计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
池化 pooling
卷积神经网络中的一层,池化层
最直观的作用是降低feature map的维度
两种常用池化
最大池化 max pooling
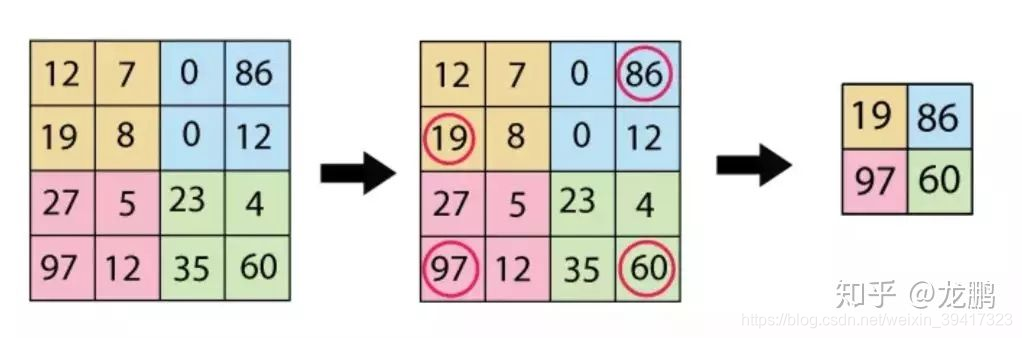
平均池化 mean pooling

最大池化选取最突出的特征,对于纹理信息敏感
平均池化关注数据整体,对背景信息敏感
最大池化用的多,两者也可以交替使用
池化的作用
- 降低feature map维度,降低参数量和计算量
- 减少了参数量通常缓解了过拟合
- 在一定程度上增强了对目标空间位置变化的鲁棒性(平移不变性)
- 增加了每个像素的感受野,比如经过上面的2*2的池化,每一个像素对应了上一层的4个像素
- 池化也是网络非线性的体现
池化的反向传播
max pooling

mean pooling
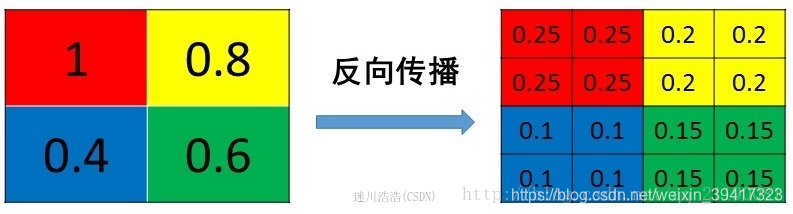
注意:
(对应上图分析)
mean pooling并不是直接复制4个1到左上角的4个点
因为反向传播后,由4个梯度变成了16个梯度
如果不除以4,梯度扩大4倍
如果每层都这样,会梯度爆炸
其它池化
重叠池化
每个池化的部分有重叠
缓解了上述池化将每部分独立的问题
增加了参数量,提升不大
随机池化
比如:
4 2
1 3
那么池化后,40%是4, 20%是2 ,10%是1 ,30%是3
最大和平均太绝对
随机池化可能会让结果变好一些
当然也可能变差
但是由于随机性
至少让可能性增多了一些
全局池化
比如256*256的一张feature map直接池化为1个值
分为
全局最大池化 global max pooling GMP
全局平均池化 global average pooling GAP

可以取代全连接层,这大幅降低了参数,缓解过拟合
每一个feature map对应输出的一个值,也就在一定程度上赋予了每个feature map特别的意义,缓解了神经网络的黑箱子属性
但是
上节说到,全连接层实现特征的组合
也就是说,全连接层的输入可以是相对低级的特征
通过全连接层的组合使特征变高级
如果使用全局池化
就少了特征组合的环节
每一个维度的输出对应一个feature map,也就是独立的
那么feature map的特征就必须是相对高级的特征了
几乎所有的学习压力都给了卷积层
拟合速度相对变慢
空间金字塔池化
输入图像可以是任意尺寸
可以获得多尺度特征
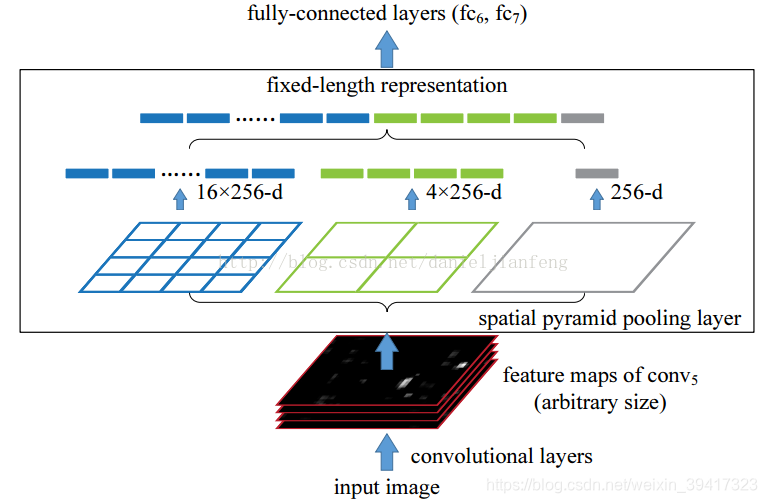
如上图,空间金字塔池化的一个例子
输入图像大小任意,所以输入的feature map大小任意
但是我们将其池化为固定的4*4 2*2 1*1
所以池化模板的大小是需要根据输入调整的
最后,再来谈一下max pooling 和 mean pooling的理解
举个例子吧
如果想要识别图像中一个比较小的物体
可能在feature map中有少数几个比较大的数
如果平均池化,这几个大数可能就被平均没了。。。
所以这个时候用max pooling就比较好一些
如果想要判断图像的类别
那么可能所有的信息都会参与
这个时候适合用mean pooling
当然,不是绝对的
完
欢迎讨论 欢迎吐槽
