前言
今天给大家介绍的是Python爬取新冠疫情数据并实现数据可视化,在这里给需要的小伙伴们代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对招聘网站数据进行爬取。
在每次进行爬虫代码的编写之前,我们的第一步也是最重要的一步就是分析我们的网页。
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。
开发工具
Python版本: 3.8
相关模块:
requests模块
lxml模块
openpyxl模块
pandas模块
pyecharts模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
浏览器中打开我们要爬取的页面
按F12进入开发者工具,查看我们想要的疫情数据在哪里
这里我们需要页面数据就可以了
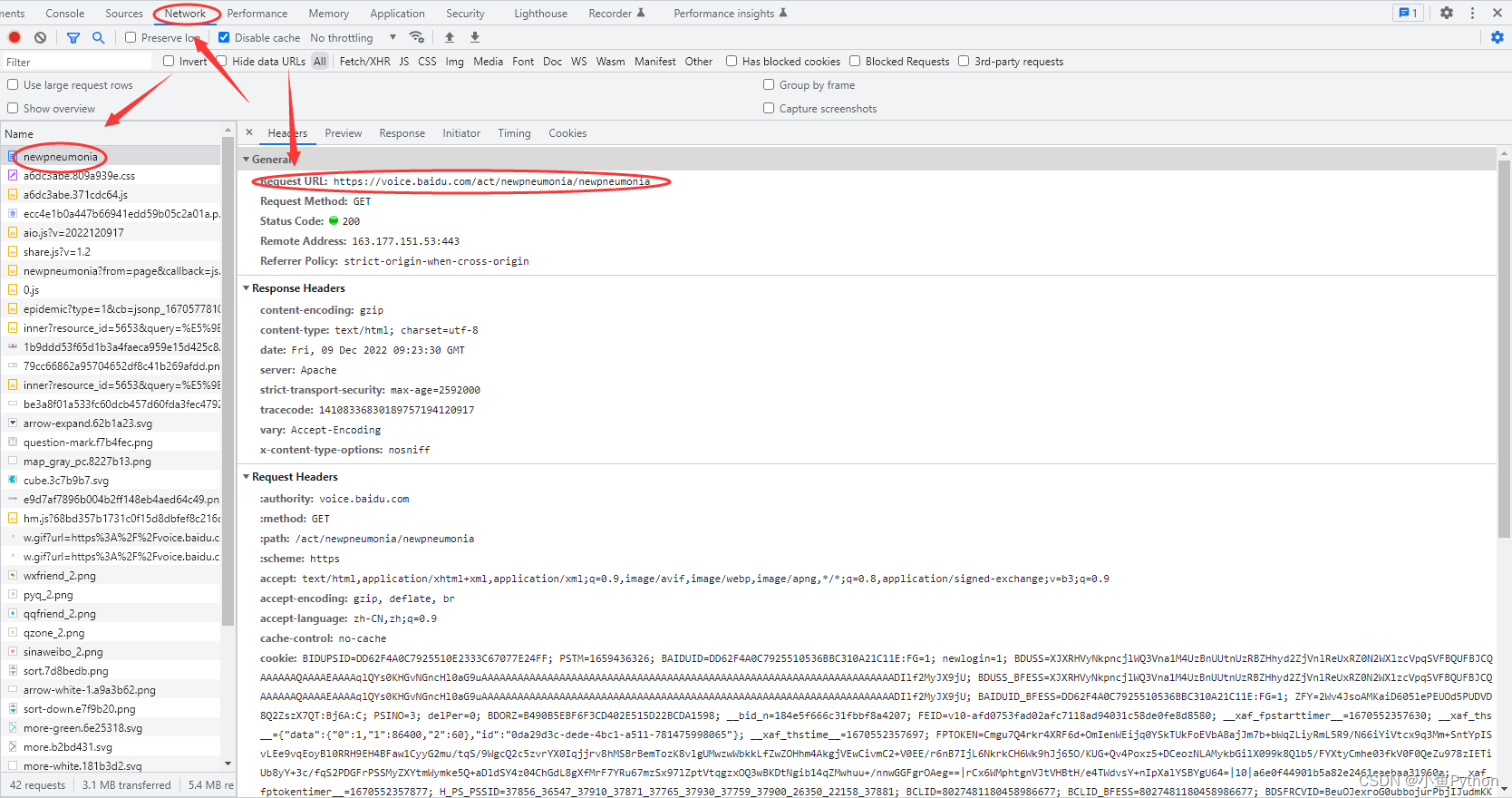
代码实现
Epidemic crawler.py
import requests
from lxml import etree
import json
import openpyxl
#通用爬虫
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia'
headers = {
"User-Agent": "换成自己浏览器的"
}
response = requests.get(url=url,headers=headers).text
#在使用xpath的时候要用树形态
html = etree.HTML(response)
#用xpath来获取我们之前找到的页面json数据 并打印看看
json_text = html.xpath('//script[@type="application/json"]/text()')
json_text = json_text[0]
print(json_text)
#用python本地自带的库转换一下json数据
result = json.loads(json_text)
print(result)
#通过打印出转换的对象我们可以看到我们要的数据都要key为component对应的值之下,所以现在我们将值拿出来
result = result["component"]
#再次打印看看结果
print(result)
#获取国内当前数据
result = result[0]['caseList']
print(result)
#创建工作簿
wb = openpyxl.Workbook()
#创建工作表
ws = wb.active
#设置表的标题
ws.title = "国内疫情"
#写入表头
ws.append(["省份","累计确诊","死亡","治愈"])
#获取各省份的数据并写入
for line in result:
line_name = [line["area"],line["confirmed"],line["died"],line["crued"]]
for ele in line_name:
if ele == '':
ele = 0
ws.append(line_name)
#保存到excel中
wb.save('./china.xls')
User-Agent如何获取

