数据挖掘算法Apriori算法的实现
1.算法简介
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
2主要概念
1.关联规则
就是发现数据和某种规则背后的某种规则和联系
2.支持度
一个项集(规则)在总体中所占的比例
3.可信度(置信度)
购买X的人同时又购买Y的概率
2.算法的实现
1.实验数据集
T1,鱼,熟食,水果
T2,水果,净菜,鱼
T3,家禽,水果,油,调味料,净菜
T4,家禽,熟食,油,净菜
T5,家禽,水果,蔬菜,调味料
T6,熟食,鱼,蔬菜,油
T7,熟食,蔬菜,调味料
T8,油,蔬菜,调味料,净菜
T9,蔬菜,水果,净菜,鱼
T10,水果,调味料,油,调味料,水果
T11,家禽,净菜,油,调味料,水果
T12,熟食,水果,蔬菜
2.实验代码
/*
*apriori算法的缺点:
*
* 其次要一直迭代重复的扫描事物数据来计算支持度。导致效率会比较低下
*/
import java.util.*;
import java.io.*;
public class DataDeal {
static double min_support = 2;
static double min_confident = 0.5;
//文件路径
static String filePath = System.getProperty("user.dir") + "\\testData\\data.txt";
static ArrayList<ArrayList<String>> D = new ArrayList<ArrayList<String>>();//事务数据库D
static HashMap<ArrayList<String>, Integer> C = new HashMap<ArrayList<String>, Integer>();//项目集C
static HashMap<ArrayList<String>, Integer> L = new HashMap<ArrayList<String>, Integer>();//候选集L
// 用于存取候选集每次计算结果(即存放所有的频繁项集L),最后计算关联规则,就不用再次遍历事务数据库。
static HashMap<ArrayList<String>, Integer> L_ALL = new HashMap<ArrayList<String>, Integer>();
//从文件中读取内容,返回事务集
public static ArrayList<ArrayList<String>> readTable(String filePath){
ArrayList<ArrayList<String>> t = new ArrayList<ArrayList<String>>();
ArrayList<String> t1 = null;
File file = new File(filePath);
try {
InputStreamReader isr = new InputStreamReader(new FileInputStream(file));
BufferedReader bf = new BufferedReader(isr);
String str = null;
while((str = bf.readLine()) != null) {
t1 = new ArrayList<String>();
String[] str1 = str.split(",");
for(int i = 1; i < str1.length ; i++) {
t1.add(str1[i]);
}
t.add(t1);
}
bf.close();
isr.close();
} catch (Exception e) {
e.printStackTrace();
System.out.println("文件不存在!");
}
System.out.println("\nD:"+t);
return t;
}
//剪枝步:从候选集C中删除小于最小支持度的,并放入频繁集L中
public static void pruning(HashMap<ArrayList<String>, Integer> C,HashMap<ArrayList<String>, Integer> L) {
L.clear();
// 根据项目集生成候选集
L.putAll(C);
// 删除少于最小支持度的元素
ArrayList<ArrayList<String>> delete_key = new ArrayList<ArrayList<String>>();
for (ArrayList<String> key : L.keySet()) {
if (L.get(key) < min_support) {
delete_key.add(key);
}
}
for (int i = 0; i < delete_key.size(); i++) {
L.remove(delete_key.get(i));
}
}
/**
* 初始化事务数据库、项目集、候选集
*/
public static void init() {
//将文件中的数据放入集合D中
D = readTable(filePath);
