1. 必备知识
关联规则
关联规则是形如 x->y 的蕴涵表达式,x,y是不相交的项集,即X∩Y=∅
项集
保含0个或者多个项的集合叫项集 数量是k 就叫k项集
例:{鸡蛋, 水果,蛋糕} 是一个3项集 空集同理
关联规则的强度
一般用 支持度 support 和 可信度 confidence 来 度量
支持度
| 交易单 | 商品 |
|---|---|
| 0 | 鸡蛋 牛奶 可乐 尿布 |
| 1 | 啤酒 鸡蛋 可乐 |
| 2 | 牛奶 鸡蛋 |
在上述列表中
鸡蛋的支持度为 3/3
牛奶为 2/3
尿布 1/3
可乐 2/3
(鸡蛋,尿布)为 0
(鸡蛋 可乐 ) 为 1/3
即一个项集的支持度 就是 他在所有项集中出现的频率
可信度(置信度)
可信度 和 数理统计中的 条件概率 类似
购买x中同时购买y的置信度为
confidence(x->y) = P(y/x) =P(x,y)/P(x) = 同时买x,y /买了 x
可乐->鸡蛋 的可信度为
同时买鸡蛋可乐 = 1/3 — (鸡蛋,可乐)的支持度
买可乐 2/3 — 可乐的支持度
结果就是 1/2 — 相除
同理 鸡蛋->可乐
为2/3
提升度(并没用到)
lift(x->y) = P(x,y)/(P(x)*P(y)= P(y/x)/P(y)
计算方法有很多种
提升度指 买 x对买y有没有提升作用,如果值大于1 则有用,1 无相关 ,小于1 负相关
可乐->鸡蛋 的提升度为
1/3 / (2/3 * 1) = 2 买可乐对买鸡蛋有提升作用
项目
交易数据库中的字段
即各种商品就是一个项目 鸡蛋是一个项目 牛奶是一个项目
事务
一次交易的所有项目集合
即一个人购物一次买的所有东西 {鸡蛋,牛奶}是一个事务 他代表路人甲一次购买的所有东西
频繁项集
所有支持度大于最小支持度的项集称为频繁项集,简称频集 (最小支持度由用户指定)
最大频繁项集是不被其他元素包含的频繁项目集
项目集的相关定理
定理( Apriori 属性1).
如果项目集X 是频繁项目集,那么它的所有非空子集都是频繁项目集
定理( Apriori 属性2).
如果项目集X 是非频繁项目集,那么它的所有超集都是非频繁项目集。
证明都很简单,也很容易理解,从定义理解即可。
关联规则挖掘问题
关联规则挖掘问题可以划分成两个子问题:
- 发现频繁项目集:通过用户给定Minsupport ,寻找所有频繁项目集或者最大频繁项目集。
- 生成关联规则:通过用户给定Minconfidence ,在频繁项目集中,寻找关联规则。
强关联规则
D在I上满足最小支持度和最小信任度(Minconfidence)的关联规则称为强关联规则(Strong Association Rule)。
即我们需要根据我们给出的最小支持度和最小可信度找到其中的规则
2.实例
1.寻找最大频繁项集
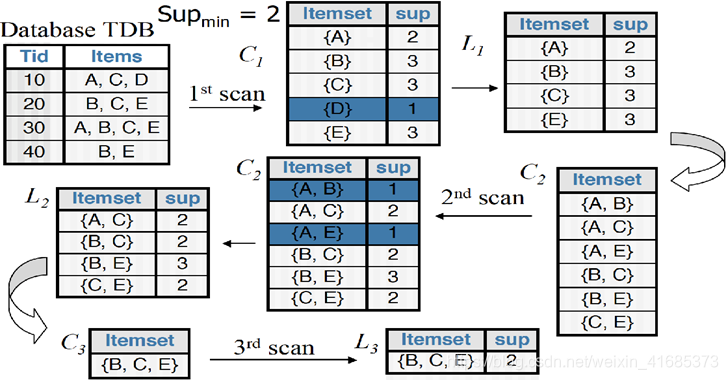
每一次扫描数据库, 从 1项集开始 ,淘汰不满足用户指定的最小支持度的项(这里是2)支持度为0.5 ,然后再两两结合生成i+1项集再淘汰直到最后唯一 , 这样我们就找到了最大频繁项集 {B, C,E }其他3项集都不满足最小支持度 ,这个图没标,在C3这里 还有{A,B,C},{ A,C,E},{A,B,E} 支持度只有1/4
2.生成强关联规则
若我们取最小可信度为80% 大于0.8 才可信
| 最大频繁项集(支持度) | 子集(支持度) | 可信度 | 规则 | 是否强关联 |
|---|---|---|---|---|
| B,C,E(50%) | B,C(50%) | 100% | BC->E | 是 |
| B,C,E(50%) | B,E(75%) | 67% | BE->C | 否 |
| B,C,E(50%) | C,E(50%) | 100% | CE->B | 是 |
| B,C,E(50%) | B(75%) | 67% | B->CE | 否 |
| B,C,E(50%) | C(75%) | 67% | C->BE | 否 |
| B,C,E(50%) | E(75%) | 67% | E->BC | 否 |
这样就找到了一个强关联规则 BC -> E 和 CE ->B
3.算法
python算法,写法也是抄别人的,我加了字典序的排序更加好看了
注释是自己写的
def load_data_set():
'''
给出数据库事务集
:return: data
'''
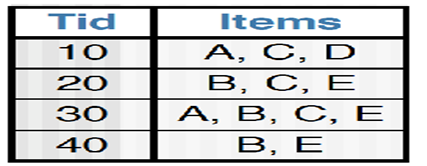
data_set = [
['A' ,'C' ,'D'],
['B' ,'C' ,'E'],
['A' ,'B' ,'C' ,'E'],
['B' ,'E']
]
data =[
['a','c','d','e','f'],
['b','c','f'],
