修改配置:
(1)*-evn.sh:3个模块的环境变量文件
hadoop-env.sh

修改自己jdk位置

yarn-env.sh(23行)
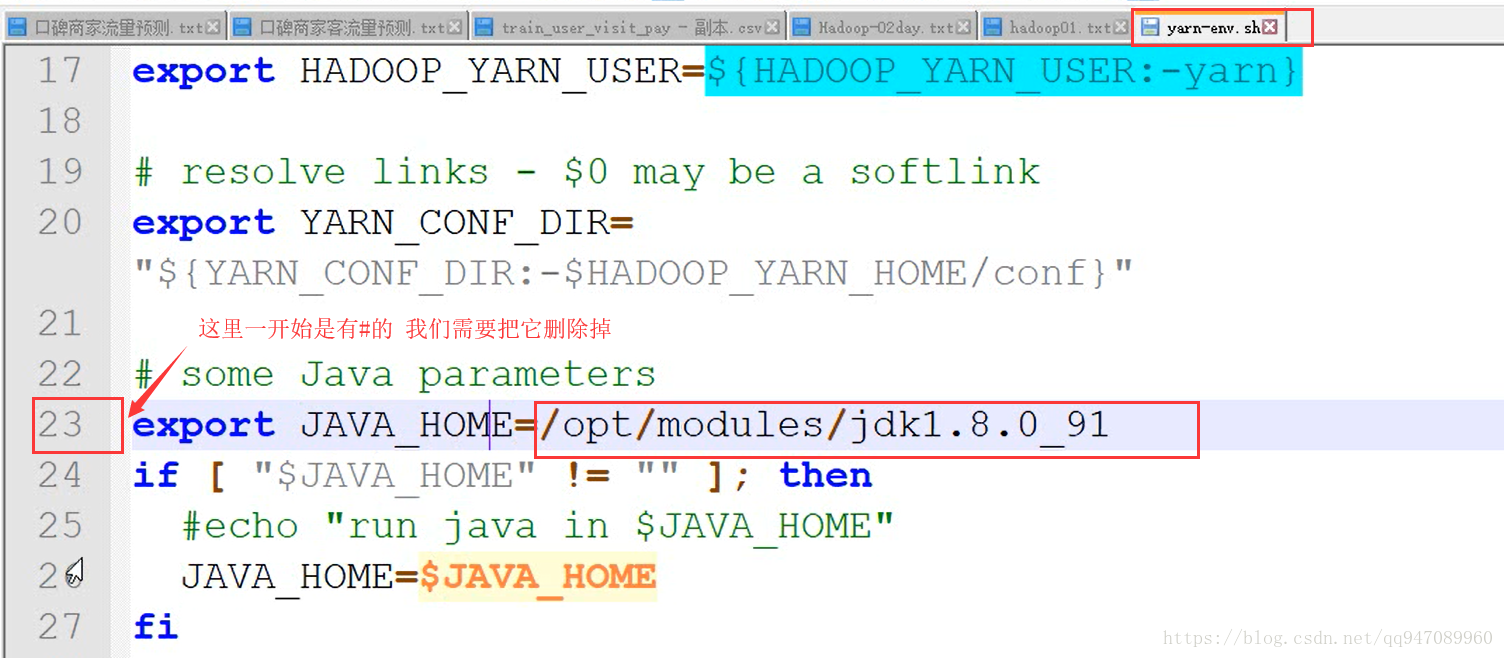
mapred-env.sh
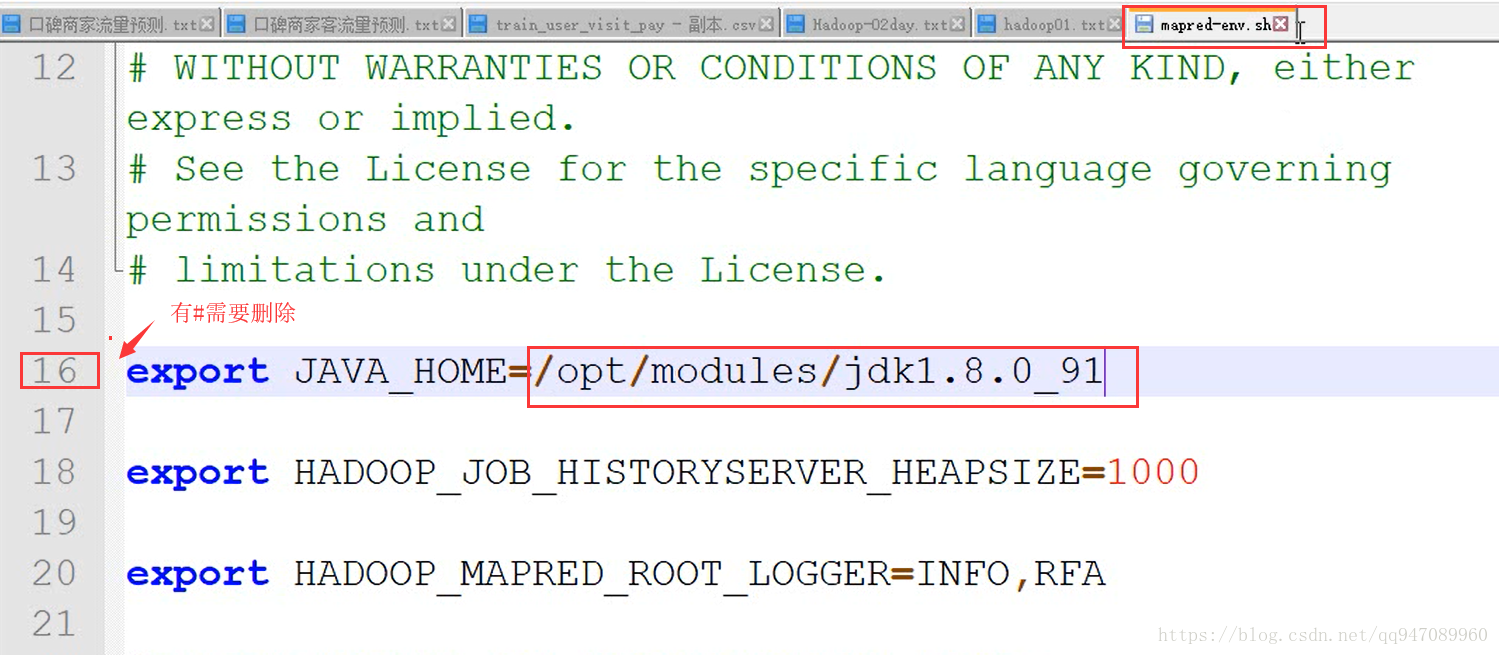
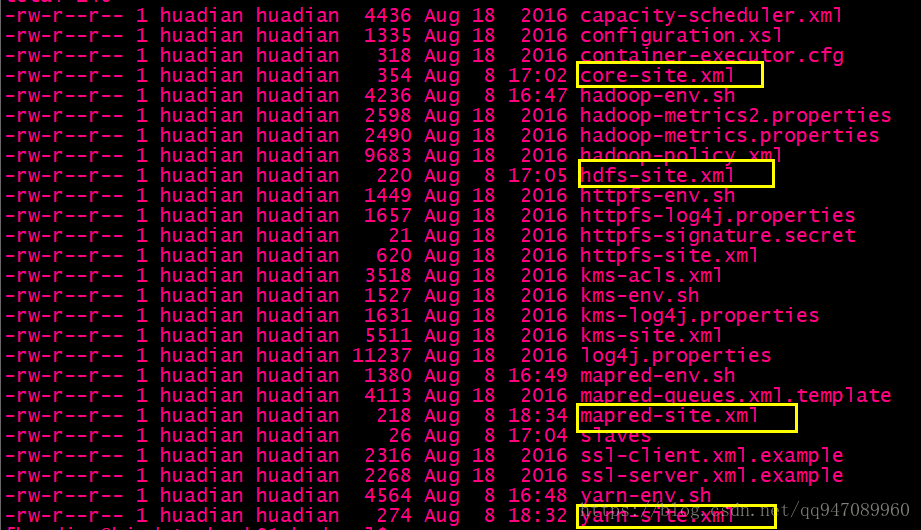
(2)按模块配置
我要修改这几个配置文件
common模块: core-site.xml
<!--指定文件系统HDFS的主机名称和端口号-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-hpsk01.huadian.com:8020</value>
</property>
<!--指定文件系统本地临时存储目录,默认值是系统/tmp-->
<!--临时目录需要自己创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.3/data/tmpData</value>
</property>HDFS模块配置: hdfs-site.xml
<!--由于是伪分布式,仅有一台机器,副本数量没有必要设置为3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>YARN配置:yarn-site.xml
<!--resourcemanager服务运行的主机名名称-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-hpsk01.huadian.com</value>
</property>
<!--告知YARN,MapReduce程序将在 其上运行-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>Mapreduce模块配置:mapred-site.xml.template( 需要把文件修改成 mapred-site.xml)
<!--指定MapReduce的程序运行在YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>测试
测试HDFS模块是否OK
-》格式化
bin/hdfs namenode -format成功的标准:
18/08/07 23:25:02 INFO util.ExitUtil: Exiting with status 0 -》启动
主节点
sbin/hadoop-daemon.sh start namenode从节点
sbin/hadoop-daemon.sh start datanode -》验证是否成功:
方式一:查看进程jps
方式二:
bigdata-hpsk01.huadian.com:50070 -》测试HDFS:
(1)怎么用
bin/hdfs dfs(2)创建一个目录
bin/hdfs dfs -mkdir -p /datas(3)查看
bin/hdfs dfs -ls /(4)上传文件
bin/hdfs dfs -put /opt/datas/input.data /datas(5)查看文件
bin/hdfs dfs -text /datas/input.data(6)删除文件
bin/hdfs dfs -rm -r -f /datas/input.data启动YARN服务
-》启动:
主节点:resourceManager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh stop resourcemanager从节点:nodeManager
sbin/yarn-daemon.sh start nodemanager
sbin/yarn-daemon.sh stop nodemanager -》验证启动:
方式一:jps
方式二:
http://bigdata-hpsk01.huadian.com:8088/测试MapReduce程序
案例:wordcount程序
准备数据:/datas/input.data
程序:
/opt/modules/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar将MapReduce应用提交到YARN上运行
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcountUsage: wordcount <in> [<in>...] <out> <in>:表示MapReduce程序要处理的数据在哪里
<out>:表示MapReduce程序处理数据之后的结果 存储在哪里,这个目录不能存在
终极提交:
