一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取微博热搜Top25的数据
2.爬取微博热搜Top25的内容及其热度
3.主题式网络爬虫设计方案概述
先分析网页源代码,设置url地址,利用requests库和lxml来获取网页代码,由此来爬取微博热搜数据并采集;然后对数据进行清洗和处理并可视化
技术难点:在编程的过程中,若中间部分出现错误,可能导致整个代码需要重新修改。数据实时更新导致部分上传的图形不一致。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析

这为本次要爬取的微博Top25
2.Htmls页面解析
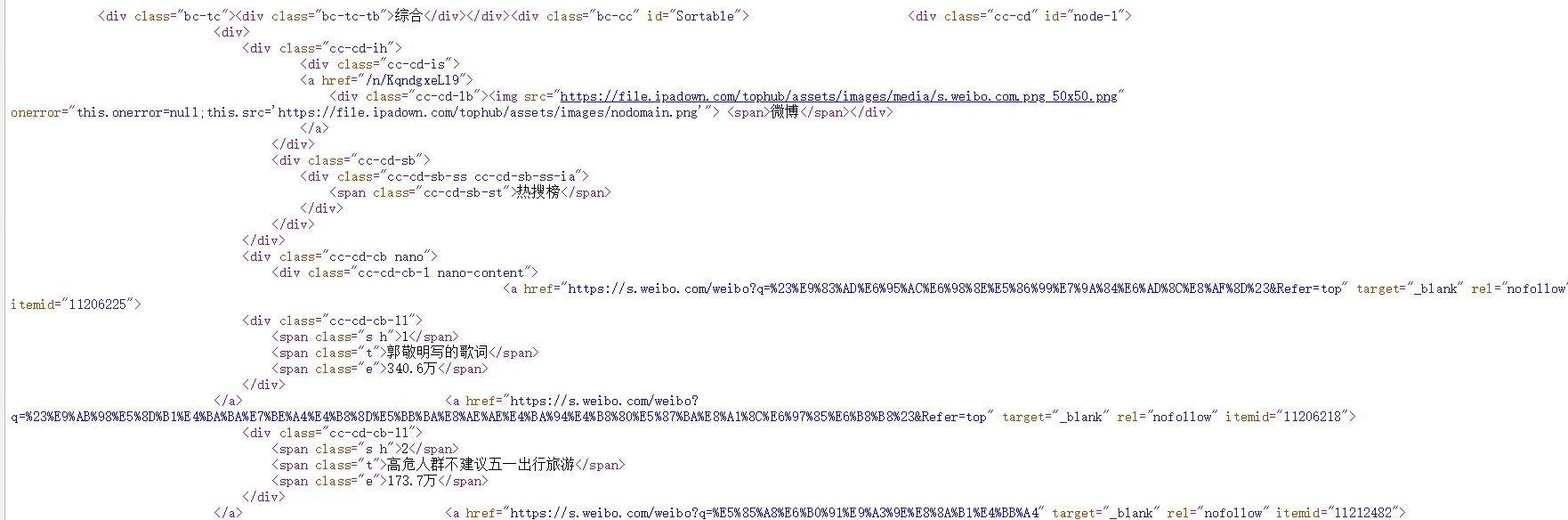
右键查看源代码,从网页代码中可以获取到信息
(1)数据都分布在标签'<div class="cc-cd-cb-ll">里面
(2)热搜的名字都在<span class="t">的子节点<span>里
(3)热搜的排名都在<span class="s h">里
(4)热搜的访问量都在<span class="e">的子节点<span>里
3.节点(标签)查找方法与遍历方法
通过xpath遍历标签,利用xpath正则表达查找。
三、网络爬虫程序设计
1.数据爬取与采集
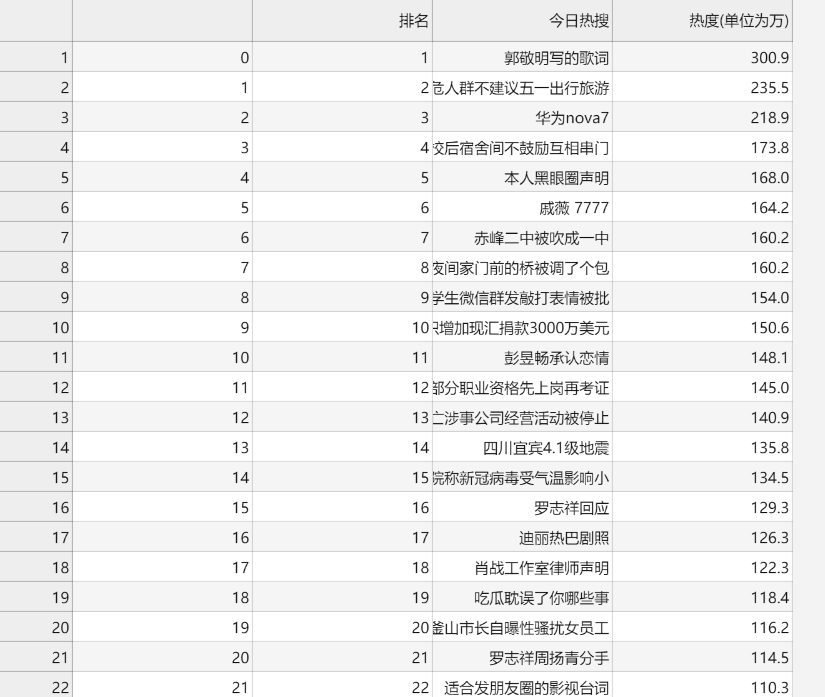
import requests from lxml import etree import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq import scipy.stats as sts import seaborn as sns url = "https://tophub.today/" headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} html = requests.get(url,headers = headers) html = html.content.decode('utf-8') html = etree.HTML(html) div = html.xpath("//div[@id='node-1']/div") for a in div: titles = a.xpath(".//span[@class='t']/text()") numbers = a.xpath(".//span[@class='e']/text()") b = [] for i in range(25): b.append([i+1,titles[i],numbers[i][:-1]]) file = pd.DataFrame(b,columns = ['排名','今日热搜','热度(单位为万)']) print(file) file.to_csv('微博热搜榜热度数据.csv')

提取微博热搜top25
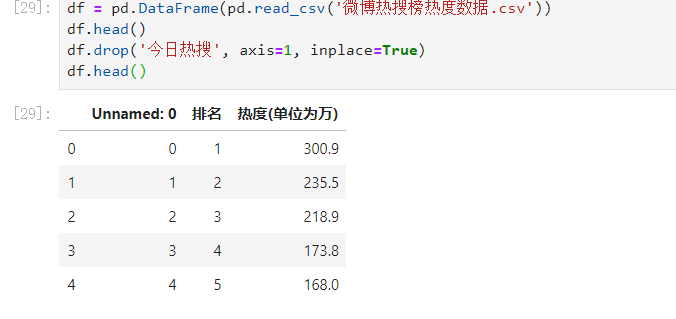
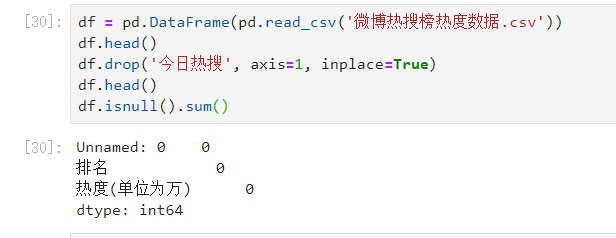
2.对数据进行清洗和处理
df = pd.DataFrame(pd.read_csv('微博热搜榜热度数据.csv'))
