SVM分类器与Softmax分类器的区别
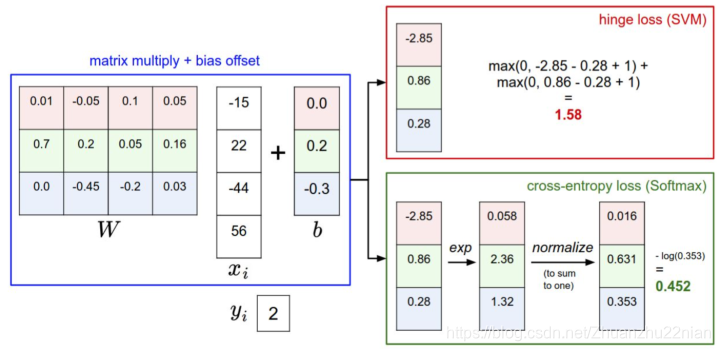
这是针对一个数据,SVM与Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f。不同之处在于对f中分值的解释:SVM分类器将它们看作是分类评分,它的损失函数鼓励正确的分类(即图中的蓝色类别2)的分值比其它分类的分值高出至少一个边界值。Softmax分类器将这些数值看作是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终损失值是1.58,Softmax的最终损失值是0.452,但要注意这两个数值没有可比性。只有在给定同样的数据,在同样的分类器的损失值计算中,它们才有意义。
精确地说,SVM分类器使用的是折叶损失(hinge loss),有时候又被称为最大边界损失(max-margin loss)。Softmax分类器使用的是交叉熵损失(corss-entropy loss)。
SVM:

Softmax:
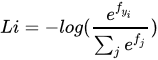
Softmax分类器为每个分类提供了“可能性”,可能性分布的集中和离散程度是由正则化参数λ直接决定的,这是一个超参数,可以直接控制。如果正则化参数λ更大,那么权重W就会被惩罚的更多,然后他的权重数值就会更小,这样算出来的分数也会更小。


这样看来,概率的分布就更加分散了。随着正则化参数λ不断增强,权重数值会越来越小,最后输出的概率会更加接近于均匀分布。这就是说,softmax分类器算出来的概率最好是看成一种对于分类正确性的自信。和SVM一样,数字间相互比较得出的大小顺序是可以解释的,但其绝对值则难以直观解释。
在实际使用中,SVM和Softmax经常是相似的,通常说来,两种分类器的表现差别很小,不同的人对于哪个分类器更好有不同的看法。相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM()会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
