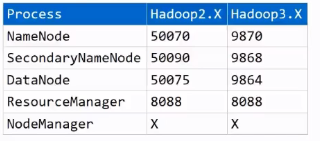
①NameNode页面访问
②SecondaryNameNode页面访问
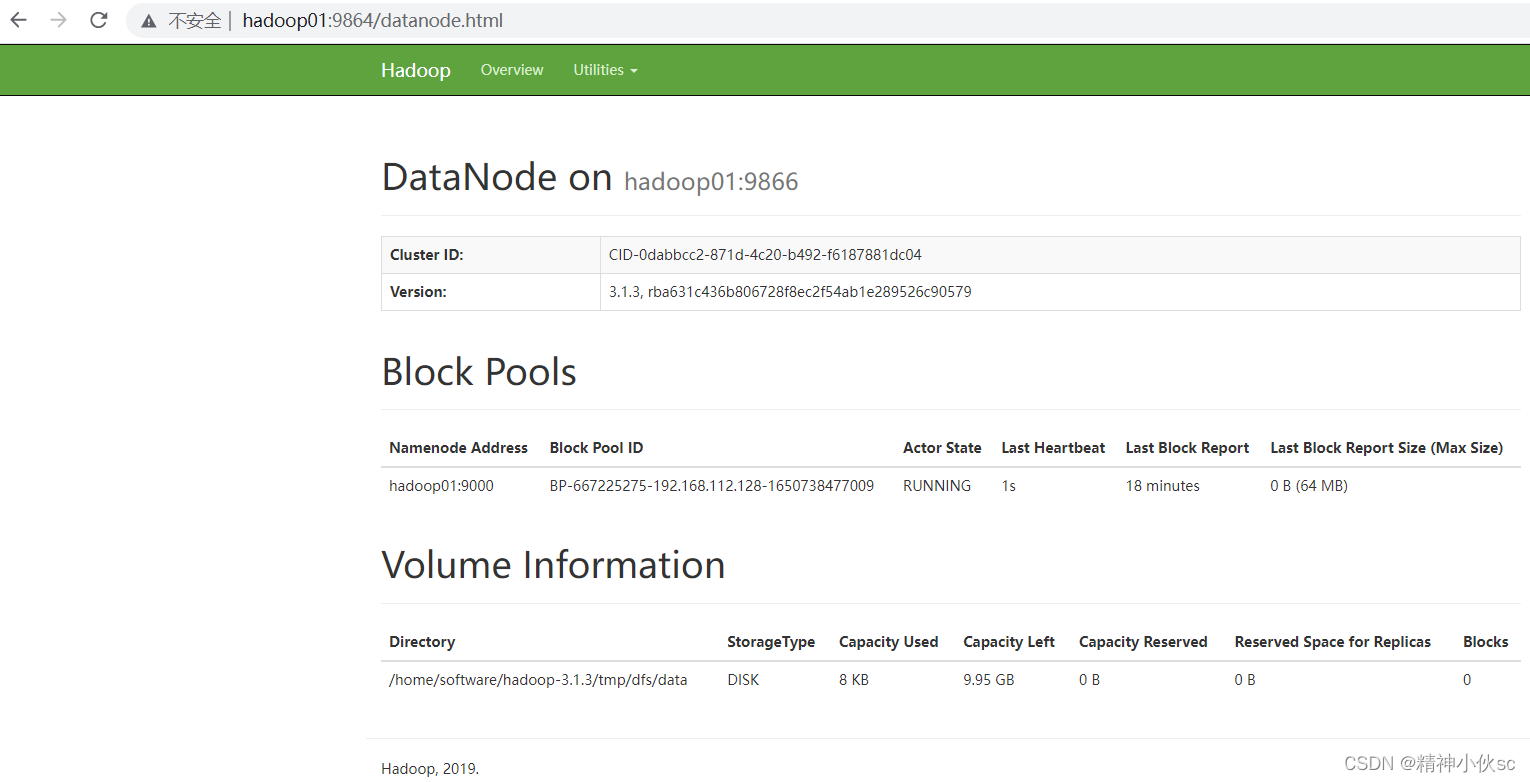
③DataNode页面访问
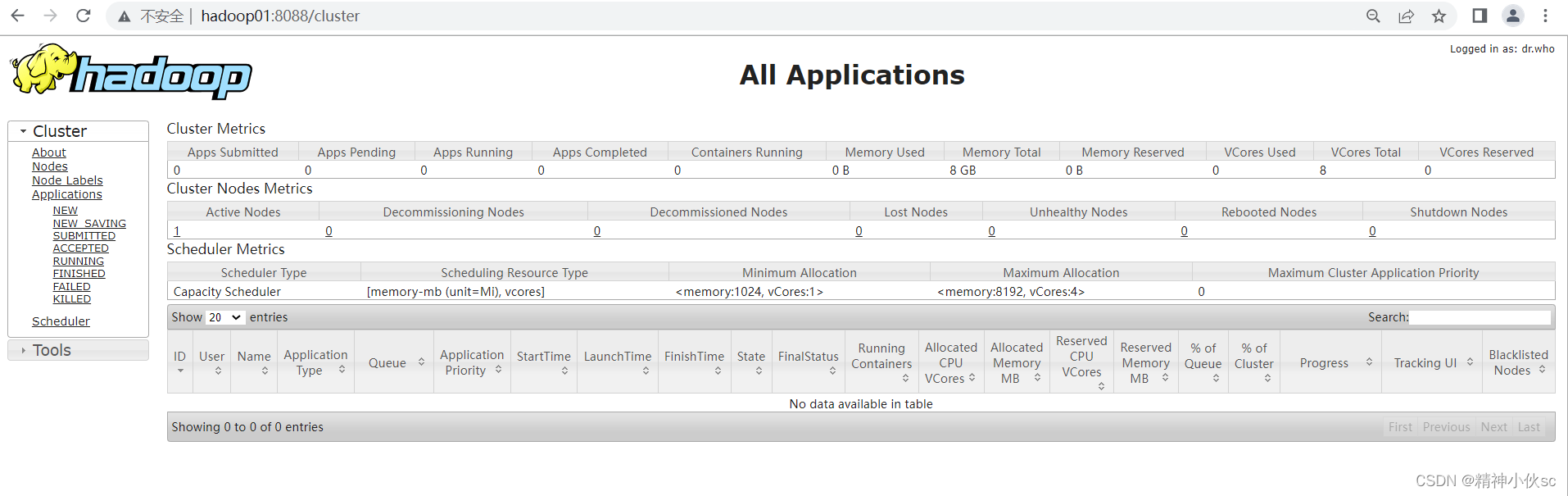
④ResourceManager页面访问
⑤NdeManager没有页面,不对外界访问