// 扫描事务数据库。生成项目集,支持度=该元素在事务数据库出现的次数/事务数据库的事务数
for (int i = 0; i < D.size(); i++) {
for (int j = 0; j < D.get(i).size(); j++) {
String[] e = { D.get(i).get(j) };
//将数组e转化为List
ArrayList<String> item = new ArrayList<String>(Arrays.asList(e));
//map中是否包含指定的键
if (!C.containsKey(item)) {
C.put(item, 1);
//System.out.println(C.get(item));
} else {
C.put(item, C.get(item) + 1);
//System.out.println(C.get(item));
}
}
}
//System.out.println("D.size= "+D.size());
pruning(C, L);// 剪枝
//将频繁项集放入集合中
L_ALL.putAll(L);
}
// 两个整数集求并集
public static ArrayList<String> arrayListUnion(ArrayList<String> arraylist1, ArrayList<String> arraylist2) {
ArrayList<String> arraylist = new ArrayList<String>();
arraylist.addAll(arraylist1);
arraylist.addAll(arraylist2);
//将ArrayList转化为HashSet去掉重复元素,再将HashSet转换为ArrayList
arraylist = new ArrayList<String>(new HashSet<String>(arraylist));
return arraylist;
}
/**
* 迭代求出最终的候选频繁集
*
* @param C
* 完成初始化的项目集
* @param L
* 完成初始化的候选集
* @return 最终的候选频繁集
*/
public static HashMap<ArrayList<String>, Integer> iteration(HashMap<ArrayList<String>, Integer> C,HashMap<ArrayList<String>, Integer> L) {
HashMap<ArrayList<String>, Integer> L_temp = new HashMap<ArrayList<String>, Integer>();// 用于判断是否结束剪枝的临时变量
String str = null;
int t = 1;// 迭代次数
while (L.size() > 0) {// 一旦被剪枝后剪干净,剪枝之前则是最终要求的结果。
t++;
L_temp.clear();
L_temp.putAll(L);
// 一、连接步
C.clear();
// 1.将L中的项以一定的规则两两匹配
ArrayList<ArrayList<String>> L_key = new ArrayList<ArrayList<String>>(L.keySet());
for (int i = 0; i < L_key.size(); i++) {
for (int j = i + 1; j < L_key.size(); j++) {
ArrayList<String> C_item = new ArrayList<String>();
C_item = new ArrayList<String>(arrayListUnion(L_key.get(i),
L_key.get(j)));
if (C_item.size() == t) {
C.put(C_item, 0);
// 频繁项集的所有非空子集都必须是频繁的
}
}
}
// 2.通过扫描D,计算此项的支持度
for (ArrayList<String> key : C.keySet()) {
for (int i = 0; i < D.size(); i++) {
if (D.get(i).containsAll(key)) {
C.put(key, C.get(key) + 1 );
}
}
}
str = C.toString();
System.out.println("候选"+t+"项集:C: \n"+C);
// 二、剪枝步
pruning(C, L);
System.out.println("频繁"+t+"项集:L: \n"+L+"\n");
str = L.toString();
//System.out.println("===");
L_ALL.putAll(L);
}
return L_temp;
}
// 求一个集合的所有子集
public static ArrayList<ArrayList<String>> getSubset(ArrayList<String> L) {
if (L.size() > 0) {
ArrayList<ArrayList<String>> result = new ArrayList<ArrayList<String>>();
