1.现实需求:购物篮分析
超市经理想知道顾客的购物习惯,如顾客在一次购物时会同时购买哪些商品,也就是要发现不同商品之间的关联,典型案例是“尿布与啤酒”。
关联规则挖掘的目标是发现数据项集之间的关联关系或相关关系。
2.关联规则的基本概念
定义1:项与项集
项:数据库中不可分割的最小单位信息,用i表示,如商品中的尿布、啤酒等。
项集:项的集合,用下式表示
![]()
I中项目个数为k,则称集合I为k-项集,如商品组合{尿布,啤酒,牛奶}。
定义2:事务
设![]() 是所有项构成的集合,可以称为全项集,而I的子集对应一个事务,如顾客买了{尿布,啤酒},这个子项集对应一个事务。
是所有项构成的集合,可以称为全项集,而I的子集对应一个事务,如顾客买了{尿布,啤酒},这个子项集对应一个事务。
定义3:项集的频数
包含某项集的事务数量称为该项集的频数(支持度计数)。
定义4:关联规则
形如![]() 的表达式,X、Y是I的真子集,且满足X∩Y=∅ 。
的表达式,X、Y是I的真子集,且满足X∩Y=∅ 。
X为规则的前提,Y为规则的结果,表示X中出现的项出现时,Y中的项也跟着出现的规律。如顾客购买了尿布和啤酒,尿布⟹ 啤酒存在的关联规则。
定义5:关联规则的支持度

![]()
反映了X和Y中所含的项在事务集中同时出现的频率。
定义6:关联规则的置信度
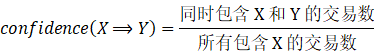
![]()
置信度反映包含X的事务中,出现Y的条件概率。
定义7:最小支持度与最小置信度
用户为了达到一定要求,关联规则需要满足指定的支持度和置信度阈值。
当![]() 、
、![]() 分别大于等于各自阈值时,认为关联规则
分别大于等于各自阈值时,认为关联规则![]() 是有趣的。
是有趣的。
这两个阈值称为最小支持度阈值(min_sup)、最小置信度阈值(min_conf)。
min_sup描述了关联规则的最低重要程度,min_conf规定了关联规则必须满足的最低可靠性。
定义8:频繁项集
项集![]() ,给定最小支持度min_sup,如果项集U的支持度
,给定最小支持度min_sup,如果项集U的支持度
![]()
称U为频繁项集,否则为非频繁项集。
定义9:强关联规则
![]()
![]()
称![]() 为强关联规则,否则为弱关联规则。
为强关联规则,否则为弱关联规则。
关联规则中最重要的参数是:支持度、置信度。
3.关联规则的挖掘过程
总的来讲,关联规则的挖掘过程分两步:
- 第一步,找出所有的频繁项集;
- 第二步,由频繁项集产生强关联规则。
实现过程结合具体实例来讲解。
下表为数据库事务列表D,在数据库中,有9笔商品交易(即9项事务),每个交易都用不同的标识符TID代表。
数据库事务列表D
| 交易(事务TID) |
商品ID的交易集合(项集) |
| T100 |
I1, I2, I5 |
| T200 |
I2, I4 |
| T300 |
I2, I3 |
| T400 |
I1, I2, I4 |
| T500 |
I1, I3 |
| T600 |
I2, I3 |
| T700 |
I1, I3 |
| T800 |
I1, I2, I3, I5 |
| T900 |
I1, I2, I3 |
仔细观察,会发现:
- 所有的项包括:I1, I2, I3, I4, I5;
- 交易集合中的项是按字典顺序存放的,这一点很重要,可以减少很多麻烦,提高算法的效率。
同时,我们假设最小支持度计数为2,即min_sup=2。
⑴第一次扫描数据集D(初始化扫描)
①得到所有项(1-项集)的支持度计数;
候选1-项集C1
| C1 |
|
| 项集 |
支持度计数 |
| {I1} |
6 |
| {I2} |
7 |
| {I3} |
6 |
| {I4} |
2 |
| {I5} |
2 |
