(程序代码见后)
背景:
随着全球气候的变暖,空气质量每天发生变化,而人们的生活质量和空气质量息息相关。如下表1所示,空气质量和空气的成分有很大的关系,为此文中选择某城市一年内的空气指数数据进行分析。

注:数据源自中国气象网
- 数据基本描述
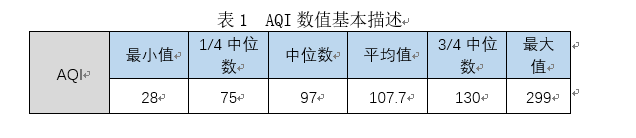
对数据进行基本统计,得到时序数值共365个,AQI的基本数值情况如下表1所示,
通过查询空气质量指数得到AQI空气质量指数取值范围及其相应内别,如下表2所示:

注:数据源自中国气象网
由表1中最大AQI数值为299,得知空气质量最大为重度污染。中位数值为97,属于空气质量良好,平均空气质量为107,属于轻度污染,故初步看该城市空气质量效果较好。而不同时间段下的空气质量也可能不同,为此根据中国的季度时间划分:春季,为3,4,5月;夏季,为6,7,8月;秋季,为9,10,11月;冬季,为12,1,2月。对时间数据进行划分,得到不同季节的空气质量变化如下图所示:

从箱线图可以看出,AQI指数在200以上的主要集中在冬季和春季,整体空气质量指数值集中在200以下,极个别异常AQI数值超出200以上,初步可说明该城市的空气质量整体情况较好。为进一步探究对空气质量指数和时间的变化,故建立时间序列ARMA模型。
- ARMA模型
2.1 ARMA模型概述
ARMA模 全称为自回归移动平均模型(Auto-regressive Moving Average Model,简称 ARMA)是研究时间序列的重要方法。其在时序数据分析过程中既考虑了数据在时间序列上的依存性, 又考虑了随机波动的干扰性, 对对应时序的发生变量运行短期趋势的预测准确率较高, 是近年应用比较广泛的方法之一。ARMA模型是由美国统计学家G.E.P.Box 和 G.M.Jenkins在20世纪70年代提出的著名时序分析模型,即自回归移动平均模型。ARMA模型有自回归模型AR(q)、移动平均模型MR(q)、自回归移动平均模型ARMA(p,q) 3种基本类型。其中ARMA(p,q)自回归移动平均模型,模型可表示为:
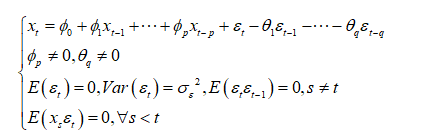
其中, 为自回归模型的阶数, 为移动平均模型的介数; 表示时间序列 在时刻 的值; 为自回归系数; 表示移动平均系数; 表示时间序列 在 时期的误差或偏差。
2.2 ARMA模型建模流程
首先用ARMA模型预测要求序列必须是平稳的,也就是说,在研究的时间范围内研究对象受到的影响因素必须基本相同。若所给的序列并非稳定序列,则必须对所给的序列做预处理,使其平稳化,然后用ARMA模型建模。建模的基本步骤如下:
(1)求出该观察值序列的样本自相关系数(ACF)和样本偏相关(PACF)的值。
(2)根据样本自相关系数和偏自相关系数的性质选择适当的 模型进行拟合。
(3)估计模型中未知参数的值。
(4)检验模型的有效性。如果拟合模型通不过检验,转向步骤(2),重新选择模型再拟合。
(5)模型优化。如果拟合模型通过检验,仍然转向步骤(2),充分考虑各种可能,建立多个拟合模型,从所有通过检验的拟合模型中选择最优模型。
(6)利用拟合模型,预测序列的将来走势。
3.AQI时间序列模型的建立
3.1 数据的预处理
本文选取了1年AQI数据作为时间序列观察值。对此时间序列做时序图如图1所示:

图1 AQI时序图
在发现经AQI数据的序列具有波动性,而我们的目的主要是利用ARMA 模型对其周期成分进行分析, 因此需要对此类的数据先进行消除趋势性的处理, 然后
从图(1)可以观察得出,序列大致趋于平稳。
为了进一步检验序列是否真正平稳,在此使用R语言统计软件对已转换进行平稳性检验。对时间序列的平稳性有两种检验方法,一种是根据时序图和自相关图显示的特征作出判断的图检验方法;一种是构造检验统计量进行假设检验的方法。目前最常用的平稳性统计检验方法是单位根检验(unit root test)。使用单位根检验法对变换数据进行检验得出检验结果如表1所示:
由时间序列的时序图可以发现AQI随时间的增长是呈上下波动趋势。因此,对原始序列不需作对数变换和差分,直接对数据进行检验即可。并作出单位根检验如下表1所示:
表1 AQI数据单位根检验

