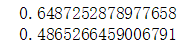AQI分析与预测
背景介绍
AQI,指空气质量指数,用来衡量空气清洁或污染的程度。值越小,表示空气质量越好。
分析目标
- 哪些城市的空气质量较好/较差?
- 空气质量在地理位置分布上,是否具有一定的规律性?
- 临海城市的空气质量是否有别于内陆城市?
- 空气质量主要受哪些因素影响?
- 全国城市空气质量普遍处于何种水平?
- 怎样预测一个城市的空气质量?
1、读取数据
#导入相对应的数据处理模块
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import warnings
sns.set(style='darkgrid')
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')2、加载数据集
data = pd.read_csv("./data.csv")
data.head()
3、数据清洗
3.1缺失值探索
data.isnull().sum()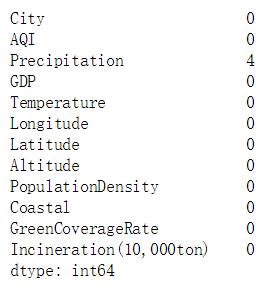
###看看数据的核密度图,再决定如何去填充数据。
data['Precipitation'].skew()
sns.distplot(data['Precipitation'].dropna())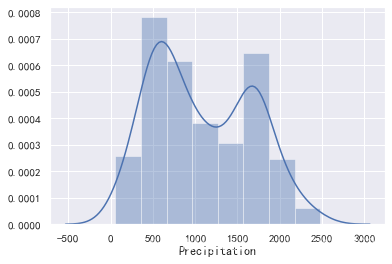
data.fillna({'Precipitation': data['Precipitation'].median()}, inplace=True)
data.info()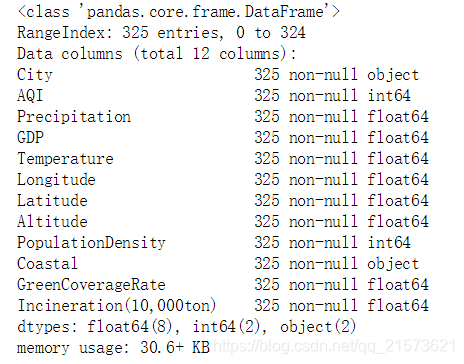
3.2异常值
3.2.1 发现异常值
- 通过describe查看数据数值信息
- 置信区间方式
- 使用箱线图辅助
- 相关异常检测算法
sns.distplot(data['GDP'])
data['GDP'].skew()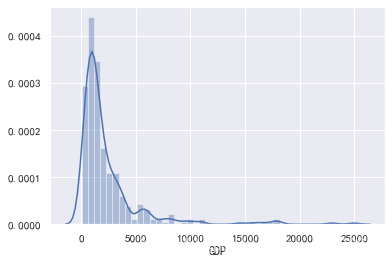
mean, std = data['GDP'].mean(), data['GDP'].std()
lower, upper = mean - 3 * std, mean + 3 * std
print("取信区间", [lower, upper])
data['GDP'][(data['GDP']<lower)|(data['GDP'] > upper) ]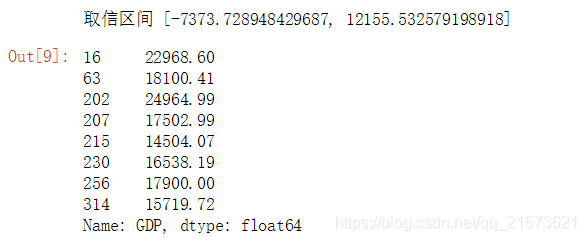
3.2.2异常值处理
- 删除异常值
- 视为缺失值处理
- 对数转换
- 使用临界值填充
- 使用分箱离散化处理
fig, ax = plt.subplots(1, 2)
sns.distplot(data['GDP'], ax = ax[0])
sns.distplot(np.log(data['GDP']), ax = ax[1])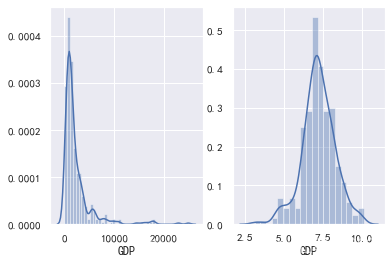
3.3重复值
data.duplicated().sum()
data[data.duplicated(keep=False)]
data.drop_duplicates(inplace=True)4、数据分析
