计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
基本概念
L0范数:参数空间中非0元素的个数。
L1范数:参数的绝对值之和。
L2范数:参数的平方的和再开根号。
正则化:在模型的训练过程中,惩罚参数的大小来降低模型的复杂度。
正则化方法:L1正则化、L2正则化。
稀疏:参数空间中0的个数越多,参数空间越稀疏,L0范数越小。
举例:
两组参数 , b更加稀疏
a = [1,2,3,4,5,6] L0范数为6
b = [0,2,5,0,0,0] L0范数为2
原理
L1正则化
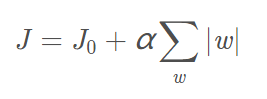
J是损失,J0是原有损失,后者是L1正则化
可以看出,参数越大,L1范数越大,损失越大
所以L1正则化可以约束参数的大小
主要目的:让参数变小,使参数稀疏,缓解过拟合(侧重稀疏)
L2正则化
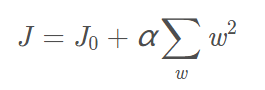
只需要说明一点
L2正则化用的不是L2范数 而是L2范数的平方
主要目的:让参数变小,缓解过拟合(侧重过拟合)
细节
为什么参数变小可以缓解过拟合?
两个角度:
- 参数变得很小后,相应的输入特征可以忽略不计,降低了模型的复杂度。
- 参数变小后,输入变化较大,输出变化相对不大,抗扰动能力强。
为了让参数稀疏,为什么不用L0正则化?
训练的过程中免不了求导操作