3.2 模型的识别与选择
计算出样本自相关系数和偏相关系数的值之后,我们主要是根据它们表现出来的性质,选择适当的ARMA模型拟合观察值序列。这个过程实际上就是要根据样本自相关系数和偏相关系数的性质估计自相关阶数 和移动平均阶数 ,因此模型的识别过程也成为定阶过程。一般ARMA模型定阶的基本原则如表2示:
表2 ARMA(p,q)模型选择原则
ACF PACF 模型定阶
拖尾 p阶截尾 AR§模型
q阶截尾 拖尾 MA(q)模型
拖尾 拖尾 ARMA(p,q)模型
对AQI数据进行分析,可得样本自相关系数和偏相关系数图如图2所示:

图2 序列自相关系数与偏相关系数图
由上图可以看出AQI序列拖尾不明显,为此分别对时序值数据进行一阶差分和取对数观察数据的正态性检验如下图所示:

通过对AQI序列进行处理后,发现对AQI数值进行取对数后,数据趋势刻画成一条直线较为明显。故AR模型的数据可选择对AQI数据取对数后建立自回归模型。

模型序号 对应模型 no-zero mean
1 ARIMA(2,0,2) 226.0505
2 ARIMA(0,0,0) 291.4564
3 ARIMA(1,0,0) 282.7597
4 ARIMA(0,0,1) 270.972
6 ARIMA(1,0,2) 225.5003
自相关系数和偏相关系数图的分析观察,可以知道模型大致可选取两种模型。第一种,自相关系数为拖尾,而偏相关系数为一阶截尾。此时选取模型可以为ARIMA(1,0,0)模型。第二种,自相关二阶截尾,而偏相关系数为一阶截尾。此时选取模型可以为ARIMA(1,0,2)模型。
3.3 参数估计
选择拟合好后的模型之后,下一步就是要利用序列的观察值确定该模型的口径,即估计模型中未知参数的值。对于一个非中心化ARMA(p,q)模型,有
式中,~
该模型共含 个未知参数: 。对于未知参数的估计方法有三种:矩估计﹑极大似然估计和最小二乘估计。其中使用最小二乘估计法对序列进行参数估计。
在ARMA(p,q)模型场合,记
残差项为:~
残差平方和为:~
是残差平方和达到最小的那组参数值即为 的最小估计值。
使用程序操作可得序列参数估计最佳值如下:
AIC=214.87 AICc=214.98 BIC=230.46
3.4 参数的显著性检验
参数的显著性检验就是要检验每一个未知参数是否显著非零。这个检验的目的是为了是使模型最精简。如果某个参数不显著,即表示该参数所对应的那个自变量对因变量的影响不明显,该自变量就可以从拟合模型中删除。最终模型将由一系列参数显著非零的自变量表示。由模型参数估计与检验结果,可以观察到t统计量值的 值均小于0.05。表明模型参数显著。
4.结 论
时间序列分析的ARMA 模型预测问题, 实质上是通过对时间变化过程的分析研究, 找出其发展变化的量变规律性, 用以预测未来的空气质量。预测时不必考虑其他因素的影响, 仅从序列自身出发, 建立相应的模型进行预测, 这就从根本上避免了寻找主要因素及识别主要因素和次要因素的困难; 和回归分析相比, 可以避免了寻找因果模型中对随机扰动项的限定条件在经济实践中难以满足的矛盾。实际上这也是ARMA 模型预测与其他预测方法相比的优越性所在。但由于空气质量受到人为、工业等不确定性因素影响,仅只能通过部分数据进行分析,分析具有一定的局限性。本文运用时间序列的分析方法,对空气质量进行分析。将ARIMA(1,0,0)模型对该序列进行拟合,最终得出空气质量的变化规律,总体而言空气质量较好。
代码操作
数据加载与准备
install.packages("tseries")
install.packages("forecast")
install.packages("decompose")
library(tseries)
library(forecast)
data <- read.csv("time.csv")
str(data)
描述统计分析
summary(data$AQI)# 查看数据趋势
boxplot(AQI~season, data, col=c(1,2,3,4), border=c("darkgray","purple"), ylab="AQI指数")
tsdisplay(data$AQI) # 得到acf和pacf
r <- diff(log(data$AQI))# 取对数后差分
tsdisplay(r)
正态性检验
par(mfrow = c(2,2))
qqnorm(data$AQI, ylab = "原始AQI数值")
qqnorm(r, ylab = "取对数后的AQI数值")
qqnorm(data_d1, ylab = "一阶差分AQI数值")
acf/pacf检验和单位根检验
Box.test(data$AQI, lag = 52, type = "Ljung-Box") # 数据白噪声检验,通过Box-Ljung 检验,则说明时间序列模型可以用来对数据进行预测
par(mfrow = c(2,1))
acf(data$AQI)
acf(r)
pacf(data$AQI)
pacf(r)
adf.test(data$AQI) # 原始数据单位根检验
adf.test(r) # 对数后的数据单位根检验
p = 0.01 < 0.05,故拒绝原假设,数据是平稳的
模型检验和测试
ar(r, aic = F, order = 1) #1阶自回归模型
auto.arima(r, trace = T)# 寻找最佳模型
fit <- ar(r)#寻找最佳自回归模型
print(fit)
好了,其实上述的也并没有进行更多深入挖掘和分析,比如在不同的季节下建立分段模型等,个人看来此篇仍然有很多不足,后续将持续改进时间序列,在周期、趋势、季节、干扰因素等的考虑。