['a','d','f'],
['a','c','d','e'],
['a','b','d','e','f']
]
return data_set
def Create_C1(data_set):
'''
生成候选1项集
'''
C1 = set()
for t in data_set: # 每一个事务
for item in t: #每一个商品
item_set = frozenset([item]) # { 'a' } 的形式,
# 用frozenset 是因为键值对的键要满足不可变 不然就破坏了键的唯一性和确定性
# 为生成频繁项目集时扫描数据库时以提供issubset()功能.
C1.add(item_set)
return C1 # 类似[ {'a'} ,{'b'}]
def is_apriori(Ck_item, Lk_sub_1):
'''
参数:候选频繁k项集,频繁k-1项集 原理是只要含有不频繁项集的项集就是不频繁的 用于剪枝
'''
for item in Ck_item: # 校验候选k项集中是否每一项的真子集是频繁k-1项集
sub_item = Ck_item - frozenset([item])
if sub_item not in Lk_sub_1:
return False
return True
def Create_Ck(Lk_sub_1, k):
'''
# 参数:频繁k-1项集,当前要生成的候选频繁几项集 切k>2
'''
Ck = set()
len_Lk_sub_1 = len(Lk_sub_1)
list_Lk_sub_1 = list(Lk_sub_1)
for i in range(0,len_Lk_sub_1): #遍历每一项 索引是i
for j in range(i + 1, len_Lk_sub_1): # 遍历接下来的每一项 索引是j 相当于两两组合 (自连接)
l1 = list(list_Lk_sub_1[i])
l2 = list(list_Lk_sub_1[j])
# 排序便于比较 顺序是字典序
l1.sort()
l2.sort()
# 判断l1的前k-1-1个元素与l2的前k-1-1个元素对应位是否全部相同
# 因为我们要产生的是 候选频繁k项集,所以对于频繁k-1项集 只需要k-2项相等,1项不相等连接才能产生
if l1[0:k - 2] == l2[0:k - 2]:
Ck_item = list_Lk_sub_1[i] | list_Lk_sub_1[j] # 求集合的并 相当于生成候选频繁k项集了
if is_apriori(Ck_item, Lk_sub_1): # 剪枝
Ck.add(Ck_item)
return Ck
def Generate_Lk_By_Ck(data_set, Ck, min_support, support_data):
'''
参数:数据库事务集,候选频繁k项集,最小支持度,项目集-支持度dic
'''
Lk = set()
# 通过dic记录候选频繁k项集的事务支持个数
item_count = {}
for t in data_set:
for Ck_item in Ck:
if Ck_item.issubset(t): # 候选频繁k项集中每一项 对事务集开始 统计支持度
if Ck_item not in item_count:
item_count[Ck_item] = 1
else:
item_count[Ck_item] += 1
data_num = float(len(data_set))
for item in item_count:
if (item_count[item] / data_num) >= min_support: # 满足最小支持度加入频繁k项集,把支持度也加入支持度字典中
Lk.add(item)
support_data[item] = item_count[item] / data_num
return Lk
def Generate_L(data_set, max_k, min_support): #求最大频繁项集 和所有的频繁项集
'''
参数:数据库事务集,求的最高项目集为k项,最小支持度
'''
# 创建一个频繁项目集为key,其支持度为value的dic
support_data = {}
C1 = Create_C1(data_set)
L1 = Generate_Lk_By_Ck(data_set, C1, min_support, support_data)
Lk_sub_1 = L1.copy() # 对L1进行浅copy
L = []
L.append(Lk_sub_1) # 末尾添加指定元素
for k in range(2, max_k + 1): # 结尾不包括 所以加1