大家可以想象一下L0范数的公式。。。
想象不出来吧
所以L1比L0更容易优化求解
所以使用L1正则化
参数稀疏的意义?
参数稀疏后,一些参数等于0
输入的某些维度乘0后就失去了意义
换句话说,放弃了输入中一些无用的特征
一方面,可以让我们发现主要特征,方便分析
另一方面,舍弃了无用特征,降低了模型复杂度,缓解了过拟合
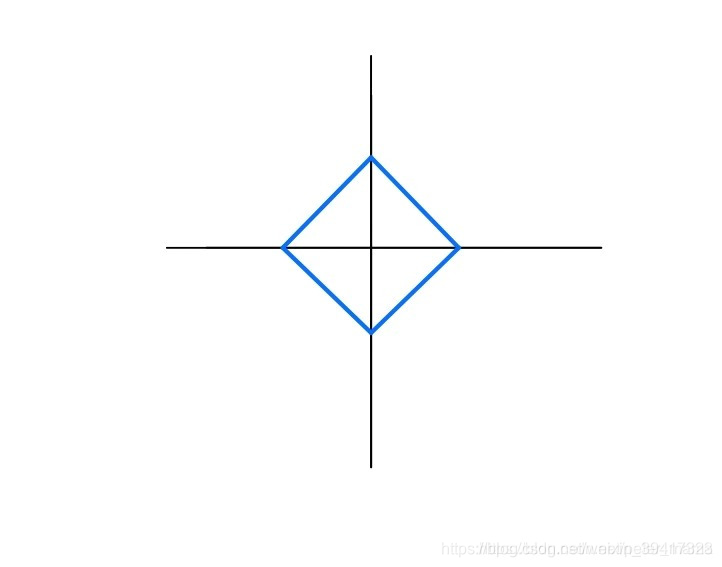
为何L1侧重稀疏,L2不可以?
假设只有两个参数:w1 w2
L1正则化等价于|w1|+|w2|<=r 也就是下图的菱形内部,包含边界
L2正则化等价于|w1|^2 +|w2|^2<=r 也就是下图圆的内部,包含边界
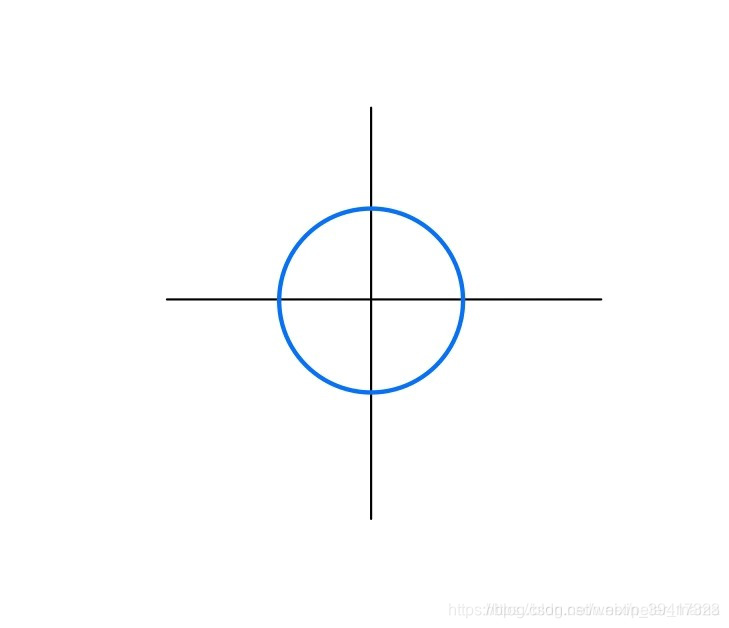
参数和损失的等高线的交点如下图:
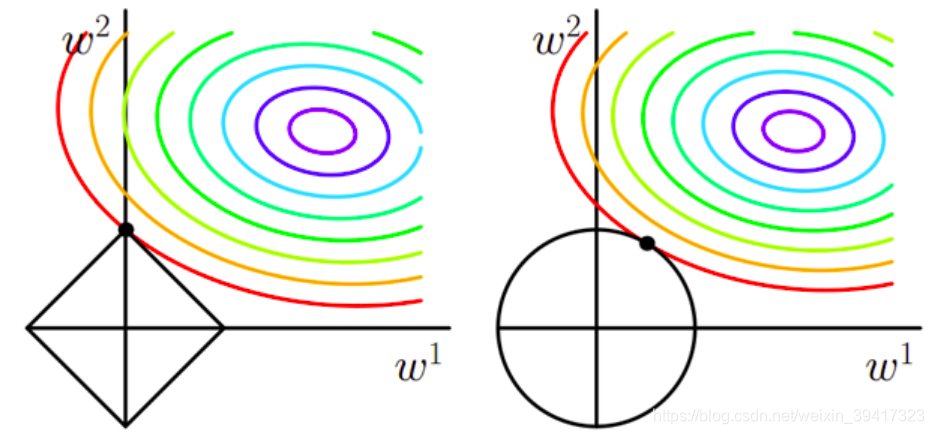
其中紫色部分代表损失小,越往外,损失越大
如果参数可以变大,也就是菱形和圆变大,那么我们可以将损失优化到紫色
可以看出,L1正则化参数更容易与等高线相交于坐标轴,也就是参数更容易等于0
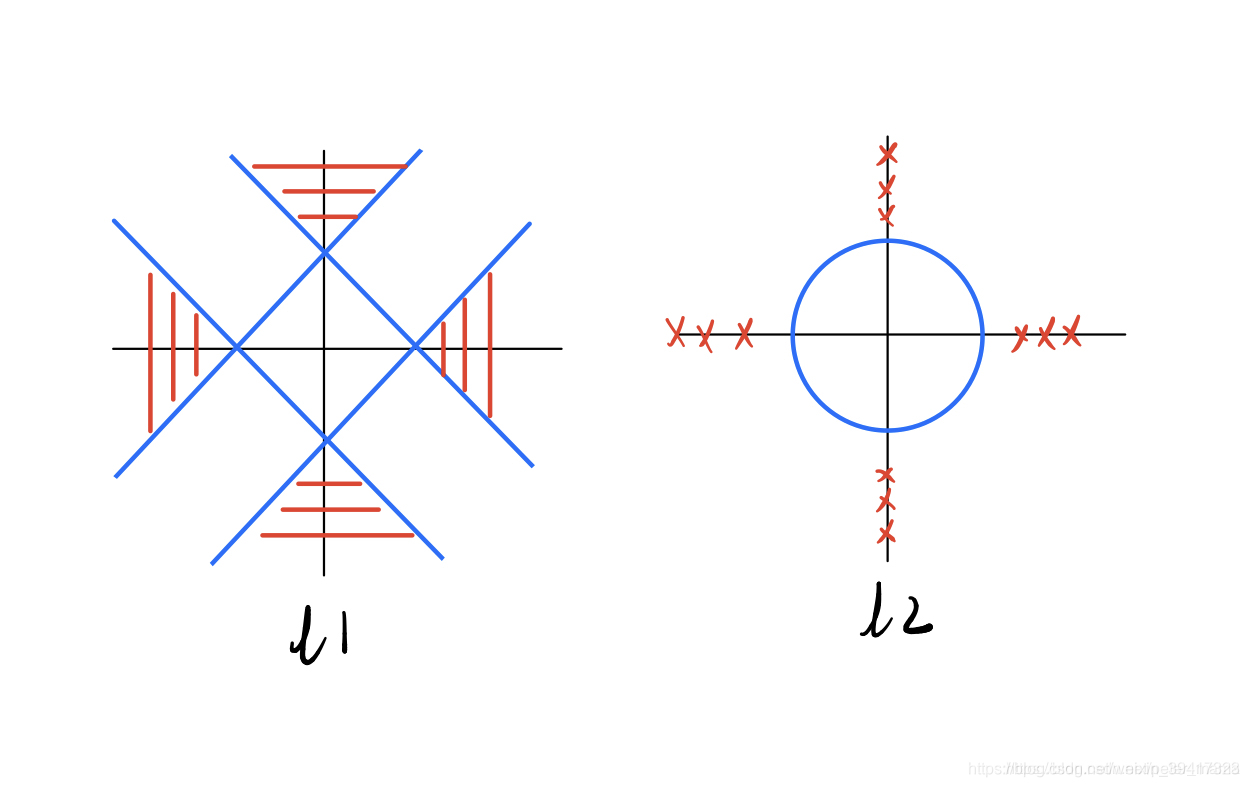
为什么L1正则化参数更容易与等高线相交于坐标轴?
如下图,显然
参数与等高线相交于坐标轴的条件是
等高线的中心落在红色区域
显然左侧的红色区域大一些
完
欢迎讨论 欢迎吐槽