4.1 空气质量最好的5个城市
t = data[['City', 'AQI']].sort_values('AQI')
plt.xticks(rotation=45)
sns.barplot(x='City', y='AQI', data=t.iloc[:5])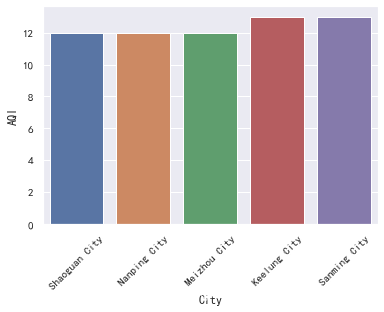
4.2 全国城市的空气质量
4.2.1 城市空气质量等级统计
def value_to_level(AQI):
if AQI >=0 and AQI <= 50:
return "一级"
elif AQI >=51 and AQI <= 100:
return "二级"
elif AQI >=101 and AQI <= 150:
return "三级"
elif AQI >=151 and AQI <= 200:
return "四级"
elif AQI >=201 and AQI <= 300:
return "五级"
else:
return "六级"
level = data["AQI"].apply(value_to_level)
display(level.value_counts())
sns.countplot(x = level, order = ["一级","二级","三级","四级","五级","六级" ])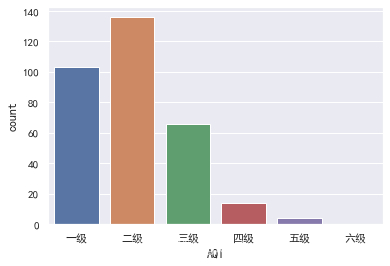
4.2.2空气质量指数分布
sns.scatterplot(x="Longitude", y="Latitude", hue="AQI", palette=plt.cm.RdYlBu, data=data)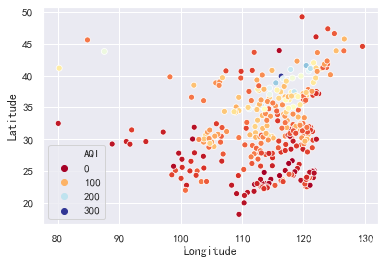
4.3 临海城市是否空气质量优于内陆城市
display(data["Coastal"].value_counts())
sns.countplot(x="Coastal", data=data)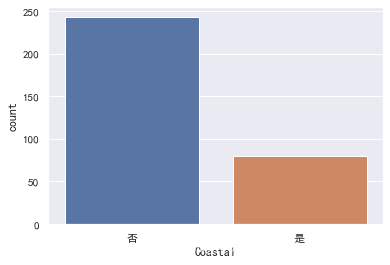
sns.violinplot(x="Coastal", y = "AQI", data=data, inner=None)
sns.swarmplot(x="Coastal", y = "AQI", color="g", data=data)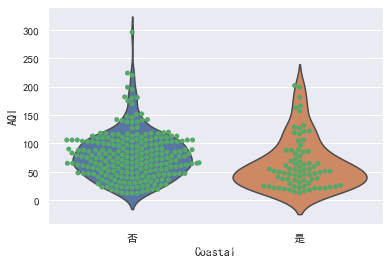
###差异检验 两个样本的t检验
###查看临海城市与内陆城市的均值差异是否显著
from scipy import stats
coastal = data[data["Coastal"] =="是"]["AQI"]
# data[data["Coastal"] =="是"][]
inland = data[data["Coastal"] =="否"]["AQI"]
###进行方差齐性检验,为后续的两样本t检验服务
stats.levene(coastal, inland)
###进行两样本的t检验,两样本的方差相同与不相同,取得的结果是不同的
##equal_var方差是否相同
stats.ttest_ind(coastal, inland, equal_var=True)![]()
4.4 空气质量主要受哪些因素影响?