Ck = Create_Ck(Lk_sub_1, k)
Lk = Generate_Lk_By_Ck(data_set, Ck, min_support, support_data)
Lk_sub_1 = Lk.copy()
L.append(Lk_sub_1)
return L, support_data
def Generate_Rule(L, support_data, min_confidence):
'''
参数:所有的频繁项目集,项目集-支持度dic,最小置信度
'''
rule_list = []
sub_set_list = []
for i in range(len(L)):
for frequent_set in L[i]: # 每一个频繁k项集
for sub_set in sub_set_list: # 每一个频繁k项的子集
if sub_set.issubset(frequent_set): #必须是频繁项集的子集
conf = support_data[frequent_set] / support_data[sub_set] #可信度
# 强关联规则格式为 子集 频繁项集 可信度
rule = (sub_set, frequent_set - sub_set, conf)
if conf >= min_confidence and rule not in rule_list: # 去重 并添加规则
rule_list.append(rule)
sub_set_list.append(frequent_set)
return rule_list
if __name__ == "__main__":
data_set = load_data_set()
'''
print("Test")
# 数据库事务打印
for t in data_set:
print(t)
'''
'''
print("Test")
# 候选频繁1项集打印
C1 = Create_C1(data_set)
for item in C1:
print(item)
'''
'''
# 频繁1项集打印
print("Test")
L = Generate_L(data_set, 1, 0.2)
for item in L:
print(item)
'''
'''
# 频繁k项集打印
print("Test")
L, support_data = Generate_L(data_set, 2, 0.2)
for item in L:
print(item)
'''
'''
# 关联规则测试
print("Test")
L, support_data = Generate_L(data_set, 3, 0.2)
rule_list = Generate_Rule(L, support_data, 0.7)
for item in support_data:
print(item, ": ", support_data[item])
print("-----------------------")
for item in rule_list:
print(item[0], "=>", item[1], "'s conf:", item[2])
'''
# 最大频繁项集的项数 k 最小支持度 最小可信度
maxK=3
minsupport=0.5
minconfidence=0.8
L, support_data = Generate_L(data_set, maxK, minsupport)
rule_list = Generate_Rule(L, support_data, minconfidence)
print()
print()
print("最小支持度:"+str(minsupport)+"\t最小置信度:"+str(minsupport)+"\t最大频繁项的项数:"+str(maxK))
for Lk in L:
print("=" * 40)
print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport")
#print("=" * 40)
for frequent_set in Lk:
s="{}\t\t\t{}"
a=list(frequent_set)
a.sort() # 排序字典序
print(s.format(a, support_data[frequent_set]))
print()
print("Rules\t\t\t\t最小置信度"+str(minsupport))
for item in rule_list:
a=list(item[0])
a.sort()
print(a, "=>", list(item[1]), "'s conf: ", item[2])
运行图如图

