最近呢,接到一个项目:
项目内容:
1.利用Python编写爬虫程序,爬取https://ncov.dxy.cn/ncovh5/view/pneumonia页面中当天的“疫情数据”并保存到本地
2.根据爬取的数据可视化展示
项目实现
很显然,该项目分为两个部分:
- 使用爬虫获取数据(request,beautifulsoup,pyquery……)
- 进行数据可视化(pyecharts,matplotlib……)
我们进入该网址使用快捷键F12浏览源代码

经过漫长的寻找我们找到了所需要的数据:
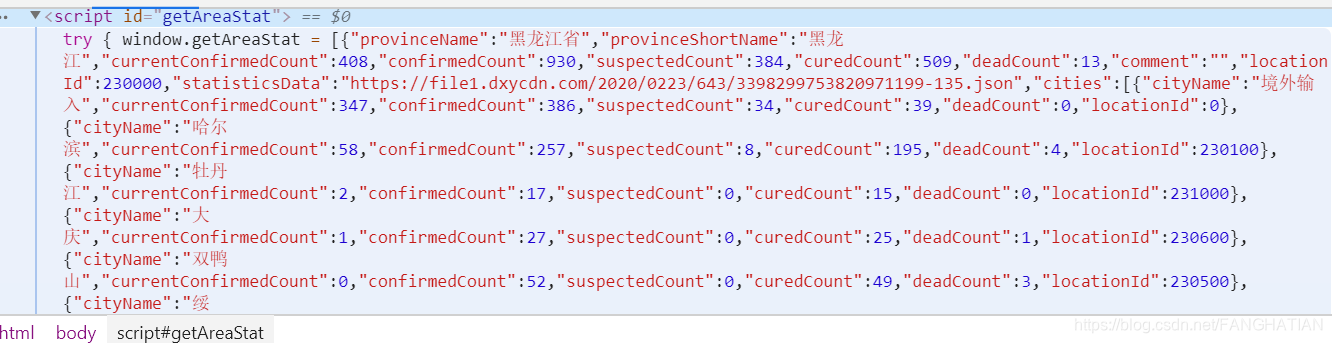
经过整理,我们发现它的数据是这样的:
[{{“provinceName”:“黑龙江省”,“provinceShortName”:“黑龙江”,“currentConfirmedCount”:408,“confirmedCount”:930,“suspectedCount”:384,“curedCount”:509,“deadCount”:13,“comment”:"",“locationId”:230000,“statisticsData”:“https://file1.dxycdn.com/2020/0223/643/3398299753820971199-135.json”,"cities":[{“cityName”:“境外输入”,“currentConfirmedCount”:347,“confirmedCount”:386,“suspectedCount”:34,“curedCount”:39,“deadCount”:0,“locationId”:0},{…………},{…………},{…………}………}………………]
所以,经过观察得知它是把所有省的信息整合成一个字典,把这些字典并称一个列表;
在省的字典里不仅包含了省的信息还包含了一对键值对——“cities”:[],就是说它把所有该省的城市的信息整合成一个列表,作为键(cities)的对应值;
而在这个列表中,包含着所有的城市的信息是以字典的凡是存储在该列表中的;
再观察这个字典可以知道,它不仅包含了城市名字的键值对(cityName),还包含着
currentConfirmedCount(现存确诊人数),
confirmedCount(累计确诊人数),
suspectedCount(疑似人数),
curedCount(治愈人数),
deadCount(死亡人数),
locationId(地区代码)
————————————————————————
这样我们就可以通过方法获取信息了,详见下面代码
我们一边看代码一边讲:
这里我们先导入模块:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
import matplotlib.pyplot as plt
from matplotlib.pyplot import savefig
部分模块后面会用到
然后呢我们使用requests库获得源码:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
然后呢我们对其进行格式化并获取json对象
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonobj = json.loads(data)
注意:
我们这里只是获取了全国省份的信息并没有获取城市的信息
(如果不会pyquery可参考https://www.jianshu.com/p/770c0cdef481)
随后我们获取城市信息:
for shengfen in jsonobj:
chengshi[shengfen.get('provinceName')] = shengfen.get('cities')
我们获取了cities所对应的值(一个包含着数个字典的列表)
for v in chengshi.keys():
cities_data = []
for item in chengshi.get(v):
dic = {}
dic["城市名字"] = item["cityName"]
dic["现存确诊人数"] = item["currentConfirmedCount"]
dic["累计确诊人数"] = item["confirmedCount"]
dic["疑似人数"] = item["suspectedCount"]
dic["治愈人数"] = item["curedCount"]
dic["死亡人数"] = item["deadCount"]
cities_data.append(dic)
#获取对应键值对
if (cities_data.__len__() > 0):
print("写入数据...")
try:
df = pd.DataFrame(cities_data)
filename = v + '城市疫情数据.scv'
df.to_csv(filename, encoding="gbk", index=False)
filename_list.append(filename)
print("写入成功...")
except:
print("写入失败....")