df.head()

df.drop('今日热搜', axis=1, inplace=True)
df.head()

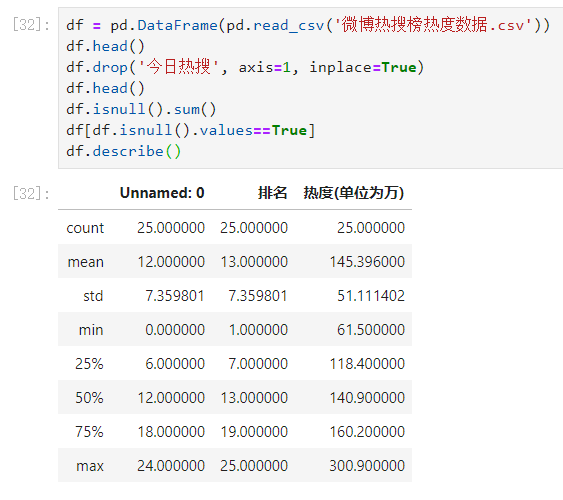
3.数据分析与可视化。
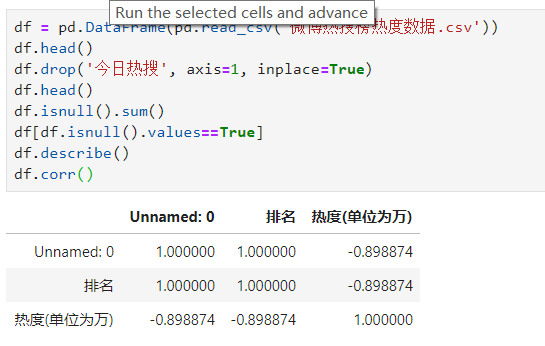
sns.lmplot(x='排名',y='热度(单位为万)',data=df)

def one(): file_path = "'微博热搜榜热度数据.csv'" x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.bar(x,y) plt.title("绘制排名与热度条形图") plt.show() one()

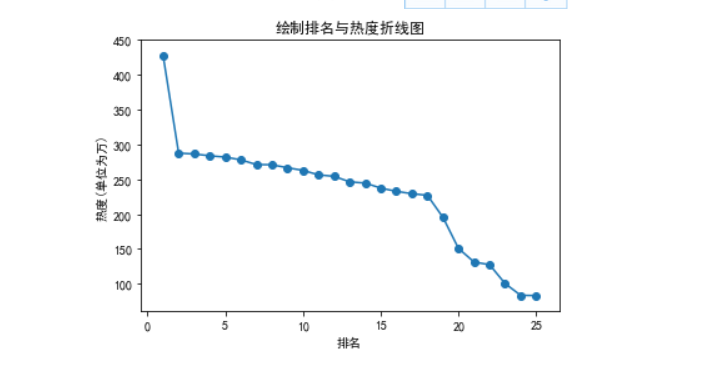
def two(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.plot(x,y) plt.scatter(x,y) plt.title("绘制排名与热度折线图") plt.show() two()
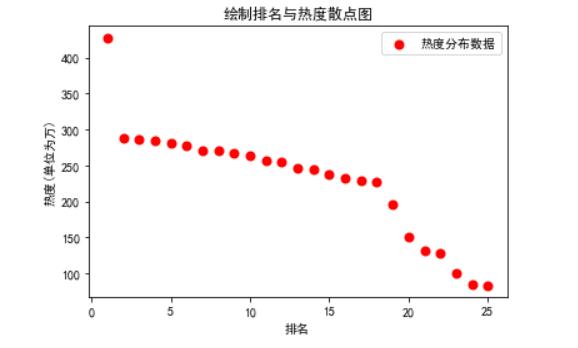
def three(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2) plt.title("绘制排名与热度散点图") plt.legend() plt.show() three()
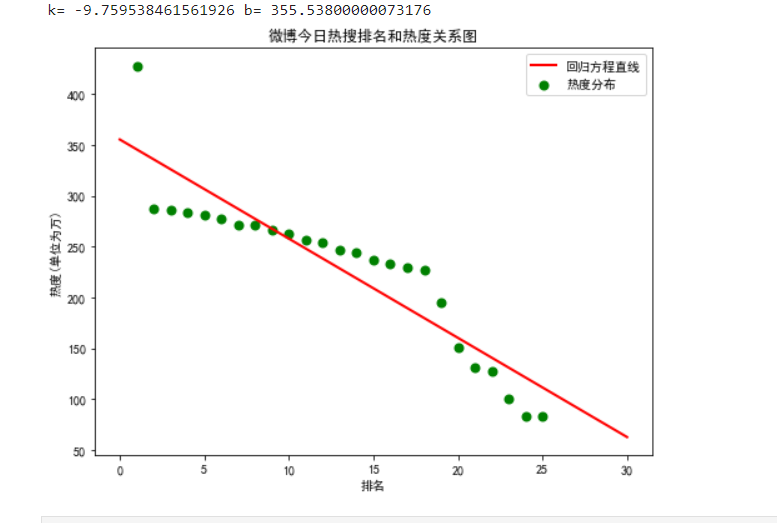
4.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程
一元一次回归方程:
def main(): colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' f = pd.read_csv('微博热搜榜热度数据.csv',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): k,b = p return k*x+b def error_func(p,x,y): return func(p,x)-y p0 = [1,20] Para = leastsq(error_func,p0,args = (X,Y)) k,b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(8,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() main()
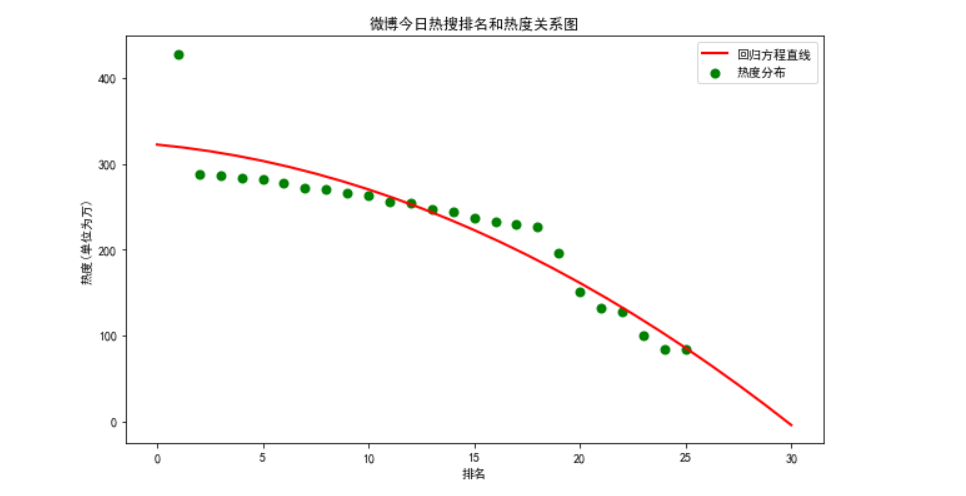
一元二次方程