###空气质量主要受哪些因素影响
###人口密度大,是否会对空气质量造成负面影响
###绿化率高,是否会提高空气质量
######散点图矩阵
sns.pairplot(data[["AQI", "PopulationDensity", "GreenCoverageRate"]], )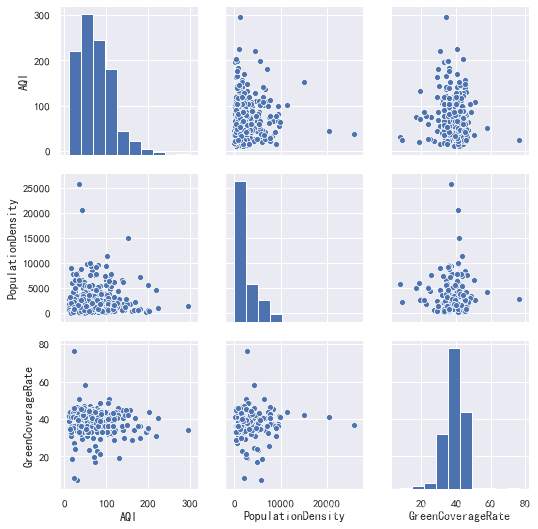
plt.figure(figsize=(15, 10))
ax = sns.heatmap(data.corr(), cmap = plt.cm.RdYlGn, annot=True, fmt=".2f")
###首行和末行是显示不全
a, b = ax.get_ylim()
ax.set_ylim(a + 0.5, b - 0.5)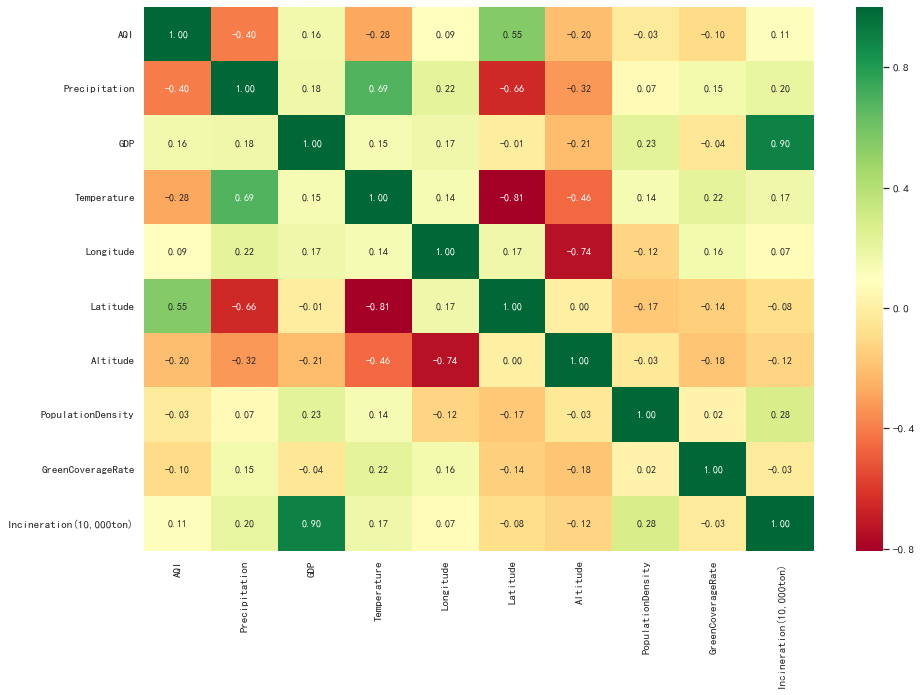
4.5 空气质量的验证
###关于空气质量的验证
data["AQI"].mean()
####单样本t检验,置信度为95%
r = stats.ttest_1samp(data["AQI"], 71)
print(r.statistic)
print(r.pvalue)![]()
mean = data["AQI"].mean()
std = data["AQI"].std()
stats.t.interval(0.95, df = len(data) - 1, loc = mean, scale = std / np.sqrt(len(data)))![]()
4.6 空气质量进行预测
####对空气质量进行预测
##数据的转换,类别变量转换离散变量
data["Coastal"] = data["Coastal"].map({"是":1, "否": 0})
data["Coastal"].value_counts()
##基模型
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
x = data.drop(["City", "AQI"], axis = 1)
y = data["AQI"]
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size= 0.3, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))![]()
y_hat = lr.predict(X_test)
plt.figure(figsize=(15,10))
plt.plot(y_test.values, "-r", label = "真实值", marker = "o")
plt.plot(y_hat, "-g", label="预测值", marker="D")
plt.title("线性回归预测结果", fontsize=20)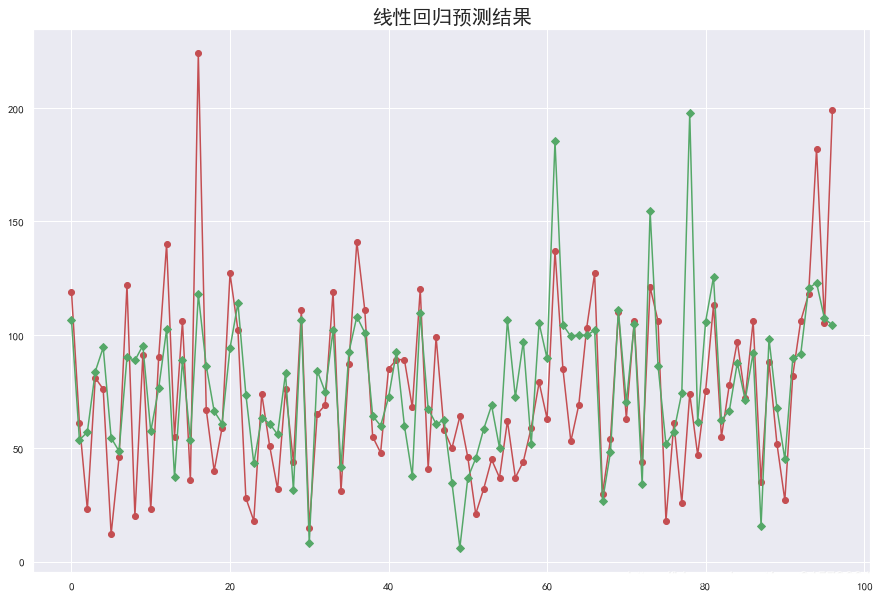
###异常值的处理
##使用临界值进行替换
for col in x.columns.drop("Coastal"):
if pd.api.types.is_numeric_dtype(X_train[col]):
quartile = np.quantile(X_train[col], [0.25, 0.75])
IQR = quartile[1] - quartile[0]
lower = quartile[0] - 1.5 * IQR
upper = quartile[1] + 1.5 * IQR
X_train[col][X_train[col] < lower] = lower
X_train[col][X_train[col] > upper] = upper
X_test[col][X_test[col] < lower] = lower
