计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
由来
两个角度
1.将非线性问题转换为线性问题
左图需要用非线性的曲线分类
并不是说这样不行
只是有些问题要求必须线性分类
比如,SVM就需要超平面分类(超平面就是线性的)
将特征空间提高维度
就可以用线性的平面进行分类
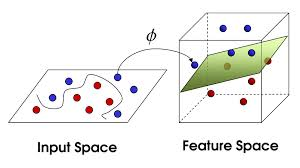
2.低维特征空间表征能力不够
有时候不需要一定转换为线性问题
但是,低维空间的表征能力较弱
将特征提升维度,可以提升模型的表达能力
抽象例子:
用几条腿,是否下蛋对动物进行分类,两维特征
用几条腿,是否下蛋,几条腿乘是否下蛋对动物分类,三维特征
我无法说清楚几条腿乘是否下蛋是个什么特征,这也是高维特征的一个体现吧
后者对特征进行了简单的组合,增加了一个特征维度,增强了模型的表达能力
具体例子:
我们在K-Means中需要计算点和质心的距离
以欧式距离为例
d=(x1-x2)^2+(y1-y2)^2
x和y代表两个维度的特征
以上方法相当于将每个维度的特征独立了
换个做法
(x1y1-x2y2)^2+x1y2(随便编的式子)
将特征融合,就增加了维度,提升了表征能力
原理
我们通过Φ()函数实现特征从低维到高维的映射
但是这并不是核函数!
比如现在有两维的特征,x,y
我们使用Φ()进行映射,组成了三维特征,x,y,xy
对于A样本,特征为Φ(xa,ya)=xa+ya+xa*ya(式子编的,可能是它们的任意组合)
对于B样本,特征为Φ(xb,yb)=xb+yb+xb*yb
在一些求解过程中,我们经常要计算<Φ(A),Φ(B)>
点积:<(x1,x2,x3),(x4,x5,x6)>=x1x4+x2x5+x3x6
那么核函数的作用就是
K((xa,ya),(xb,yb))=<Φ(xa,ya),Φ(xb,yb)>
所以说,核函数和映射没有关系,它只是一个计算工具
进一步思考
如果有了核函数
我们就不需要计算Φ(xa,ya),Φ(xb,yb)
再进一步
我们甚至不需要知道Φ()是什么
我们只需要指定一个K()
只要K()满足核函数的数学要求,它就间接实现了映射的功能
那么我们为什么不跳过Φ()而直接使用核函数K()呢?
这就是核函数的原理和意义
常用核函数
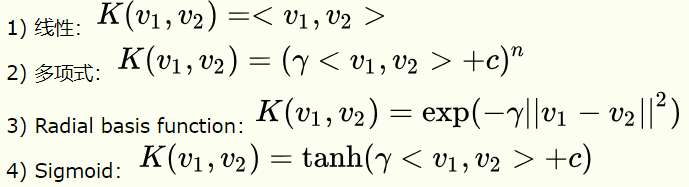
其中v1和v2是两个样本对应的特征
至于用哪个核函数?
除非是被做烂了的模型
否则慢慢试吧
这是世界性难题
当然存在规律,但是我的能力达不到了。。。
完
欢迎讨论 欢迎吐槽
