计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
K均值聚类算法
k-means clustering algorithm
K-Means
原理
聚类问题:
样本标签未知,总类别数未知
使用聚类算法,发现样本在特征空间中的分布规律
从而把样本们分为不同的类别
过程:
在样本的特征空间中,
- 随机选取k个样本,作为聚类质心(中心)
- 每一个样本跟随一个离自己最近的质心,分为k个类
- 每一个类重新计算质心((1,2),(2,1),(3,3)的质心就是(2,2)),得到k个质心。注意:与第一步中真实的样本作为质心不同,这个时候经过计算得到的质心未必存在。比如上述的例子中并不存在(2,2)。所以此时的质心是虚拟的。
重复进行2、3直至模型拟合。
拟合判断标准
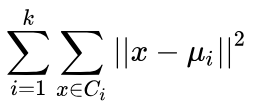
u是质心,总共k个
C是一类样本的集合
上述公式的意义就是:
所有样本点与自己的质心的欧氏距离平方的和
显然,该数值越小模型性能越好
即可以作为损失函数
当该损失函数稳定时,判断模型拟合
优缺点分析
高斯分布性能好,非凸分布性能不好
自己画了个图,方便解释:
可以看出,高斯分布的质心在数据内部
非凸分布的质心甚至和数据没什么重叠
所以分布决定质心存在的位置
质心位置的好坏影响了K-Means的性能

超参数K
K作为该算法唯一的超参数,是一把双刃剑
优点:选定K,模型的训练就不需要干预了,很简单
缺点:K的影响很大,K选不好,模型就很差,导致性能不稳定
选取方法:
1.经验。。。
2.手肘法
选若干个k,比如2,3,4,5,6
分别跑一遍K-Means,稳定后,得到5个损失(上面的那个公式)
一般损失先下降快,后下降慢,存在一个拐点,如下图
K=4可能是一个不错的选择
因为曲线像手肘,所以叫手肘法。。。

3.ISODATA
该方法的K是动态变化的
如何变化?
该算法有分裂和合并操作
分裂:一类变两类
合并:两类变一类
- 选定初始K0,一般最后的K的范围大概是0.5*K0~2*K0。所以,即使K可以动态变化,K0的选择也得多少靠点谱
- 设定每类最少的样本数,如果少于最少样本数,这个类不能分裂
- 计算方差评定一个类中所有样本的分散程度,分散程度大于阈值,并且满足2中的条件,进行分裂
- 计算两个质心的距离,小于阈值,两个类合并
其余步骤和普通K-Means一样,只是每次聚类结束,要进行分裂和合并操作
随机的质心不好对性能影响很大
如图,随机的质心导致了不良的性能

解决方法:K-Means++
该方法和K-Means仅在初始选择质心的时候不同:
随机选取第1个质心
选第n+1个质心时,计算剩余样本点与前n个质心的距离
离前n个质心距离越远,该样本点被选为第n+1个质心的概率越大
计算量
如果有N个样本,分为K类,迭代T轮
那么计算复杂度是O(NKT)
优点:复杂度是线性的
缺点:即使是线性的,当数据量太大时,计算量依然可观
解决方法:
1.利用三角形原理(elkan K-Means)
AB+BC>AC
如果样本点是X,有两个质心I,J
那么XI+XJ>IJ
换个角度来看
如果XI+XI<IJ
联立两个式子
XI<XJ
也就是说我们不需要计算出每一个样本点和所有质心的距离
我们只需要计算样本点和一个质心的距离以及K个质心之间的距离
这样就可以判断样本点属于哪一个质心
当然,如果XI+XI<IJ不成立,那么我们还是要计算XJ
不过,已经减少了很多计算量了
尤其是当模型快要拟合时,上式几乎都是成立的
2.Mini Batch K-Means
一般两种做法:
- 无放回采样进行K-Means,拟合后继续采样增加数据,再进行K-Means
- 对n个小样本集进行K-Means,然后取均值作为质心
其余缺点
- 对噪声、离群点敏感(可以将求平均改为求中位数)
- 每个样本只能被归为一类
其余优化
- 核函数高维映射
- 特征归一化,比如(1000,1)和(5,2)的距离主要取决了第一个维度,这就不好了,需要归一化
- 数据预处理,去除一些噪声和离群点
聚类知识庞大,还有很多高级的优秀方法
如果不是专门研究这个方向
了解这些足以
完
欢迎讨论 欢迎吐槽