for (int i = 0; i < Math.pow(2, L.size()); i++) {// 集合子集个数=2的该集合长度的乘方
ArrayList<String> subSet = new ArrayList<String>();
int index = i;// 索引从0一直到2的集合长度的乘方-1
for (int j = 0; j < L.size(); j++) {
// 通过逐一位移,判断索引那一位是1,如果是,再添加此项
if ((index & 1) == 1) {// 位与运算,判断最后一位是否为1
subSet.add(L.get(j));
}
index >>= 1;// 索引右移一位
}
result.add(subSet); // 把子集存储起来
}
return result;
} else {
return null;
}
}
// 判断两个集合相交是否为空
public static boolean intersectionIsNull(ArrayList<String> l1,
ArrayList<String> l2) {
Set<String> s1 = new HashSet<String>(l1);
Set<String> s2 = new HashSet<String>(l2);
s1.retainAll(s2);
if (s1.size() > 0) {
return false;
} else {
return true;
}
}
/**
* 根据最终的关联集,根据公式计算出各个关联事件
*/
public static void connection() {
for (ArrayList<String> key : L_ALL.keySet()) {// 对最终的关联集各个事件进行判断
ArrayList<ArrayList<String>> key_allSubset = getSubset(key);
//得到所有频繁集中每个集合的子集
//System.out.println(key_allSubset);
for (int i = 0; i < key_allSubset.size(); i++) {
//得到一个真子集
ArrayList<String> item_pre = key_allSubset.get(i);
if (0 < item_pre.size() && item_pre.size() < key.size()) {// 判断是否是非空真子集
// 各个非空互补真子集之间形成关联事件
double item_pre_support = L_ALL.get(item_pre);//得到真子集的支持度度
//System.out.println("itempre="+item_pre_support);
for (int j = 0; j < key_allSubset.size(); j++) {
ArrayList<String> item_post = key_allSubset.get(j);
if (0 < item_post.size()
&& item_post.size() < key.size()
&& arrayListUnion(item_pre, item_post).equals(key)
&& intersectionIsNull(item_pre, item_post))
//不相交的两个非空真子集,相并为频繁项集
{
double d = L_ALL.get(arrayListUnion(item_pre, item_post));
double item_post_support = L_ALL.get(item_post);// 互补真子集的支持度比则是事件的置信度
//System.out.println("item_post="+item_post_support);
double confident = d;
//item_pre_support;
// 事件的置信度
if (confident > min_confident) {// 如果事件的置信度大于最小置信度
System.out.print(item_pre + "==>" + item_post );// 则是一个关联事件
System.out.println("==>" + confident);
}
}
}
}
}
}
}
public static void main(String[] args) {
DataDeal apriori = new DataDeal();
apriori.init();
System.out.println("候选项集:C:\n"+apriori.C);
System.out.println("频繁项集:L:\n"+apriori.L+"\n");
apriori.L = apriori.iteration(apriori.C, apriori.L);
System.out.println("关联规则如下:");
apriori.connection();
}
}
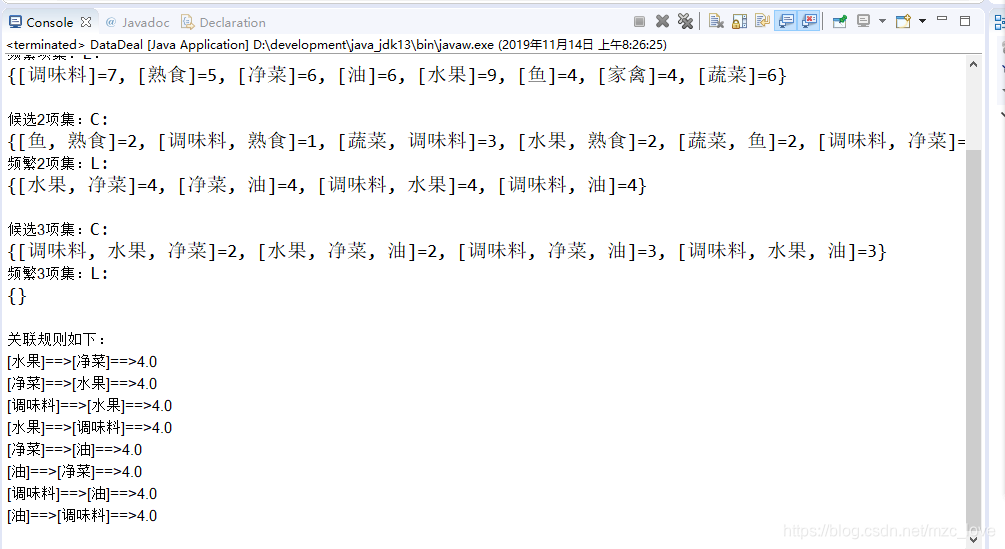
3.运行截图展示
设置最小支持度和可信度
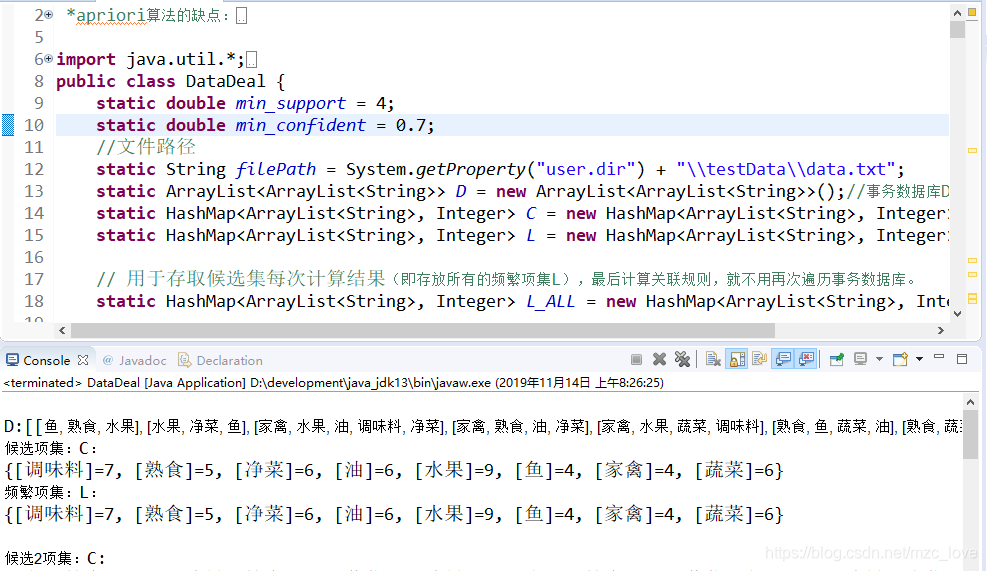
运行结果