到这里,我们已经成功获取了所需的数据并保存为csv格式

然后呢,我们用pandas模块读取数据,并处理成我们想要的形式(我们以累计确诊人数为例)
dict_pie = {}
wenben = pd.read_csv(filename, encoding='gbk')
for n in range(wenben.shape[0]):
a = wenben.loc[n, ['城市名字', '累计确诊人数']]
dict_pie[a[0]] = a[1]
explode.append(0)
对数据的处理和获取呢就差不多到这里
————————————————————————
接下来就是进行数据可视化(matplotlib)
直接贴代码吧(饼状图)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.pie(dict_pie.values(), autopct='%1.1f%%', explode=tuple(explode), labels=dict_pie.keys())
plt.title(filename[0:-4] + '累计确诊人数')
plt.axis('equal')
savefig(filename[0:-4] + '累计确诊人数' + '饼状图.png')
plt.close()
还有柱状图的
list_1, color = [], []
color_1 = ['r', 'g', 'b', 'c', 'm', 'k', 'y']
color = []
for k in list(dict_pie.keys()):
if dict_pie.get(k) == 0 or dict_pie.get(k) == m:
list_1.append(k)
for k in list_1:
del dict_pie[k]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(28, 10))
plt.title(filename[0:-4] + '累计确诊人数', fontsize=28)
for a in range(len(dict_pie)):
color.append(color_1[a % 7])
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.bar(dict_pie.keys(), dict_pie.values(), color=color)
for x, y in dict_pie.items():
plt.text(x, y, y, ha='center', va='bottom', fontsize=18)
savefig(filename[0:-4] + '累计确诊人数' + '柱状图.png')
plt.close()
最后呢,完整代码贴一下(希望你们能看懂/wulian)
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import savefig
def get_data_cities():
global filename_listt
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
chengshi = {}
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonobj = json.loads(data) # json对象
print("数据抓取成功...")
for shengfen in jsonobj:
chengshi[shengfen.get('provinceName')] = shengfen.get('cities')
for v in chengshi.keys():
cities_data = []
for item in chengshi.get(v):
dic = {}
dic["城市名字"] = item["cityName"]
dic["现存确诊人数"] = item["currentConfirmedCount"]
dic["累计确诊人数"] = item["confirmedCount"]
dic["疑似人数"] = item["suspectedCount"]
dic["治愈人数"] = item["curedCount"]
dic["死亡人数"] = item["deadCount"]
cities_data.append(dic)
if (cities_data.__len__() > 0):
print("写入数据...")
try:
df = pd.DataFrame(cities_data)
filename = v + '城市疫情数据.scv'
df.to_csv(filename, encoding="gbk", index=False)
filename_list.append(filename)
print("写入成功...")
except:
print("写入失败....")
def shujvzhengli(filename):
global explode
dict_pie = {}
wenben = pd.read_csv(filename, encoding='gbk')
for n in range(wenben.shape[0]):
a = wenben.loc[n, ['城市名字', '累计确诊人数']]
dict_pie[a[0]] = a[1]
explode.append(0)
return dict_pie
def bingzhuangtu(filename, dict_pie):
global explode
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.pie(dict_pie.values(), autopct='%1.1f%%', explode=tuple(explode), labels=dict_pie.keys())
plt.title(filename[0:-4] + '累计确诊人数')
plt.axis('equal')
savefig(filename[0:-4] + '累计确诊人数' + '饼状图.png')
plt.close()
def zhuzhuangtu(filename, dict_pie):
list_1, color = [], []
color_1 = ['r', 'g', 'b', 'c', 'm', 'k', 'y']
color = []
for k in list(dict_pie.keys()):
if dict_pie.get(k) == 0 or dict_pie.get(k) == m:
list_1.append(k)
for k in list_1:
del dict_pie[k]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(28, 10))
plt.title(filename[0:-4] + '累计确诊人数', fontsize=28)
for a in range(len(dict_pie)):
color.append(color_1[a % 7])
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.bar(dict_pie.keys(), dict_pie.values(), color=color)
for x, y in dict_pie.items():
plt.text(x, y, y, ha='center', va='bottom', fontsize=18)
savefig(filename[0:-4] + '累计确诊人数' + '柱状图.png')
plt.close()
if __name__ =='__main__':
filename_list = []
get_data_cities()
for a in ['饼状图','柱状图']:
for filename in filename_list:
explode = []
dict_pie = shujvzhengli(filename)
tubiaoleixing = {'饼状图': bingzhuangtu, '柱状图': zhuzhuangtu}
m = 0
tubiaoleixing[a](filename, dict_pie)
pyecharts的代码还在改进,今天时间不够了,明天还要上学,各位大佬求个关注,点个赞(码字不易)
**
人生苦短,我用python
**