支持度计数就是该项集在9个事务中出现的次数(该项集为各事务项集的子集)。
②各支持度计数与最小支持度计数比较,得到频繁1-项集L1。
频繁1-项集L1
| L1 |
|
| 项集 |
支持度计数 |
| {I1} |
6 |
| {I2} |
7 |
| {I3} |
6 |
| {I4} |
2 |
| {I5} |
2 |
⑵第二次扫描
主要目的是找到频繁2-项集。
①L1执行连接操作L1⋈L1,产生候选2-项集C2'。
连接操作就是L1中的各项集按照字典顺序进行组合,且每个新组合项集的项个数比原先多1个。L1连接操作形成的候选项集C2’如下表:
| C2’ |
| 项集 |
| {I1, I2} |
| {I1, I3} |
| {I1, I4} |
| {I1, I5} |
| {I2, I3} |
| {I2, I4} |
| {I2, I5} |
| {I3, I4} |
| {I3, I5} |
| {I4, I5} |
②对C2'进行剪枝操作:这一步的目的是压缩C2’,减少计算量,最终得到候选2-项集C2。
剪枝操作的理论基础是所谓的Apriori性质(先验性质):
任何非频繁的(k-1)项集都不可能是频繁k项集的子集。
也就是说,如果一个候选k项集的(k-1)项子集不在L(k-1)中,则该候选k项集不可能是频繁的,从而可以从候选k项集Ck中删除。
在这里,对C2’中各项集的1项子集,判断是否在频繁1-项集L1中,很显然都在,所以C2中没有项集在剪枝步中被删除。
计算剪枝后的项集C2及其支持度:
| C2 |
|
| 项集 |
支持度计数 |
| {I1, I2} |
4 |
| {I1, I3} |
4 |
| {I1, I4} |
1 |
| {I1, I5} |
2 |
| {I2, I3} |
4 |
| {I2, I4} |
2 |
| {I2, I5} |
2 |
| {I3, I4} |
0 |
| {I3, I5} |
1 |
| {I4, I5} |
0 |
③C2各项集支持度计数与最小支持度计数比较,删除小于最小支持度计数的项集,得到频繁2-项集L2。
| L2 |
|
| 项集 |
支持度计数 |
| {I1, I2} |
4 |
| {I1, I3} |
4 |
| {I1, I5} |
2 |
| {I2, I3} |
4 |
| {I2, I4} |
2 |
| {I2, I5} |
2 |
⑶第三次扫描
主要目的是获得频繁3-项集。
①连接操作:L2⋈L2,产生候选3-项集C3’。
| C3’ |
| 项集 |
| {I1, I2, I3} |
| {I1, I2, I5} |
| {I1, I3, I5} |
| {I2, I3, I4} |
| {I2, I3, I5} |
| {I2, I4, I5} |
②剪枝操作:使用先验性质,检验各候选3-项集的所有2项子集是否为2-频繁项集。经检查,C3’中{I1, I3, I5}、{I2, I3, I4}、{I2, I3, I5}、{I2, I4, I5}不满足先验性质,删除后得到项集C3,并计算剩下项集的支持度计数。
| C3 |
|
| 项集 |
支持度计数 |
| {I1, I2, I3} |
2 |
| {I1, I2, I5} |
2 |
③C3各项集支持度计数与最小支持度计数比较,得到频繁3-项集L3。
| L3 |
|
| 项集 |
支持度计数 |
| {I1, I2, I3} |
2 |
| {I1, I2, I5} |
2 |
⑷第四次扫描
①连接操作:![]()
②剪枝操作:连接产生的项集其子集{I2, I3, I5}不是频繁项集,所以![]() 被删除,C4=∅ 。于是算法终止,找出了所有的频繁项集L3。
被删除,C4=∅ 。于是算法终止,找出了所有的频繁项集L3。
总结一下,挖掘频繁项集的过程:
1.初始化扫描
2.循环扫描——连接、剪枝
3.直至候选项集为空集,程序终止。