遇到的问题Excel xlsx file; not supported解决办法
原因:xlrd1.2.0之后的版本不支持xlsx格式,支持xls格式
办法一:
卸载新版本 pip uninstall xlrd
安装老版本:pip install xlrd=1.2.0 (或者更早版本)
方法二:
将xlrd用到的excel版本格式修改为xls(保险起见,另存为xls格式)
疫情数据结果展示

Visualization.py
#可视化部分
import pandas as pd
from pyecharts.charts import Map,Page
from pyecharts import options as opts
#设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
#打开文件
df = pd.read_excel('china.xls')
#对省份进行统计
data2 = df['省份']
data2_list = list(data2)
data3 = df['累计确诊']
data3_list = list(data3)
data4 = df['死亡']
data4_list = list(data4)
data5 = df ['治愈']
data5_list = list(data5)
c = (
Map()
.add("治愈", [list(z) for z in zip(data2_list, data5_list)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(),
visualmap_opts=opts.VisualMapOpts(max_=200),
)
)
c.render()
Cumulative = (
Map()
.add("累计确诊", [list(z) for z in zip(data2_list, data3_list)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(),
visualmap_opts=opts.VisualMapOpts(max_=200),
)
)
death = (
Map()
.add("死亡", [list(z) for z in zip(data2_list, data4_list)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(),
visualmap_opts=opts.VisualMapOpts(max_=200),
)
)
cure = (
Map()
.add("治愈", [list(z) for z in zip(data2_list, data5_list)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(),
visualmap_opts=opts.VisualMapOpts(max_=200),
)
)
page = Page(layout=Page.DraggablePageLayout)
page.add(
Cumulative,
death,
cure,
)
#先生成render.html文件
page.render()
疫情数据数据可视化

最后
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
里面有适合小白新手的Python实战教程给到大家~
快来和小鱼一起成长进步吧!
① 100+多本PythonPDF(主流和经典的书籍应该都有了)
② Python标准库(最全中文版)
③ 爬虫项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)