【数据挖掘】Apriori算法初步应用
其他
2020-02-10 11:18:01
阅读次数: 0
说在前面
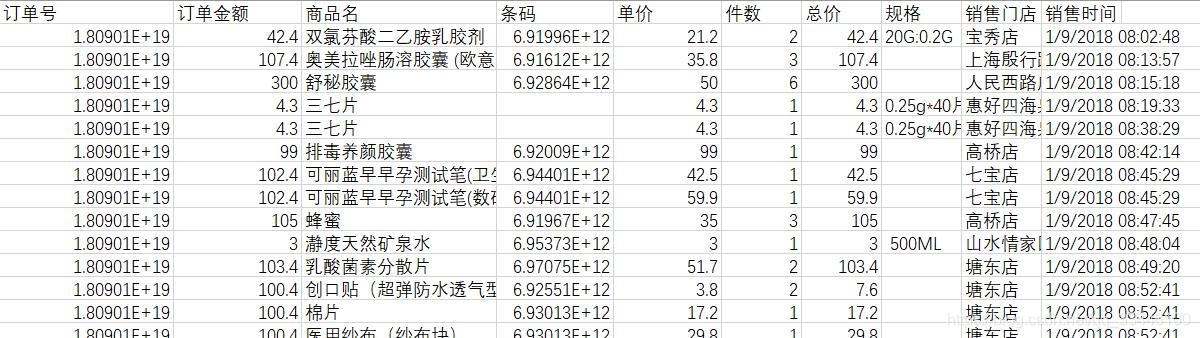
数据处理
python code
- 相关库
pip install pandas
pip install mlxtend
- 代码
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
def getData(path):
nlist = []
index=0
with open(path,"r",encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
line_elems = line.split(';')
nlist_elem=[]
for i in line_elems:
if i[0] != ' ':
nlist_elem.append(i.strip().split(' ')[0])
nlist.append(nlist_elem)
return nlist
shopping_list = getData("file.txt")
te = TransactionEncoder()
df_tf = te.fit_transform(shopping_list)
df = pd.DataFrame(df_tf, columns=te.columns_)
print(df)
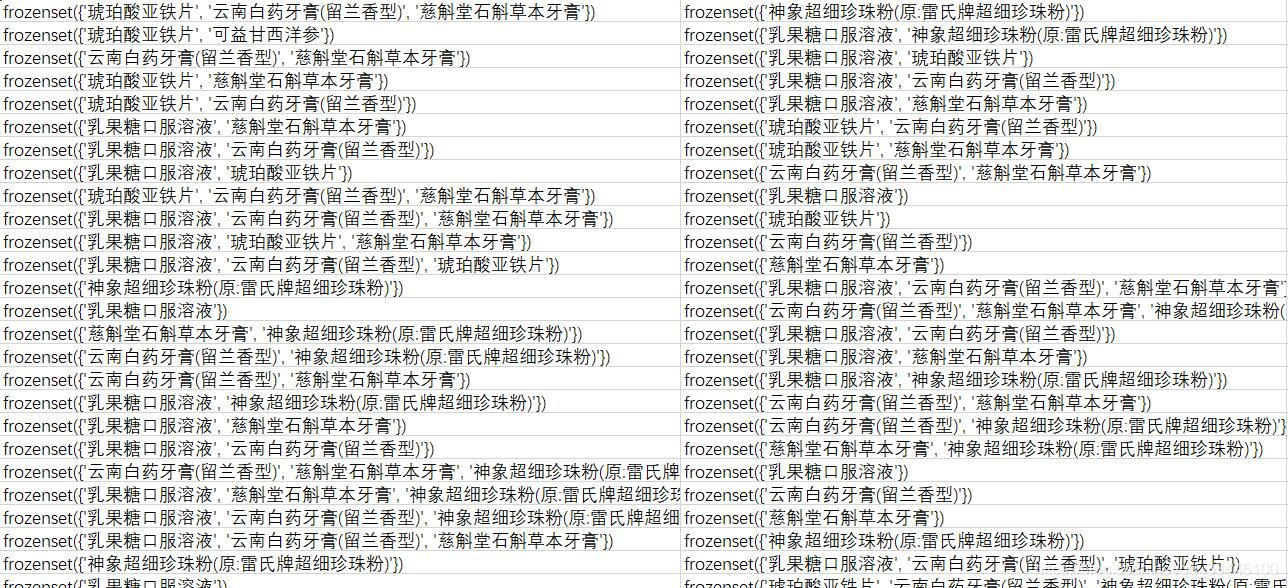
frequent_itemsets = apriori(df, min_support=0.003, use_colnames=True)
frequent_itemsets.sort_values(by='support', ascending=False, inplace=True)
print(frequent_itemsets)
rules = association_rules(frequent_itemsets,metric='confidence',min_threshold=0.9)
rules.sort_values(by='confidence', ascending=False, inplace=True)
print(rules)
rules.to_csv('test.csv', encoding='gbk')
- 结果
这个数据集不是很好,可能还需要预处理一下,,,,
发布了106 篇原创文章 ·
获赞 41 ·
访问量 4万+
转载自blog.csdn.net/qq_33446100/article/details/101713206