def four(): colnames = ["排名","今日热搜","number"] #由于运行存在问题,用number表示'热度(单位为万)' f = pd.read_csv('微博热搜榜热度数据.csv',engine='python',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return func(p,x)-y p0=[0,0,0] Para=leastsq(error_func,p0,args=(X,Y)) a,b,c=Para[0] plt.figure(figsize=(10,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=a*x*x+b*x+c plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() four()
5.完整代码
import requests from lxml import etree import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq import scipy.stats as sts import seaborn as sns url = "https://tophub.today/" headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'} html = requests.get(url,headers = headers) html = html.content.decode('utf-8') html = etree.HTML(html) div = html.xpath("//div[@id='node-1']/div") for a in div: titles = a.xpath(".//span[@class='t']/text()") numbers = a.xpath(".//span[@class='e']/text()") b = [] for i in range(25): b.append([i+1,titles[i],numbers[i][:-1]]) file = pd.DataFrame(b,columns = ['排名','今日热搜','热度(单位为万)']) print(file) file.to_csv('微博热搜榜热度数据.csv') df = pd.DataFrame(pd.read_csv('微博热搜榜热度数据.csv')) df.head() df.drop('今日热搜', axis=1, inplace=True) df.head() df.isnull().sum() df[df.isnull().values==True] df.describe() df.corr() #用来正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示负号 plt.rcParams['axes.unicode_minus'] = False sns.lmplot(x='排名',y='热度(单位为万)',data=df) #绘制排名与热度条形图 def one(): file_path = "'微博热搜榜热度数据.csv'" x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.bar(x,y) plt.title("绘制排名与热度条形图") plt.show() one() #绘制排名与热度折线图 def two(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.plot(x,y) plt.scatter(x,y) plt.title("绘制排名与热度折线图") plt.show() two() #绘制排名与热度散点图 def three(): x = df['排名'] y = df['热度(单位为万)'] plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2) plt.title("绘制排名与热度散点图") plt.legend() plt.show() three() #一元一次回归方程 def main(): colnames = ["排名","今日热搜","number"] f = pd.read_csv('微博热搜榜热度数据.csv',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): k,b = p return k*x+b def error_func(p,x,y): return func(p,x)-y p0 = [1,20] Para = leastsq(error_func,p0,args = (X,Y)) k,b = Para[0] print("k=",k,"b=",b) plt.figure(figsize=(8,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() main() #一元二次回归方程 def four(): colnames = ["排名","今日热搜","number"] f = pd.read_csv('微博热搜榜热度数据.csv',engine='python',skiprows=1,names=colnames) X = f.排名 Y = f.number def func(p,x): a,b,c=p return a*x*x+b*x+c def error_func(p,x,y): return func(p,x)-y p0=[0,0,0] Para=leastsq(error_func,p0,args=(X,Y)) a,b,c=Para[0] plt.figure(figsize=(10,6)) plt.scatter(X,Y,color="green",label=u"热度分布",linewidth=2) x=np.linspace(0,30,25) y=a*x*x+b*x+c plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("微博今日热搜排名和热度关系图") plt.xlabel('排名') plt.ylabel('热度(单位为万)') plt.legend() plt.show() four()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
利用爬虫进行数据收集能大大提高工作效率,利用方程图能更加直观且迅速清晰的看到热搜数据的变化,简单明了。
2.对本次程序设计任务完成的情况做一个简单的小结。
还是不能熟练的掌握python语言,由于本次作业费时过久,热搜数据实时更新导致前面的截图与后面的截图数据上有浮动,希望继续跟老师学习,能学到并掌握更多的知识。