一、什么是时间序列分析?
在工作中,常常要对数据进行预测,确定业务未来的发展趋势,进而配置相关的营销策略、制定业务目标,由此引申出了一个重要的用数据预测未来的方法——时间序列分析,今天和大家分享就是实战中难度系数比较高的时间序列分析,一种根据一段时间内数据的趋势,进行预测的模型方法,实际中主要用于对销售数据、金融数据的预测。
一般来说,要对数据进行预测,需要分析时间段内数据的影响因素是哪种,这里的影响因素从科学角度来讲有四种(因为我没对时间序列分析进行过进一步的理论研究,所以和大家分享时就根据我大学专业课所学以及日常工作中的思考来讲解,欢迎批评指正):
一、长期趋势(Trend)
二、季节变化(Season)
三、循环波动(Cyclic)
四、不规则波动(Irregular)
四种影响因素通常有两种组合方式,一种是加法模型:Y=T+S+C+I,认为数据的发展趋势是4种影响因素相互叠加的结果
一种是乘法模型:Y=T*S*C*I,认为数据的发展趋势是4种因素相互综合的结果
二、如何去预测数据?
拿到一组数据,要对一组数据进行预测,通常需要如下的步骤:
1.对数据进行清洗,去掉缺失值和异常值;
2.观察数据的时序图,确定数据是否存在周期性;
3.确定数据模型(指数平滑法还是自回归移动平均);
4.对模型效果进行比对,选择最优模型;
5.对模型的预测值根据实际业务再次进行优化,得到最终结果,应用到业务当中去。
三、该用哪个预测模型?
这里我介绍两个常用的预测模型,一个是指数平滑法,一个是自回归移动平均模型。
指数平滑法的基本公式是: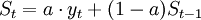 ,其中
,其中
- St--第t期的预测值(或指数平滑值);
- yt--第t期的实际值;
- St − 1--第t-1期的预测值(或指数平滑值);
- a--平滑常数,其取值范围为[0,1];
简单来说就是:任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均,也可以理解为下一期数据的预测值与本期的实际值和上一期的预测值相关.
指数平滑模型包括一次指数平滑、二次指数平滑、三次指数平滑,究竟使用哪个方法要根据实际情况:
一次指数平滑:当时间序列无明显的趋势变化,可用一次指数平滑预测。其预测公式为:
yt+1'=ayt+(1-a)yt' 式中,
- yt+1'--t+1期的预测值,即本期(t期)的平滑值St ;
- yt--t期的实际值;
- yt'--t期的预测值,即上期的平滑值St-1;
即下一期的预测值等于本期的实际值与本期的预测值的加权平均
二次指数平滑:对一次指数平滑的再平滑,它适用于具线性趋势的时间序列。其预测公式为:
yt+m=(2+am/(1-a))yt'-(1+am/(1-a))yt=(2yt'-yt)+(yt'-yt) a/(1-a)m
式中,yt= ayt-1'+(1-a)yt-1
二次指数平滑是一直线方程,其截距为:(2yt'-yt),斜率为:(yt'-yt) a/(1-a),自变量为预测天数。
三次指数平滑:在二次平滑基础上的再平滑。其预测公式为:
yt+m=(3yt'-3yt+yt)+[(6-5a)yt'-(10-8a)yt+(4-3a)yt]*am/2(1-a)2+ (yt'-2yt+yt')*a2m2/2(1-a)2
式中,yt=ayt-1+(1-a)yt-1
它们的基本思想都是:预测值是以前观测值的加权和,且对不同的数据给予不同的权,新数据给较大的权,旧数据给较小的权
四、如何使用指数平滑法建模
了解指数平滑法的理论知识后,接下来了解如何实际操作,得出预测结果,指数平滑法我个人觉得直接用spss就可以很好解决,
根据我在实践中的总结,当数据具有明显的季节性规律的时候,并且数据量不大,比如100个月的销售数据,我认为指数平滑法
能够很好解决销售预测的问题。举个例子:
数据我用的是张文彤老师《spss统计分析基础教程》中的汽车销量数据,如下所示:
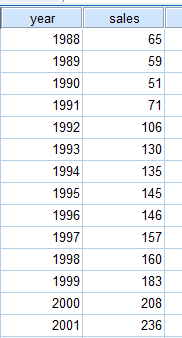
这里是1988年到2001年14年间的数据,如果我们要预测未来5年,也就是2002年到2006年的汽车销量,应该如何去做?
首先第一步:定义日期


设定初始年份为1988,因为这里数据只涉及到年,因此只选择年,如果数据涉及月数据,那么应该选择年份、季度、月份
第二步:描绘序列图,观察数据的长期趋势,


随着时间的增加,汽车销量呈现增长的趋势,并且1999年—2001的增长幅度超过了前面几年,呈现线性增长趋势
第三步:创建模型
选择预测——创建模型——指数平滑法


指数平滑条件可以看到,因为数据没有季节性,所以只支持在非季节性条件中选择,这里我们四种模型都选择一遍,从中选择最优的模型
在选项中,指定数据预测到2006年,保存预测值





上图从左到右分别是:简单非线性指数平滑模型、holt线性趋势指数平滑模型、Brown线性趋势指数平滑模型以及阻尼趋势指数平滑模型,直观上看,简单非线性模型被淘汰!因为已经明确知道未来趋势是线性,现在要确定剩下三个模型用哪个,
第四步:确定模型



从剩下三个模型的拟合结果来看,阻尼趋势模型的R方(即拟合优度)=0.951,最高,其次是holt线性和brown线性,均为0.948,
拟合结果差距不大,接下来进一步看三个模型的具体预测值:

未来5年,3个模型预测值如上,holt线性和brown线性的预测结果完全一致,阻尼趋势的结果较为保守,这时候应该根据公司的实际发展规划确定使用哪个结果,公司处于快速发展期,可以考虑线性模型的结果;公司处于稳定增长期,可以考虑阻尼趋势的结果,不去选择过高的销售目标,同时,结合当地社会平均消费水平以及全国的汽车市场发展前景等等因素,综合得出结果,不必局限于直接使用模型给出的数据,可以根据实际调整增长幅度,这样才能得出真正为业务所用的预测值。
这里举出的实例属于指数平滑法中最简单的一种,数据量小,考虑因素单一,因此能直观得出结果,实际业务中,还要涉及每个月的具体值,每年的重大节假日,双11,6.18等等,需要综合考虑的因素更多,这时,直接套用模型给出的结果远远不行,必须根据实际情况进行调整。
对于预测值超过100个,用指数平滑法就无法满足需求,这时候就用到了自回归移动平均模型(ARIMA模型),限于篇幅,我将放到下一次的分享,自回归移动平均模型是时间序列预测的精华之所在,非常值得思考和探索,敬请期待。