X_test[col][X_test[col] > upper] = upperlr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))![]()
特征选择
from sklearn.feature_selection import RFECV
rfecv = RFECV(estimator=lr, step=1, cv =5, n_jobs=-1, scoring="r2")
rfecv.fit(X_train, y_train)
print(rfecv.n_features_)
print(rfecv.ranking_)
print(rfecv.support_)
print(rfecv.grid_scores_)
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, marker="o")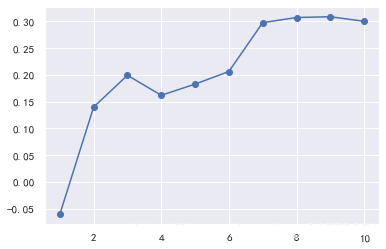
print("剔除的变量", X_train.columns[~rfecv.support_])
X_train_eli = X_train[X_train.columns[rfecv.support_]]
X_test_eli = X_test[X_test.columns[rfecv.support_]]
print(rfecv.estimator_.score(X_train_eli, y_train))
print(rfecv.estimator_.score(X_test_eli, y_test))###分箱操作
##我们不能将每个区间映射为离散数组,而是使用One-Hot编码
from sklearn.preprocessing import KBinsDiscretizer
###KBinsDiscretizer K个分箱的离散化,用于将数值(通常是连续变量)变量进行区间离散化操作
##n_bins 分箱(区间)的个数
##encode 离散化编码方式
#onehot s使用独热编码,返回稀疏矩阵
#onehot-dense 使用独热编码,返回稠密矩阵
#ordinal 使用序数编码
##strategy 分箱的方式, 分为
#uniform 每个区间的长度范围大致相同
#quantile 每个区间包含的元素个数大致相同
#kmeans 使用一维kmeans方式进行分箱
k = KBinsDiscretizer(n_bins=[4,5,14, 6], encode="onehot-dense", strategy="uniform")
###定义离散化的特征
discretize = ['Precipitation', 'Temperature', 'Longitude','Latitude']
r = k.fit_transform(X_train_eli[discretize])
r = pd.DataFrame(r, index = X_train_eli.index)
###获取除离散特征之外的其他特诊
X_train_dis = X_train_eli.drop(discretize, axis = 1)
X_train_dis = pd.concat([X_train_dis, r], axis = 1)
r = pd.DataFrame(k.transform(X_test_eli[discretize]), index = X_test_eli.index)
X_test_dis = X_test_eli.drop(discretize, axis = 1)
X_test_dis = pd.concat([X_test_dis, r], axis = 1)
lr.fit(X_train_dis, y_train)
print(lr.score(X_train_dis, y_train))
print(lr.score(X_test_dis, y_test))