一、统计量
1.1 定义
设
是从总体
中抽取的容量为n的一个样本,如果由此样本构造一个函数
,不依赖与任何未知参数,则成函数
通常又称
,代入
,计算
1.2 常用统计量
根据上述可知,统计量是样本的一个函数,不同的推断问题要求构造不同的统计量。要注意的是,依赖于总体分布的未知参数不属于统计量,比如数学期望和方差
。
下列为常用的统计量:
- 样本均值:
,反映出总体
- 样本方差:
,反映的是总体
- 样本变异系数:
,反映出随机变量在以它的均值为单位时取值的离散程度。
- 样本k阶矩:
,反映出总体k阶矩的信息。显然,
,就是样本均值。
- 样本k阶中心矩:
,反映了总体k阶中心矩的信息。显然,
就是样本方差。 (数学期望和方差等概念可用“矩”的概念来描述)
二、统计三大分布
若对任一自然数n都能导出统计量的分布的数学表达式,这种分布成为精准的抽样分布。它对样本量n较小的统计推断问题非常有用。精准的抽样分布大多是在正态总体情况下得到的。在正态总条件下,主要有
分布、
分布、
分布,常称为统计三大分布。
2.1 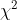 分布
分布
分布(Chi-squre distribution),就是卡方分布。定义如下:
设随机变量
服从标准正态分布
,则它们的平方和
服从自由度为
的
自由度是统计学中常用的一个概念,它可以解释为独立变量的个数,还可以解释为二次型的秩。例如,是自由度为1的
分布,
;
是自由度为
的
分布,
。
下图为当,
,
,
时,
分布的概率密度函数曲线:

分布的数学期望为:
;
分布的方差为:
;
分布具有可加性,即若
,
,且独立,则
。
由上图还可以看出,当自由度足够大时,分布的概率密度曲线趋于对称。当
时,
分布的极限分布时正态分布。
的
分位数
可由卡方分布表查得。当自由度
很大时,
近似服从
。实际上,当自由度
时,有
。式中,
即
,为正态
分位数,可由正态分布表查得。
卡方分布表:

2.2 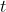 分布
分布
分布定义:
设随机变量
,
,且
独立,则
其分布称为
,其中
分布的概率函数是一偶函数,图形如下:

当时,
分布的数学期望
。当
时,
分布的方差
。
由图可以看出,分布的密度函数曲线与标准正态分布
的密度函数曲线非常相似,都是单峰偶函数,只是
的密度函数的两侧尾部要比
的两侧尾部粗一些。
的方差比
的方差大一些。
自由度为1的分布称为柯西分布,随着自由度的增加,
分布的密度函数越来越接近标准正态分布的密度函数。实际应用中,一般当
时,
分布与标准正态分布就非常接近了。
2.3 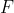 分布
分布
分布有着广泛的应用,在方差分析、回归方程的显著性检验中有着重要的地位。
分布的定义:
设随机变量
相互独立,且
和
则称
,简记为
。
分布的密度函数图如下图所示:

设随机变量服从
分布,则数学期望和方差分别为:
,
,
分布的
分位数
可查
分布表获得,且
由此可知,在分布中,两个自由度的位置不可互换。此外,这一性质在查
分布表时有重要应用。
分布与
分布还存在如下关系:
如果随机变量服从
分布,则
服从
的
分布。这在回归分析的回归系数显著性检验中有用。
三、中心极限定理
中心极限定理:
设从均值为
、方差为
(有限)的任意一个总体中抽取样本量为
的抽样分布近似服从均值为
的正态分布,即
,等价有
。
注意:的期望值与总体均值相同,而方差则缩为总体方差的
。这说明当用样本均值
去估计总体均值
时,平均来说没有偏差(这一点称为无偏性);当
越来越大时,
的散布程度越来越小,即用
估计
就越来越准确。
该定理告诉我们,不管总体的分布是什么,此时样本均值的分布总是近似正态分布,只要总体的方差
有限。
如上的定理要求必须充分大,那么多大才叫充分大?这与总体分布形状有关,总体偏离正态越远,则要求
越大。然而在实际应用中,总体的分布未知。此时,我们常要求
。
例子:

