线性回归法(Linear Regression)
特点:
● 解决回归问题
● 思想简单,实现容易
● 许多强大的非线性模型的基础
● 结果具有很好的可解释性
● 蕴含机器学习中的很多重要思想

在分类问题中,横纵轴都是特征。
在回归问题中,预测的是一个具体的数值,该数值是在一个连续的空间里的,所以要占有一个坐标轴的位置,如果想要看有两个样本特征的回归问题,就需要在三维空间中进行观察。
在线性回归问题中,我们要寻找一条直线,最大程度地拟合样本特征和样本输出标记之间的关系。
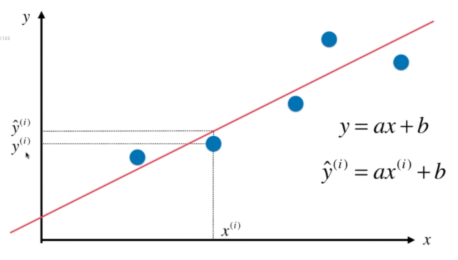
假设我们找到了最佳拟合的直线方程 y=ax+b
则对于每一个样本点 x ^(i),根据我们的直线方程,预测值为 y^ ^(i)=ax ^(i)+b,真值为 y ^(i)。
此时我们希望y的预测值和真值的差距尽量小,那么如何表达两者之间的差距呢?
y-y^ (会出现负数)
|y-y^| (不是处处可导)
最后选择 (y-y^)² 表达两者之间的差距。
考虑所有样本:
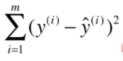
由于y^ ^(i)=ax ^(i)+b,所以误差可表示为:
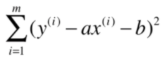
我们的目标是,找到a和b,使得上述误差尽可能小。
一类机器学习算法的基本思路:
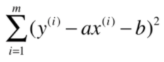
我们称之为损失函数(或代价函数)。
有一些是效用函数。
基本思路:
- 通过分析问题,确定问题的损失函数或者效用函数,让损失函数小,效用函数大。
- 通过最优化损失函数或者效用函数,获得机器学习的模型。
近乎所有参数学习算法都是这样的套路:
线性回归
SVM
最优化原理
多项式回归
神经网络
凸优化
逻辑回归
通过最小二乘法,我们得出a和b的值:
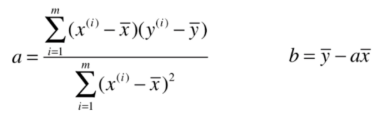
简单线性回归的实现:
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1, 2, 3, 4, 5])
y = np.array([1, 3, 2, 3, 5])
x_mean = np.mean(x) # 求均值
y_mean = np.mean(y)
num = 0.0 # 分子numerator
den = 0.0 # 分母denominator
for x_i, y_i in zip(x, y): # 用zip函数打包成元组
num += (x_i - x_mean) * (y_i - y_mean)
den += (x_i - x_mean) ** 2
a = num / den
b = y_mean - a * x_mean
y_hat = a * x + b
plt.scatter(x, y)
plt.plot(x, y_hat, color='r')
plt.axis([0, 6, 0, 6])
plt.show()
Output:

参考资料:bobo老师机器学习教程
